主要指对抗生成网络。
2个主要构成:判别器、生成器
判别模型尽可能提取特征正确率增加的模型,生成模型尽可能“伪造”让判别模型以为是真的结果。
来源于“heterostatic theory of adaptive systems”
不同于监督学习和非监督学习,强化学习不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数 [3] 。
2个核心:
顾名思义,向量形式的搜索。
index:将普通搜索的query和文档库中的文档,都用向量表示。
query:完成向量的匹配(相似度计算)过程。
得到向量的过程,可使用word2vec、fasttext、glove等,也可使用公开的词向量模型。腾讯、百度、Google都有公开。
常用于会话系统中,用来识别用户的意图,给系统下一步的操作提供依据。
一个是意图的识别,一个是槽位的识别。
本质就是一个分类问题,可以用基于规则,传统机器学习算法 (SVM),基于深度学习算法(CNN, LSTM, RCNN, C-LSTM, FastText)等方法来处理。
情感分析的任务是从评论的文本中提取出评论的实体,以及评论者对该实体所表达的情感倾向。
用于电商网站对某款产品的用户反馈情绪提取。
抽取情感相关的词汇,和词典中的数据进行比较,最终计算得分。
可基于词语来做,也可将整个句子标注,用来训练深度神经网络的情感分类模型。
情感分析 ChnSentiCorp,SST-2,和 LCQMC
一般为单句分析
计算两个文本之间的相关程度。
可以是基于字符层面的计算,例如编辑距离、Jaccard距离等;
也可以是基于语义层面的,先得到词语/字的语义向量,然后计算文本的语义向量,最终计算两个向量之间的距离。方法有:cos、dot
Attention用的是另外一种计算矩阵相似度的方法,这里不讨论。
目前的算法和技术能做到的:将结构化的数据,转为非结构化的文本。
根据商品信息,生成营销类的标题和宣传广告。是基于规则模板匹配和语义标注训练相结合的方法。有大量的标注训练数据。
“李文哲:目前NLP不适合文本生成,只能用在论文里面”
将知识用图结构的方式表达出来。图数据库。
常用的工具neo4j、ArangoDB、OrientDB、TigerGraph
端到端,是一种方法、一种思路,在Seq2Seq基础之上,完成序列到序列的映射关系。
可以做语音识别、机器翻译、命名实体识别、关系抽取等任务。
用户只需关注输入和输出部分,无需在意具体的映射逻辑,可以看做是一个黑盒子。
端到端的学习其实就是不做其他额外处理,从【原始数据输入】到【任务结果输出】,整个训练和预测过程,都是在模型里完成的。
自动驾驶:像素---指令
语音识别:声音---文本
机器翻译:文本---文本
智能会话:文本---文本
问答系统:文本---文本
一般来讲,输入和输出的长度相对固定,且格式一致。数据量在10万以上。
研究工作的主要内容:给定一段文本、一个问题和多个候选集,找出正确的那个候选集。并且,答案一定出现在段落中。
数据格式SQuAD。台湾有繁体版,有对应的简体版。
人和机器之间的对话
下图是阿里的达摩院分享的内容,我做了笔记和整理。
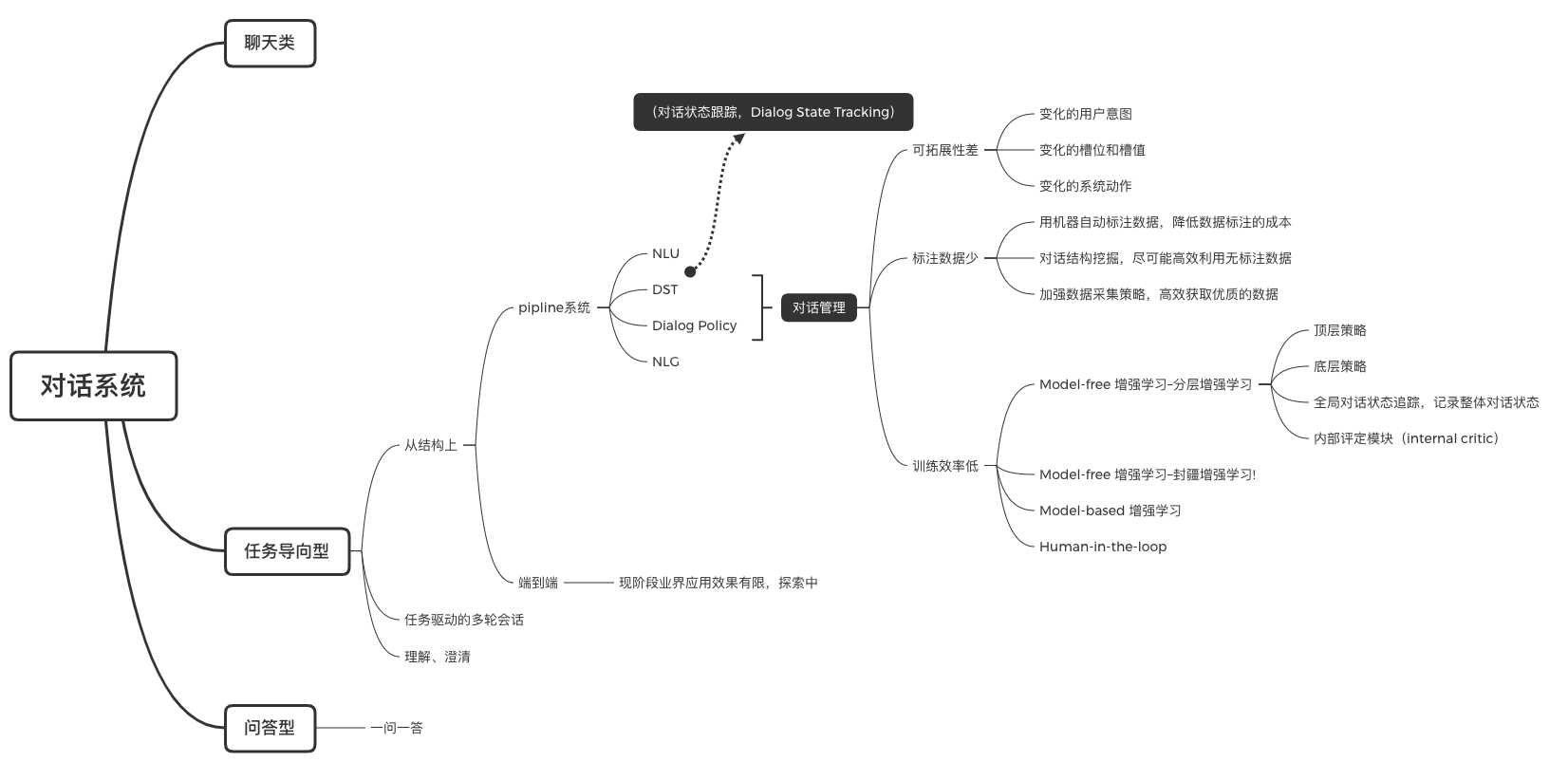
为了完成一个特定的任务,人和机器之间的多次交互。
以完成任务为目的。
多轮会话中,包含意图的澄清、确认等。
能运行跑起来的应用,都是基础的填槽方式。
基于深度学习的方法,目前停留在实验阶段。
这是从研究工作工作的角度,看待的“问答系统”
一问一答。
人类一次提问,机器一次回答,交互完成。
在实际工作中,不同岗位理解的问答系统不一样。
例如:在知识类的网站中,知乎、悟空问答、各种论坛,都可以看做是问答系统。
关于深度学习的问答系统,保险领域常用的数据集是https://github.com/shuzi/insuranceQA.git ,这是一问一答的方式,原版是英文版的,已有中文版本。
生物医疗领域的问答系统,BioASQ
BERT模型做的问答系统,一般基于三元组<上下文,问题,答案>
NLPCC2016-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是从候选中找到合适的文档作为问题的答案。[链接: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf].
http://www.crownpku.com/2017/07/27/用Rasa_NLU构建自己的中文NLU系统.html
我们推荐使用下面的pipeline:
MITIE+Jieba+sklearn (sample_configs/config_jieba_mitie_sklearn.json):
[“nlp_mitie”, “tokenizer_jieba”, “ner_mitie”, “ner_synonyms”, “intent_featurizer_mitie”, “intent_classifier_sklearn”]
这里也可以看到Rasa NLU的工作流程。”nlp_mitie”初始化MITIE,”tokenizer_jieba”用jieba来做分词,”ner_mitie”和”ner_synonyms”做实体识别,”intent_featurizer_mitie”为意图识别做特征提取,”intent_classifier_sklearn”使用sklearn做意图识别的分类。
https://www.milvus.io/
https://github.com/PaddlePaddle/ERNIE
https://github.com/RasaHQ/rasa
原文:https://www.cnblogs.com/xuehuiping/p/12344485.html