kafka由LinkedIn公司开发,在2011年开源。Apache Kafka 是基于Scala语言开发的一款基于发布与订阅的消息系统 ,它将数据分区保存,并将每个分区保存成多份以提高可用性。
kafka和其他分布式服务一样,满足CAP理论:Consistency一致性、Availability 可用性、partition tolerance 分区容错性。kafka的特点如下:
1、高性能:相比于MQ消息队列,kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
2、高扩展性:数据经分片后写入集群节点,解决了单个节点数据存储和处理的局限
3、数据持久性:数据消息会持久化到本地磁盘,通过多副本策略防止数据丢失,kafka采用了顺序写、顺序读和批量写等机制,提升工作效率
4、高并发: 支持数千个客户端同时读写
5、容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
日志收集系统:kafka可与Flume和Logstash组合使用,作为source或sink的角色。最终将数据存储到分布式文件系统中, 例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和storm,这是Kafka 0.10后新增的能力(Kafka Streams)
每家公司起初业务简单,通常只需要一条数据流水线,从前端服务上收集日志,然后直接存储在后端的存储系统中进行分析,随着业务的不断发展,业务逻辑变得复杂,业务数据量增大,需要增加多条流水线将收集到的数据存储到不同的存储服务和分析系统中。如果仍然使用之前的数据收集模式,则会产生以下问题:
1、数据的生产者和消费者耦合度过高:当业务需要增加一个新的消费者时,所有生产者均需要做调整,使的扩展非常不灵活
2、生产者和消费者之间处理数据速率不对等:如果生产者产生数据过快,可能导致消费者的压力过大,甚至崩溃
3、并发的网络连接对后端消费者不友好:
(1)大量的生产者直接与消费者通信,对消费者造成多大的网络连接压力,成为系统扩展中的潜在瓶颈
(2)大量并发的生产者同时写入后端存储,可能产生大量小文件。对hadoop这样的分布式文件系统造成很大存储压力(HDFS不适合存储大量小文件)
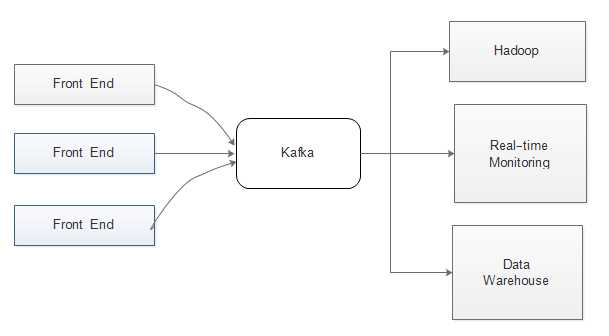
kafka的引入正好可以解决以上问题:降低数据生产者(Web Server)和消费者(Hadoop集群、监控系统)的耦合性,使系统更容易扩展。如图:
1、架构方面
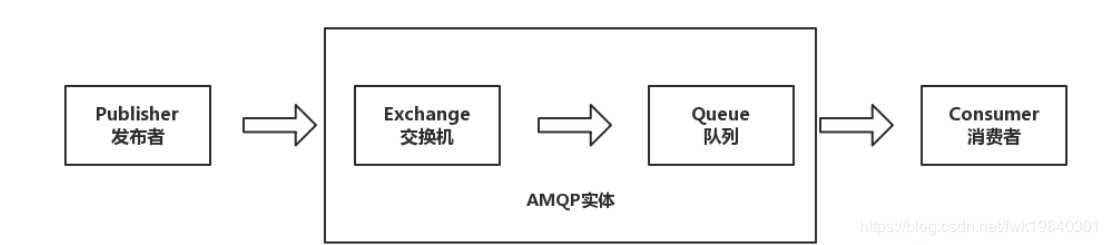
ZeroMQ、RabbitMQ等采用AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是一个进程间传递异步消息的网络协议
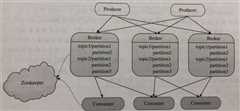
kafka的架构
2、producer、Broker与Consumer交互方式不同
RabbitMQ 采用push-push的方式,即Producer直接push数据给Broker,Broker在push数据给Consumer
kafka采用push-pull的方式,即Producer直接push数据给Broker,Consumer从Brokerpull数据
kafka采用这种机制的优点有:
(1)Consumer可以根据自身的负载和需求获取数据,避免“push”方式带来的压力
(2)Consumer可以自己维护已读取消息的offset,而不是由Broker端维护,缓解了Broker的压力
3、在集群负载均衡方面,
rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
kafka采用zookeeper对集群中的broker、consumer进行管理
4、使用场景
rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。金融场景中经常使用
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度(与分区上的存储大小无关),消息处理的效率很高。用于大数据领域
原文:https://www.cnblogs.com/zh-dream/p/12163837.html