本文代码已上传至git和百度网盘,链接分享在文末
网站概览

目标,使用scrapy框架抓取全部图片并分类保存到本地。
1.创建scrapy项目
scrapy startproject images
2.创建spider
cd images
scrapy genspider mn52 www.mn52.com
创建后结构目录如下
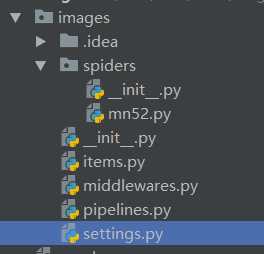
3.定义item定义爬取字段
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ImagesItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() image_url = scrapy.Field() field_name = scrapy.Field() detail_name = scrapy.Field()
这里定义三个字段,分别为图片地址,图片类别名称和图片详细类别名称
4.编写spider
# -*- coding: utf-8 -*- import scrapy import requests from lxml import etree from images.items import ImagesItem class Mn52Spider(scrapy.Spider): name = ‘mn52‘ # allowed_domains = [‘www.mn52.com‘] # start_urls = [‘http://www.mn52.com/‘] def start_requests(self): response = requests.get(‘https://www.mn52.com/‘) result = etree.HTML(response.text) li_lists = result.xpath(‘//*[@id="bs-example-navbar-collapse-2"]/div/ul/li‘) for li in li_lists: url = li.xpath(‘./a/@href‘)[0] field_name = li.xpath(‘./a/text()‘)[0] print(‘https://www.mn52.com‘ + url,field_name) yield scrapy.Request(‘https://www.mn52.com‘ + url,meta={‘field_name‘:field_name},callback=self.parse) def parse(self, response): field_name = response.meta[‘field_name‘] div_lists = response.xpath(‘/html/body/section/div/div[1]/div[2]/div‘) for div_list in div_lists: detail_urls = div_list.xpath(‘./div/a/@href‘).extract_first() detail_name = div_list.xpath(‘./div/a/@title‘).extract_first() yield scrapy.Request(url=‘https:‘ + detail_urls,callback=self.get_image,meta={‘detail_name‘:detail_name,‘field_name‘:field_name}) url_lists = response.xpath(‘/html/body/section/div/div[3]/div/div/nav/ul/li‘) for url_list in url_lists: next_url = url_list.xpath(‘./a/@href‘).extract_first() if next_url: yield scrapy.Request(url=‘https:‘ + next_url,callback=self.parse,meta=response.meta) def get_image(self,response): field_name = response.meta[‘field_name‘] image_urls = response.xpath(‘//*[@id="originalpic"]/img/@src‘).extract() for image_url in image_urls: item = ImagesItem() item[‘image_url‘] = ‘https:‘ + image_url item[‘field_name‘] = field_name item[‘detail_name‘] = response.meta[‘detail_name‘] # print(item[‘image_url‘],item[‘field_name‘],item[‘detail_name‘]) yield item
逻辑思路:spider中重写start_requests获取起始路由,这里起始路由设为图片的一级分类如性感美女,清纯美女,萌宠图片等的地址,使用requests库请求mn52.com来解析获取。然后把url和一级分类名称传递给parse,在parse中解析获取图片的二级分类地址和二级分类名称,并判断是否含有下一页信息,这里使用scrapy框架自动去重原理,所以不用再写去重逻辑。获取到的数据传递给get_image,在get_image中解析出图片路由并赋值到item字段中然后yield item.
5.pipelines管道文件下载图片
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import scrapy import os # 导入scrapy 框架里的 管道文件的里的图像 图像处理的专用管道文件 from scrapy.pipelines.images import ImagesPipeline # 导入图片路径名称 from images.settings import IMAGES_STORE as images_store class Image_down(ImagesPipeline): def get_media_requests(self, item, info): yield scrapy.Request(url=item[‘image_url‘]) def item_completed(self, results, item, info): print(results) image_url = item[‘image_url‘] image_name = image_url.split(‘/‘)[-1] old_name_list = [x[‘path‘] for t, x in results if t] # 真正的原图片的存储路径 old_name = images_store + old_name_list[0] image_path = images_store + item[‘field_name‘] + ‘/‘ + item[‘detail_name‘] + ‘/‘ # 判断图片存放的目录是否存在 if not os.path.exists(image_path): # 根据当前页码创建对应的目录 os.makedirs(image_path) # 新名称 new_name = image_path + image_name # 重命名 os.rename(old_name, new_name) return item
分析:scrapy内置的ImagesPipeline自己生成经过md5加密的图片名称,这里导入os模块来使图片下载到自定义的文件夹和名称,需要继承ImagesPipeline类。
6.settings中设置所需参数(部分)
#USER_AGENT = ‘images (+http://www.yourdomain.com)‘ USER_AGENT = ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36‘ #指定输出某一种日志信息 LOG_LEVEL = ‘ERROR‘ #将日志信息存储到指定文件中,不在终端输出 LOG_FILE = ‘log.txt‘ # Obey robots.txt rules ROBOTSTXT_OBEY = False IMAGES_STORE = ‘./mn52/‘ ITEM_PIPELINES = { # ‘images.pipelines.ImagesPipeline‘: 300, ‘images.pipelines.Image_down‘: 301, }
说明:settings中主要定义了图片的存储路径,user_agent信息,打开下载管道。
7.创建crawl.py文件,运行爬虫
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # mn52是爬虫名 process.crawl(‘mn52‘) process.start()
这里没有使用cmdline方法运行程序,因为涉及到后面的打包问题,使用cmdline方法无法打包。
8.至此,scrapy爬虫已编写完毕,右键运行crawl文件启动爬虫,图片就会下载。
控制台输出:
打开文件夹查看图片
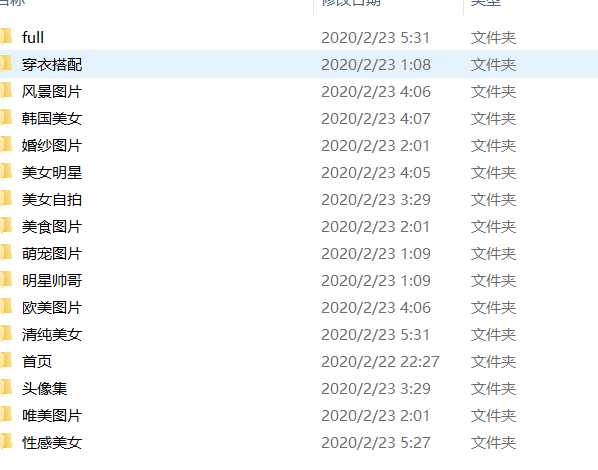
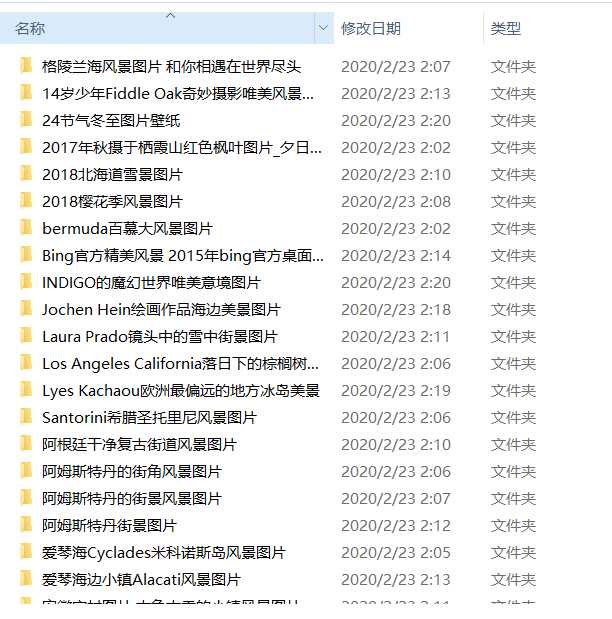
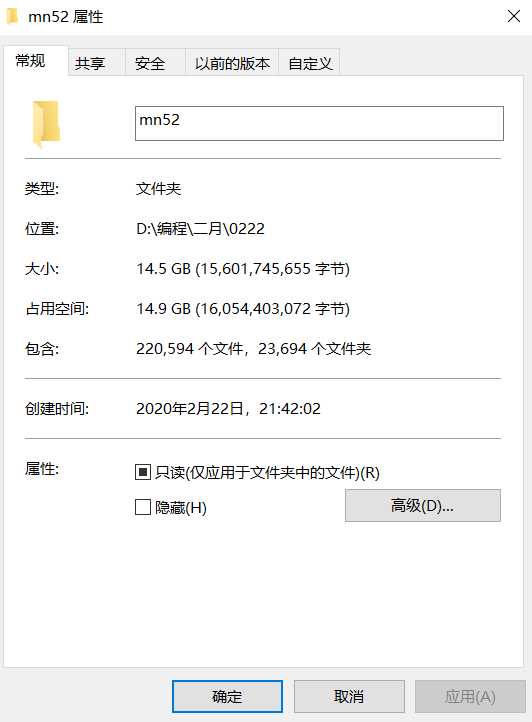
全站下载完成的话大概有22万张图片
9.打包scrapy爬虫。
scrapy爬虫作为一个框架爬虫也是可以被打包成exe文件的,是不是很神奇/??
打包步骤:
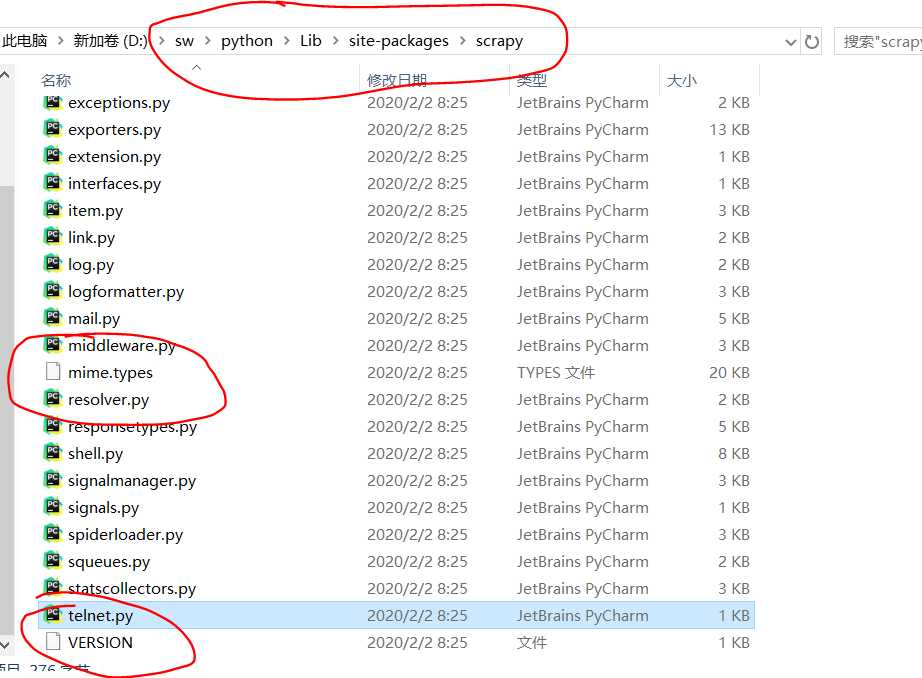
1>在你的python安装目录下找到scrapy复制其中的mime.types和VERSION文件到项目目录下,一般路径如下
2>在项目下创建generate_cfg.py文件,用来生成scrapy.cfg
data = ‘‘‘ [settings] default = images.settings [deploy] # url = http://localhost:6800/ project = images ‘‘‘ with open(‘scrapy.cfg‘, ‘w‘) as f: f.write(data)
完成后项目结构如下
3>crawl.py文件内引入项目所需的库
import scrapy.spiderloader import scrapy.statscollectors import scrapy.logformatter import scrapy.dupefilters import scrapy.squeues import scrapy.extensions.spiderstate import scrapy.extensions.corestats import scrapy.extensions.telnet import scrapy.extensions.logstats import scrapy.extensions.memusage import scrapy.extensions.memdebug import scrapy.extensions.feedexport import scrapy.extensions.closespider import scrapy.extensions.debug import scrapy.extensions.httpcache import scrapy.extensions.statsmailer import scrapy.extensions.throttle import scrapy.core.scheduler import scrapy.core.engine import scrapy.core.scraper import scrapy.core.spidermw import scrapy.core.downloader import scrapy.downloadermiddlewares.stats import scrapy.downloadermiddlewares.httpcache import scrapy.downloadermiddlewares.cookies import scrapy.downloadermiddlewares.useragent import scrapy.downloadermiddlewares.httpproxy import scrapy.downloadermiddlewares.ajaxcrawl import scrapy.downloadermiddlewares.chunked import scrapy.downloadermiddlewares.decompression import scrapy.downloadermiddlewares.defaultheaders import scrapy.downloadermiddlewares.downloadtimeout import scrapy.downloadermiddlewares.httpauth import scrapy.downloadermiddlewares.httpcompression import scrapy.downloadermiddlewares.redirect import scrapy.downloadermiddlewares.retry import scrapy.downloadermiddlewares.robotstxt import os import scrapy.spidermiddlewares.depth import scrapy.spidermiddlewares.httperror import scrapy.spidermiddlewares.offsite import scrapy.spidermiddlewares.referer import scrapy.spidermiddlewares.urllength from scrapy.pipelines.images import ImagesPipeline import scrapy.pipelines from images.settings import IMAGES_STORE as images_store import scrapy.core.downloader.handlers.http import scrapy.core.downloader.contextfactory import requests from lxml import etree from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # mn52是爬虫名 process.crawl(‘mn52‘) process.start()
10.使用pyinstaller第三方打包库打包
如果没有安装的话使用pip安装
pip install pyinstaller
在项目下使用打包命令
pyinstaller -F --add-data=mime.types;scrapy --add-data=VERSION;scrapy --add-data=images/*py;images --add-data=images/spiders/*.py;images/spiders --runtime-hook=generate_cfg.py crawl.py
一共用了4个--add-data命令以及1个--runtime-hook命令
第一个--add-data用来mime.types文件,添加后放在临时文件夹中的scrapy文件夹内,
第二个用来添加VERSION文件,添加后的文件同mime.types相同
第三个用来添加scrapy的代码——images文件夹下的所有py文件,*代表通配符
第四个用来添加scrapy的代码——mn52文件夹下的所有py文件
--runtime-hook用于添加运行钩子,也就是这里的generate_cfg.py文件
命令执行完毕后在dist文件夹内生成可执行文件,双击可执行文件,同路径下生成scrapy_cfg部署文件和mn52图片文件夹,运行么有问题

代码地址git:https://github.com/terroristhouse/crawler
exe可执行文件地址(无需python环境):
链接:https://pan.baidu.com/s/19TkeDY9EHMsFPULudOJRzw
提取码:8ell
python系列教程:
链接:https://pan.baidu.com/s/10eUCb1tD9GPuua5h_ERjHA
提取码:h0td
使用scrapy框架爬取mn52美女网站全站二十多万张图片,并打包成exe可执行文件
原文:https://www.cnblogs.com/nmsghgnv/p/12349117.html