提交请求和返回该请求的响应之间使用的时间,一般比较关注平均响应时间。
如:数据库查询花费的时间,将字符回显到终端上花费的时间,访问 Web 页面花费的时间;
指同一时刻,对服务器有实际交互的请求数。和网站在线用户数的关联。
对单位时间内完成的工作量(请求)的量度。
如:每分钟的数据库事务,每秒传送的文件千字节数,每分钟的 Web 服务器命中数
关系
通常,平均响应时间越短,系统吞吐量越大;平均响应时间越长,系统吞吐量越小。但是,系统吞吐量越大, 未必平均响应时间越短。

1、减少请求数;
a、合并css、合并js、合并图片等
b、http头中的keep-alive(现在浏览器都是默认开启,基本不需要操心)
2、使用客户端缓冲;
静态资源文件缓存在浏览器,通过Cache-Control和Expires
3、启用压缩
服务器端对资源进行压缩,客户端进行解压缩(但是会给服务器以及浏览器增加压力)
4、资源文件加载顺序
css放在页面最上面,js放在最下面
5、减少Cookie传输
静态页面不传输cookie信息
内容分发网络(图片、css、js等静态资源)
比如使用nginx,将静态资源放在nginx上面。
优先考虑使用缓存优化性能,缓存离用户越近越好。适用于读写比高的数据,也就是读多写少的场景,如果每秒数据都被更改,缓存就失去了意义,不仅数据时效性差,缓存的维护也浪费了资源。
1、缓存的基本原理、本质以及问题
频繁修改的数据,尽量不要缓存,读写比2:1以上;
缓存一定是热点数据;
应用就要容忍一定时间的数据不一致;
缓存可用性问题;
缓存预热;
缓存击穿:1、布隆过滤器;2、把不存在的数据也缓存起来({"key":null})
2、分布式缓存与一致性哈希
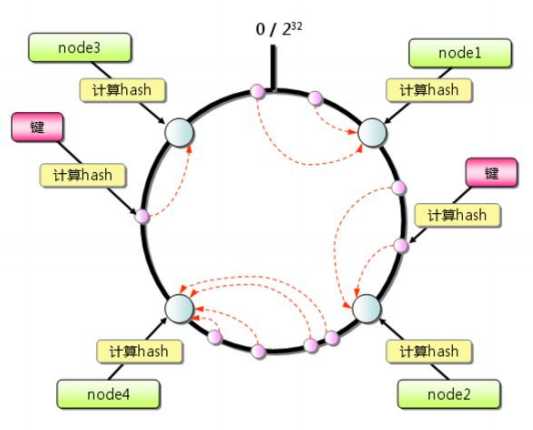
如果node4这个服务器挂了,那么数据会放到node3上。
1、同步、异步、阻塞、非阻塞
同步和异步关注的是结果消息的通信机制;
阻塞和非阻塞关注的是等待结果返回给调用方的状态。
2、解释
同步、异步:
1、代码级别
a、选择合适的数据结构
b、选择更优的算法
c、编写更少的代码
2、并发编程
a、充分利用CPU多核,尽量使用线程池,合理设置线程数量,尽量使用JDK 提供的各种并发框架和工具
b、实现线程安全的类,避免线程安全问题
c、同步下减少锁的竞争
3、资源的复用
减少开销很大的系统资源的创建和销毁
a、单例模式
b、池化技术
4、JVM
a、与JIT编译器相关的优化
b、GC调优
c、调优实战
尽量使用SSD
定时清理数据或者按数据的性质分开存放
结果集处理
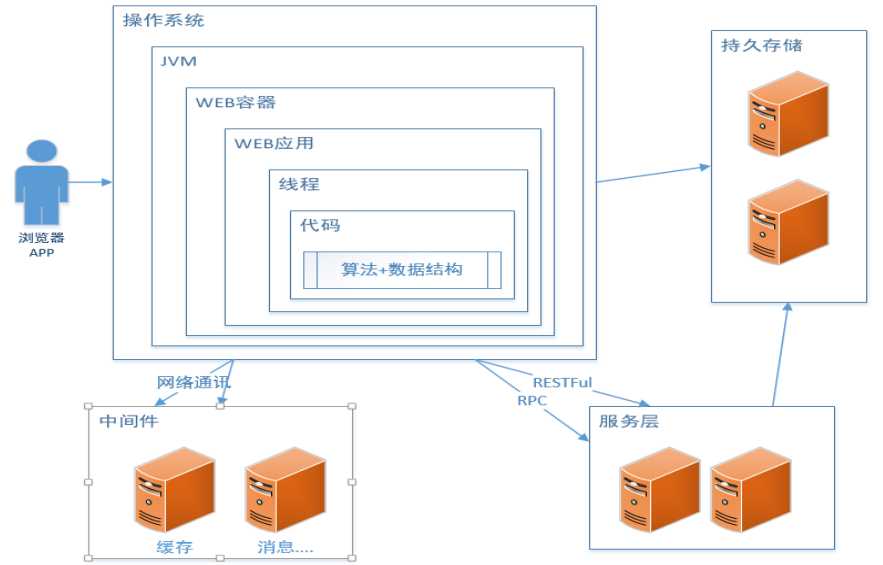
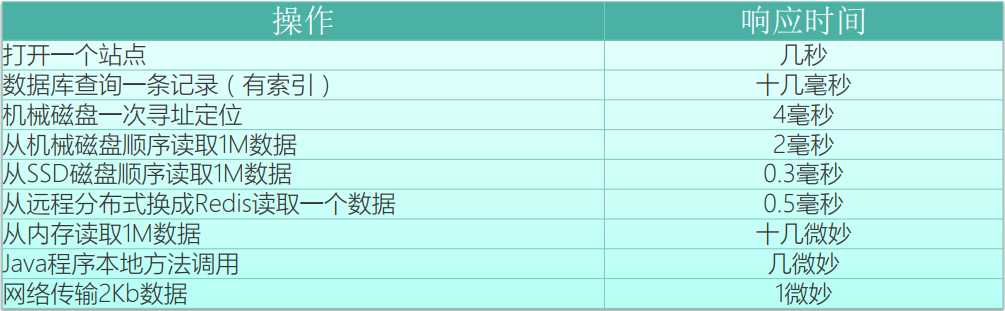
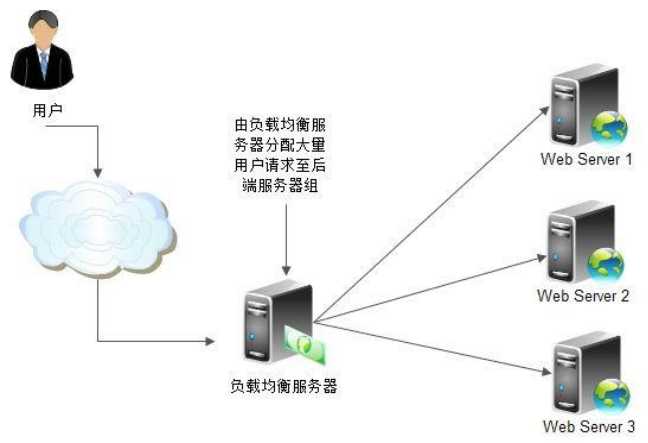
原文:https://www.cnblogs.com/alimayun/p/12352959.html