该篇文章主要阐述一个例子(例子来自参考资料,侵删),然后总结今天相关的知识点。
创建表并插入数据,并执行查询
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
mysql> select * from t where a between 10000 and 20000;

可以看到该语句查询使用到了索引,然后进行如下操作

下面的三条SQL语句,就是这个实验过程。
set long_query_time=0; select * from t where a between 10000 and 20000; /*Q1*/ select * from t force index(a) where a between 10000 and 20000;/*Q2*/
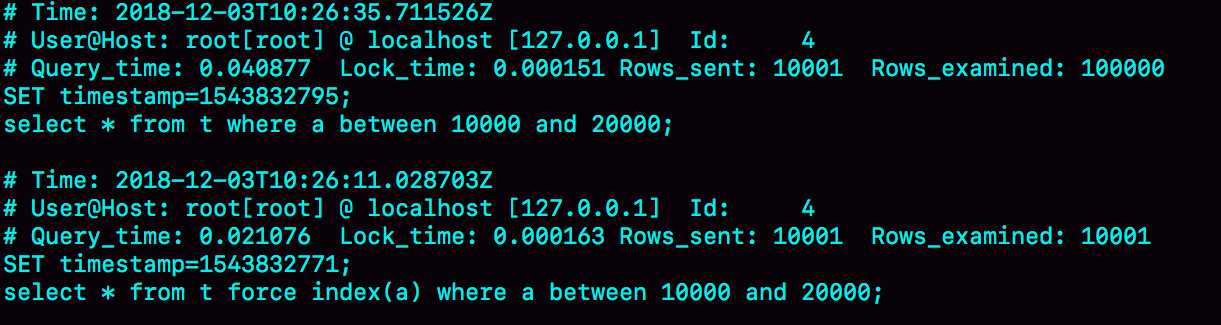
可以看到数据库确实选错了索引,我们要知道为什么选错了索引就要知道数据库是如何选择索引的。
我们从开始MySQL 架构图可以知道执行语句要经过一个优化器的组件,这个组件就相当于决策大脑,为语句选择合适的索引。
????一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。 而选择索引肯定看区分度高的索引,区分度高的索引能够准确找到符合条件的记录。思路如下 :
选择索引 -> 选择区分度高的索引 --> 如何找到区分度高的索引 --> 抽样统计算法
????我们可以使用show index方法,看到一个索引的基数。如图4所示,就是表t的show index 的结果 。虽然这个表的每一行的三个字段值都是一样的,但是在统计信息中,这三个索引的基数值并不同,而且其实都不准确。

????假如数据库一行行去统计,对于大的表肯定是不行的,于是数据库就使用抽样统计。 采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。在MySQL中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择:
????可以看到我们上面的统计是存在误差的,那么纠正这个偏差的方法肯定是让优化器再次统计一下。
count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数; 而count(字段),则表示返回满足条件的数据行里面,参数“字段”不为NULL的总个数。
注意哦,sever 自己判断
单看这两个用法的差别的话,你能对比出来,count(1)执行得要比count(主键id)快。因为从引擎返回id会涉及到解析数据行,以及拷贝字段值的操作。
如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;
如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
也就是前面的第一条原则,server层要什么字段,InnoDB就返回什么字段。
#### 但是count()是例外,并不会把全部字段取出来,而是专门做了优化,不取值。count()肯定不是null,按行累加。
按照效率排序的话,count(字段)<count(主键id)<count(1)≈count(),所以我建议你,尽量使用count()
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
原文:https://www.cnblogs.com/Benjious/p/12355815.html