默认情况下,Jmeter 在请求接口的时候,响应结果如果存在中的话默认会按照 uncode 处理,这样的话对于测试来说是非常不方便的所以,这里就分享一个由 uncode 编码转换为 utf-8 的方式;当然啦!我这个也是抄的,一方面是方便我自己查阅;一方面也是为了你们误入歧途(找不到称心的解决方案);
找到 Jmeter 安装目录中 bin 目录下的 jmeter.properties 文件,使用 sublime 等软件打开;
搜索关键字, default.encoding 找到如下代码;
# The encoding to be used if none is provided (default ISO-8859-1)
#sampleresult.default.encoding=ISO-8859-1在后面一行追加如下代码,下面粘贴已经修改好的代码;
# The encoding to be used if none is provided (default ISO-8859-1)
#sampleresult.default.encoding=ISO-8859-1
sampleresult.default.encoding=utf-8做完第一步操作后,一定要重启一下 Jmeter !!!
在指定线程组下添加 后置处理器 -> BeanShell PostProcessor ,然后在 script 处粘贴一下代码;
//获取响应代码Unicode编码的
String s2 = new String(prev.getResponseData(), "UTF-8");
//---------------一下步骤为转码过程---------------
char aChar;
int len = s2.length();
StringBuffer outBuffer = new StringBuffer(len);
for (int x = 0; x < len;) {
aChar = s2.charAt(x++);
if (aChar == '\\') {
aChar = s2.charAt(x++);
if (aChar == 'u') {
int value = 0;
for (int i = 0; i < 4; i++) {
aChar = s2.charAt(x++);
switch (aChar) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
value = (value << 4) + aChar - '0';
break;
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
value = (value << 4) + 10 + aChar - 'a';
break;
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
value = (value << 4) + 10 + aChar - 'A';
break;
default:
throw new IllegalArgumentException("Malformed ? \\uxxxx ?encoding.");
}
}
outBuffer.append((char) value);
} else {
if (aChar == 't')
aChar = '\t';
else if (aChar == 'r')
aChar = '\r';
else if (aChar == 'n')
aChar = '\n';
else if (aChar == 'f')
aChar = '\f';
outBuffer.append(aChar);
}
} else
outBuffer.append(aChar);
}
//-----------------以上内容为转码过程---------------------------
//将转成中文的响应结果在查看结果树中显示
prev.setResponseData(outBuffer.toString());以上操作之后,就可以使用 Jmeter 安静的测试了,但是在正式测试的时候,切记不要使用这种方式,会很消耗性能,影响性能测试的稳定性,可在调试阶段,使用此方法;下面附操作成功图。
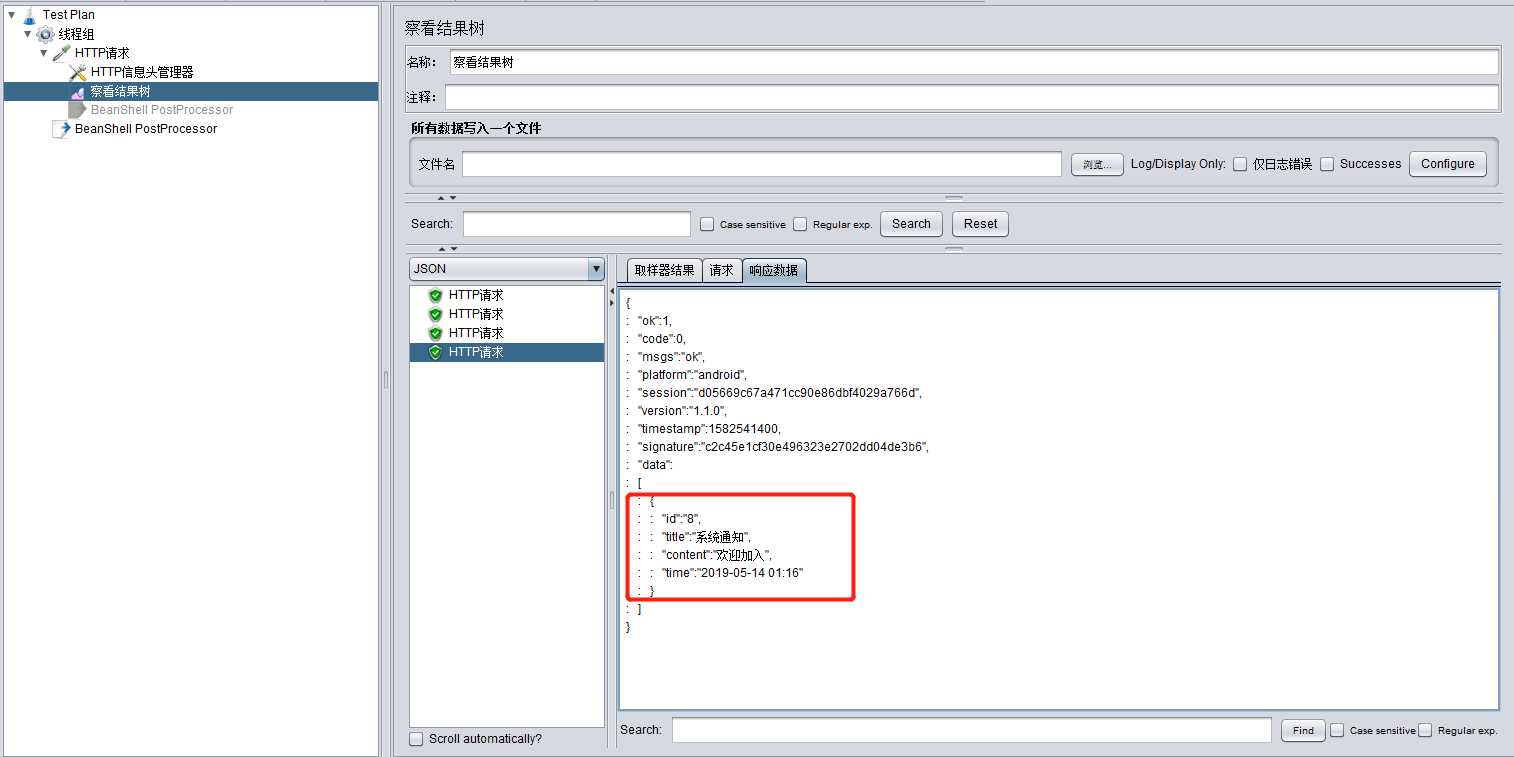
原文:https://www.cnblogs.com/article-record/p/12358217.html