机器学习分类,回归排序不同算法
分类(全是监督学习)
KNN 是指看邻近的三个点的分类,占多数的类别就是未知点的类别
主要是通过公式P(a|b)=P(b|a)*P(a)/P(b)
如果谁的概率大,谁就是正确的
假设一条w1x1+w2x2的线,然后把先验数据带进去,得到权重,最后用sigmoid函数将区间置于01中
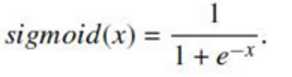
根据先验数据做出一个决策树,根据决策判断
找到一个样本空间上的一条线,划分出一个超平面,使不同类的分开。所以要选择扰动性最小,最好的线。
所以线性可分超平面的线是间隔最大的线。wx+b=y原则上w是任意的话,总能找到一个w使y=1。那些点就是支持向量。这几个点之间的距离,就是间隔。我们要使间隔最大。
凸二次规划问题,可以采用拉格朗日乘子法对其对偶问题求解。训练完成后,大部分样本都不需要保留,最终模型只与支持向量有关
回归
线性回归。多变量线性回归
y=w1x1+w2x2,,,
用梯度随机下降处理权重。但是处理不当会产生过拟合
岭回归
这种回归在放弃了一定无偏度的情况下,是一些病态的数组会扰乱结果,岭回归可以换取数值稳定性
如果高共线性不适用与岭回归
排序
单文档
单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果。下面我们用一个简单的例子说明这种方法。
人工标注的训练集合,在这个例子中,我们对于每个文档采用了3个特征: 査询与文档的Cosme相似性分值、査询词的Proximity值及页面的PageRank数值,而相关性判断是二元的,即要么相关要么不相关,当然,这里的相关性判断完全可以按照相关程度扩展为多元的,本例为了方便说明做了简化。
文档对方法
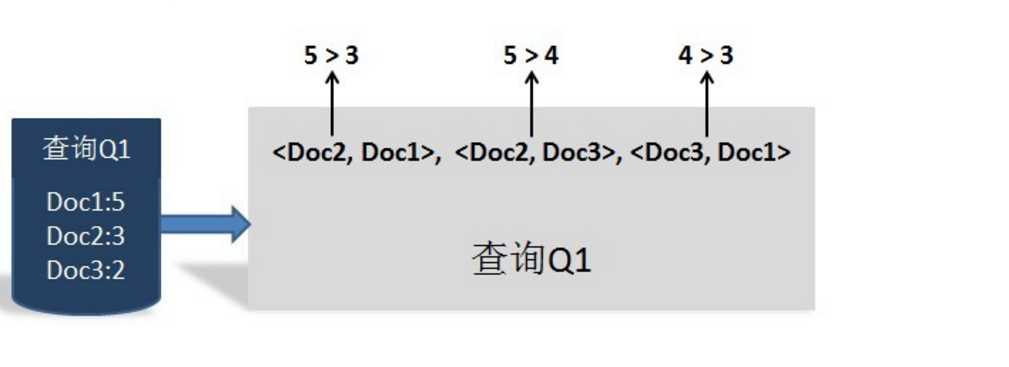
文档列表方法,是用一个列表的方式来学习
原文:https://www.cnblogs.com/yzwdxmw/p/12363953.html