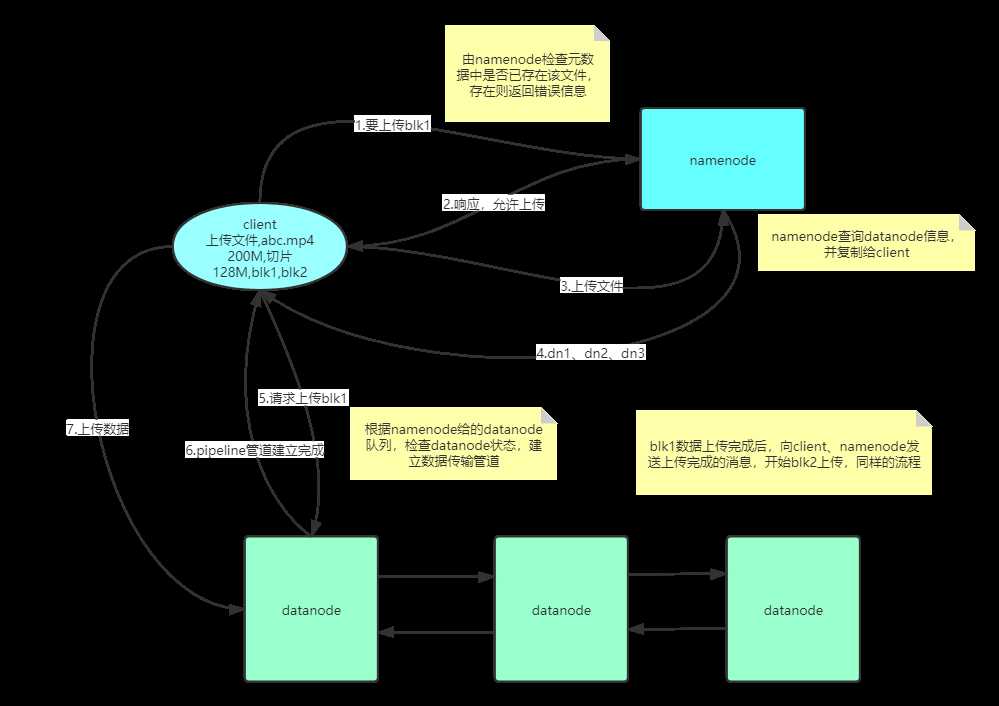
一、写流程
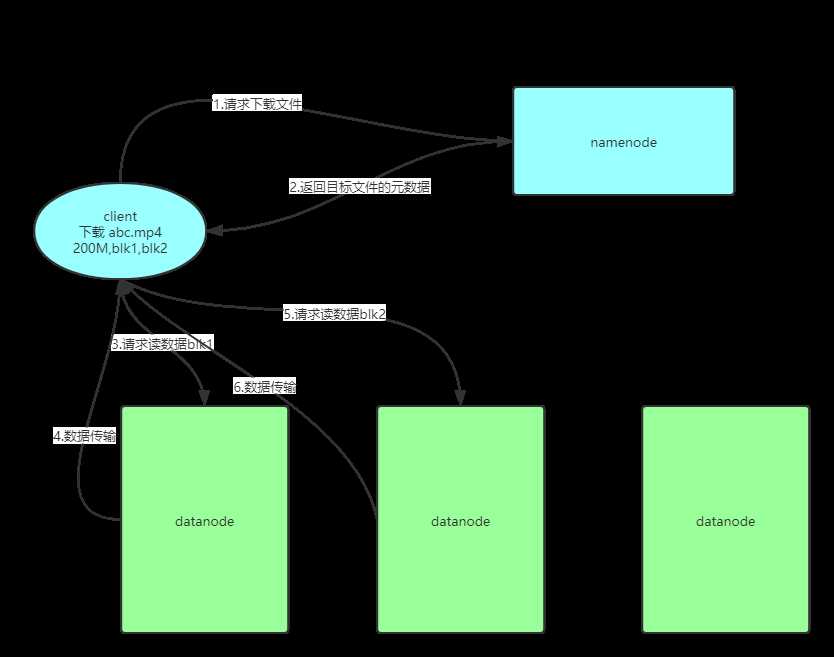
二、读流程
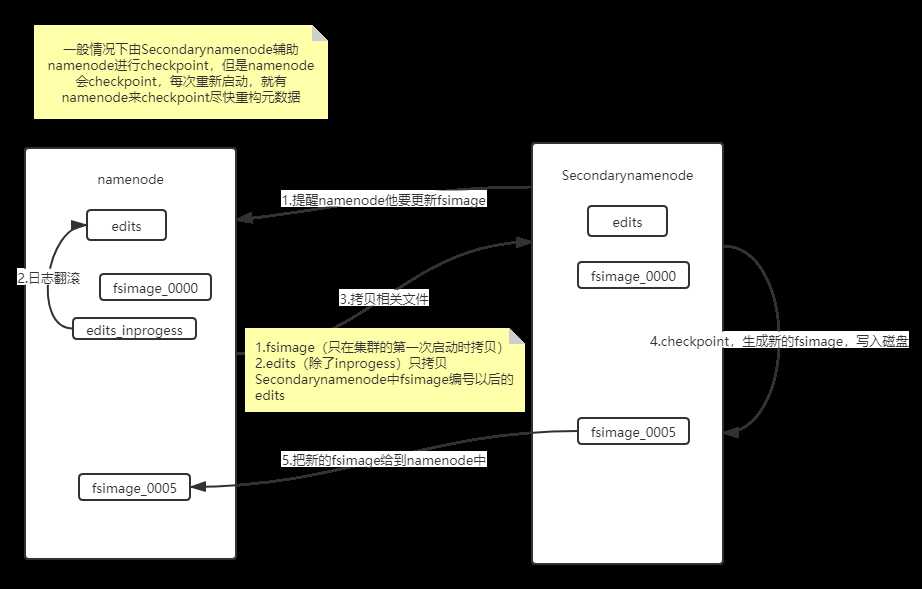
三、元数据,secondarynamenode
元数据:抽象目录树、数据和块的映射关系、数据块的存储节点(相当于书籍的目录,方便查找)
fsimage:文件是文件系统元数据的一个永久性检查点,包含文件系统中的所有目录和文件idnode的序列化信息。
edits:文件系统的写操作首先把它记录在edit中
secondarynamenode作为namenode的备份(默认是在同一节点,但是在同一节点备份没有意义),并且帮助namenode进行checkpoint
通过修改hdfs-site.xml文件,指定secondarynamenode的地址
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdp-07:50090</value>
</property>
四、checkpoint
原文:https://www.cnblogs.com/zhan98/p/12383607.html