首先了解一下支持我国的字符集的发展历史
从最开始的ASCII--->gb2312--->gbk--->unicode--->utf-8
ASCII:不支持中文
gb2312:支持中文2000多个
gbk:支持中文两万多个
unicorn:万国编码
utf-8:包含符合各国语言的字符集
字符集之间的转换,如下图所示
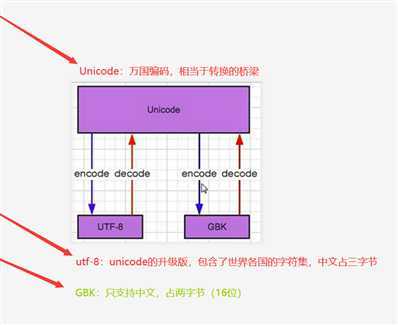
decode:转换成unicode,万国编码。 注意:转换成unicode,得告诉电脑,你原来的什么编码,要不然计算机是无法知道你原来编码的类型,会出错
encode:转换成utf-8,或者其他各国的字符集
例子1:从gbk转换成utf-8
a.decode(‘gbk‘).encode(‘utf-8)
例子2:从utf-8转换成gbk
a.decode(‘utf-8‘).encode(‘‘gbk)
最后说一下,utf-8转unicode的办法:a = u‘value’ ,前端加u也可以。
原文:https://www.cnblogs.com/yeyu1314/p/12391858.html