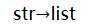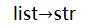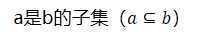Table of Contents |
- 参考 - 快速输入 ????- 输入字符串 ????- 输入整数 ????- 输入小数 ????- 创建空对象 ????- Attention ????????- OJ Python的答题结果:"返回非零" ????????- Python中没有 i++ 或者 i-- - 数据类型 ????- bool ????- 整型 ????- 浮点型 ????- 除法 ????- 查看类与类的关系:type()函数和isinstance()函数 - 基本数据结构 ????- 字符串str ????????- 编码与字符的转换 ????????- 查看当前python(py文件)使用的字符编码 ????- ????- 列表list ????????- 预分配与初始化 ????????- 增删查改 ????????- (一维)列表的反转 ????????- 列表的排序 ????????- 列表list与字符串str的转换 ????- 元组tuple ????- 字典dict ????????- 预分配与初始化 ????????- 增删查改 ????????- 视图 ????- 集合set ????????- 预分配与初始化 ????????- 增删查改 ????????- 集合的运算 - 运算和控制结构 ????- 运算符 ????????- bool() 函数的特殊用法 ????????- 比较运算符的连用 ????????- [表达式1, 表达式2][表达式3] ????- if ????- while循环 ????????- while 循环可使用 else 语句 ????- 推导式/解析式 ????????- 列表推导式 ????????- 字典推导式 ?? |
Python 3教程 | |
runoob PDF下载地址 | https://github.com/gagayuan/runoob-PDF-/tree/master/runoob/%E6%9C%8D%E5%8A%A1%E7%AB%AF |
? ?
input()函数接受整行字符串,并返回所得字符串。 | ||||||
str.split():字符串分割函数 通过指定分隔符对字符串进行切片,并返回分割后的字符串列表。 ? ? 语法: str.split(sep = None, maxsplit = -1)[n] ? ? 参数说明:
|
? ?
输入整行字符串 | s = input(‘prompt‘) | ||
以空格分割字符串 |
| ||
以"/"分割字符串 |
|
? ?
? ?
map() 函数:根据提供的函数对指定序列做映射。 ? ? map(function, iterable, ...) 第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
? demo:
|
? ?
输入一个整数 | 用int()函数将input()所得字符串转换为整数 a = int(input()) |
在一行中输入多个以空格分开的整数到指定变量 | 先用split()函数将input()所得字符串按空格分割,得到子串列表。 然后用int()函数将子串转换为整数。 最后用map()函数返回相应的迭代器以赋值。 n, p = map(int, input().split()) |
在一行中输入多个以","分开的整数到指定变量 | n, p = eval(input()) |
将一行中的整数输入到列表中 | 用list()函数将map()所得的迭代器转换为列表 ar = list(map(int, input().split())) |
? ?
? ?
string.atof()函数 |
? ?
输入一个小数 |
| |
输入一行小数,存在列表中 |
|
? ?
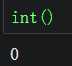
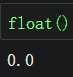
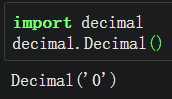
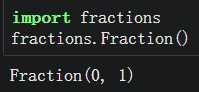
python中的所有类型(包括整数和浮点数)均会装箱,故可创建相应类型的空对象,值为默认值。
数字型的类会返回0,其他类型的返回空。
整数 |
|
浮点数 |
|
高精度decimal |
|
分数fractions |
|
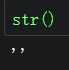
字符串 |
|
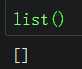
列表list |
|
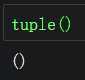
元组tuple |
|
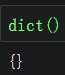
字典dict |
|
? ?
如果是python2提交,就要用raw_input();
如果是python3提交,就要用input()。
? ?
Python规定,数值对象是不可改变的。 因此,Python中没有自增和自减。 i = i + 1 相当于重新创建了一个变量 i ,而不是改变了 i 中的数值。 可如下代替自增自减: i = i + 1 或者 i += 1 |
? ?
? ?
? ?
真 | True |
假 | False |
PS:Python中的布尔值首字母大写
? ?
bool()?函数:将参数转换为布尔类型。如果没有参数,则返回?False。 bool?是?int?的子类。 |
class bool([x]) # x?--?要进行转换的参数。? # 返回?True?或?False。 |
? ?

? ?
? ?
positive_inf = float("inf") # ?正无穷 negative_inf = float("-inf") # ?负无穷 not_number = float("nan") # ?非数 |
? ?
python查看float的最值 |
import sys float_max = sys.float_info.max float_min = sys.float_info.min print(str(float_max) + " " + str(float_min)) |
float的最大值:1.7976931348623157e+308 大于0时float的最小值:2.2250738585072014e-308 小于0时float的最大值:-2.2250738585072014e-308 float的最小值:-1.7976931348623157e+308 |
? ?
? ?
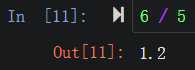
默认是小数除法 |
|
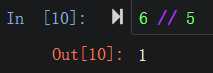
地板除 |
|
四舍五入 | round( x [, n] ) 保留n位小数(四舍五入,浮点数可能会受计算机表示的精度影响从而影响四舍五入)。 默认保留整数。 |
? ?
? ?
参考 | |||
type() | 如果只有第一个参数则返回对象的类型,三个参数返回新的类型对象。
|
? ?
? ?
? ?
?? |
? ?
import sys sys.getdefaultencoding() |
? ?
string模块提供了许多常用功能,如
string.digits | 数字 |
string.ascii_lowercase | 小写字母 |
string.ascii_uppercase | 大写字母 |
? ?
? ?
? ?
创建空列表 |
| ||||
预分配长度为n的空列表 |
| ||||
可迭代对象转换为列表 |
? ? demo 用可迭代的初值初始化列表:
? ? demo 用列表推导式剔除不需要的数据,以初始化列表:
|
? ?
增 |
? ?
| |||||||
删 |
| |||||||
查 |
| |||||||
改 | list1[下标] list1[切片] list1[-1] # list1的最后一个元素
|
? ?
(一维)列表的反转
|
? ?
列表的排序 | ||||||
? ? demo 2:
|
? ?
|
| |||||
|
|
? ?
? ?
tuple不可修改其中的元素,而list可以,其余操作与list相同。
tuple( iterable ) |
iterable -- 要转换为元组的可迭代序列 |
? ?
当创建只有一个元素的元组时,tuple1 = (1)会被视为整型而非元组。
解决方法:加一个逗号
tuple1 = (1, ) |
? ?
? ?
创建空字典 |
| |||
逐对键值对初始化字典 |
| |||
(序列,默认值)初始化字典 | dict.fromkeys(seq[, val]) 返回一个新字典,以序列 seq 中的元素作为字典的键,val 为字典所有键值对应的初始值 | |||
(序列,序列)初始化字典 |
| |||
合并字典 |
|
? ?
增 |
| |||||||
删 |
| |||||||
查 |
| |||||||
改 | dict1[value1] |
? ?
对dict本身的修改会影响到"视图"
dict.keys() | key |
dict.values() | value |
dict.items() | key-value |
? ?
demo 使用"视图"访问dict中的key-value:
lang_dict = {1: ‘C++‘, 2: ‘Java‘, 3: ‘Python‘} for idx, val in lang_dict.items(): print(str(idx), val) |
输出: 1 C++ 2 Java 3 Python |
? ?
? ?
demo:
# 用dict.update()方法更新字典 import string ???????????????? ? dicts = dict.fromkeys(string.digits, False) dicts.update(dict.fromkeys(string.ascii_lowercase, False)) dicts[‘_‘] = False |
或者
# 用{**, **}的形式合并字典 import string ???????????????? ? dict_digits = dict.fromkeys(string.digits, False) dict_alphabet = dict.fromkeys(string.ascii_lowercase, False) dicts={**dict_digits, **dict_alphabet} dicts[‘_‘] = False |
? ?
x = int(input("Enter the 1st number: ")) y = int(input("Enter the 2nd number: ")) ? ? def operator(o): dict_oper ={ ‘+‘: lambda x, y: x + y, ‘-‘: lambda x, y: x - y, ‘*‘: lambda x, y: x * y, ‘/‘: lambda x, y: x / y } return dict_oper.get(o)(x, y) ? ? if __name__ == ‘__main__‘: o = input("Enter operation here(+ - * /): ") print(operator(o)) |
? ?
? ?
set中的对象不变且可哈希 |
frozenset(冻结的集合),不可增删元素 |
? ?
创建空集合 | set1 = set() | ||
由序列seq初始化集合 |
|
? ?
增 |
|
删 |
|
查 | ?? |
改 | ?? |
? ?
判断是否没有公共元素 |
| |||
判断子集 |
| |||
判断超集 |
| |||
并集 |
| |||
交集 |
| |||
差集 |
| |||
对称差 |
|
? ?
demo 求两个字典的相同的键值(即求键值的交集):
d1_keys = set(d1.keys()) d2_keys = set(d2.keys()) set1 = d1_keys.intersection(d2_keys) |
? ?
? ?
? ?
False None 0 "" () [] {} | False |
Python中,False、None、0和空的数据结构经bool() 函数转换后均为False。
非零非空的数据结构经bool() 函数转换后为True。
? ?
记比较运算符为 op,
若 a op1 b op2 c,
则 (a op1 b) and (b op2 c)
? ?
若表达式3为True,则执行表达式2;
若表达式3为False,则执行表达式1。
相当于C++中的三元运算符 ? : 。
[False, True][4 > 3] |
>>> True |
要在列表表达式后加 () 表示函数。
def false(): print("判断错误") ? ? ? ? def true(): print("判断正确") ? ? ? ? [false, true][1 > 9]() |
>>> ‘判断错误‘ |
? ?
if <expr>: <statement(s)> elif <expr>: ????????<statement(s)> else: ????????<statement(s)> |
? ?
while … else 在条件语句为 false 时执行 else 的语句块。
while <expr>: ????<statement(s)> else: ????<additional_statement(s)> |
? ?
? ?
enumerate(sequence, [start = 0]) |
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列, |
|
? ?
demo 产生10个100以内的随机数:
from random import randint list1 = [randint(1, 100) for i in range(10)] |
? ?
demo 为列表中的元素标号,存入字典中:
lang_list = ["C++", "Java", "Python"] lang_dict = {idx: lang for idx, lang in enumerate(lang_list, 1)} # 值:{1: ‘C++‘, 2: ‘Java‘, 3: ‘Python‘} |
? ?
demo 计算两个列表对应元素之和:
原数据 | a = [1,2,3,4] b = [9,8,7,6] |
列表推导式 | c = [a[i] + b[i] for i in range(len(a))] |
map() 函数 | c = list(map(lambda x, y: x + y, a, b)) |
? ?
demo 统计列表元素出现的次数,结果存入字典中:
原数据 | lang_list = ["C++", "Java", "Python", "C++"] |
使用 dict.get() | lang_dict = {} for item in lang_list: lang_dict[item] = lang_dict.get(item, 0) + 1 |
字典推导式 | lang_dict = {elem: lang_list.count(elem) for elem in set(lang_list)} |
结果 | {‘C++‘: 2, ‘Python‘: 1, ‘Java‘: 1} |
? ?
原文:https://www.cnblogs.com/audacious/p/12393367.html