此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent的具体区别就不细说了。现在的SGD一般都指mini-batch gradient descent。
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:
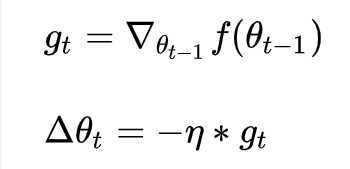
其中,是学习率,
是梯度 SGD完全依赖于当前batch的梯度,所以
可理解为允许当前batch的梯度多大程度影响参数更新
缺点:(正因为有这些缺点才让这么多大神发展出了后续的各种算法)
momentum是模拟物理里动量的概念,积累之前的动量来替代真正的梯度。公式如下:
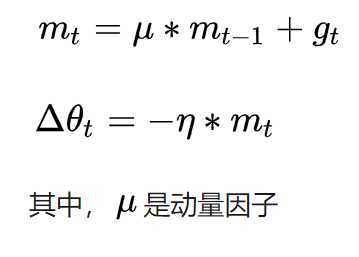
特点:
原文:https://www.cnblogs.com/ziwh666/p/12401931.html