当用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。正则化的目的是防止过拟合,减小误差。
在学习正则化之前先来回顾L1范数和L2范数。
L1范数:最小绝对值误差(LAE)。它是使目标值与预测值的绝对值总和最小化
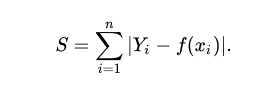
L2范数:最小平方误差(LSE)。它是目标值和预测值平方差的最小化。
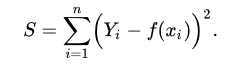
正则化:在目标函数后面添加一个系数的“惩罚项”,为了防止系数过大从而让模型变得复杂。在加了正则化项之后的目标函数为:
L1正则化:w矢量中会有许多0,让矩阵变得稀疏,但作用不大(吴恩达老师说的)
L2正则化: 在训练模型时,用的较多。

w会乘以一个小于1的数字,会让梯度变得更小,如果λ过高,会使W接近0,参数接近为0的网络几乎不起作用,这样就会让网络变得简单,可以防止过拟合。
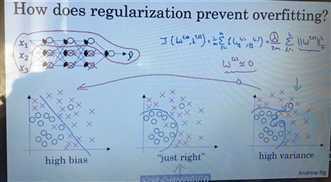
如果网络很复杂,则使用正则化,λ如果过高,网络会从图3变为图1,所以,调整适当的λ值,让网络刚刚好。
原文:https://www.cnblogs.com/gaona666/p/12419227.html