1、数据清洗是整个数据分析过程的第一步,也是整个数据分析项目中最耗费时间的一步
2、数据清洗的过程决定了数据分析的准确性
3、随着大数据的越来越普及,数据清洗是必备的技能之一
4、利用Python进行高效的数据处理变得十分重要
以电商数据为基础
1、熟练掌握数据清洗相关方法和技巧
2、熟练掌握Numpy和Pandas库在数据清洗中运用
1、Numpy常用数据结构和方法
2、Numpy常用数据清洗函数
3、Pandas常用数据结构series和方法
4、Pandas常用数据结构dataframe和方法
1、Pandas读写CSV文件和相关参数解释
2、Pandas读写excel文件和相关参数解释
3、Pandas与mysql的交互
1、数据筛选
2、数据增加和删除
3、数据修改和查找
4、数据整理
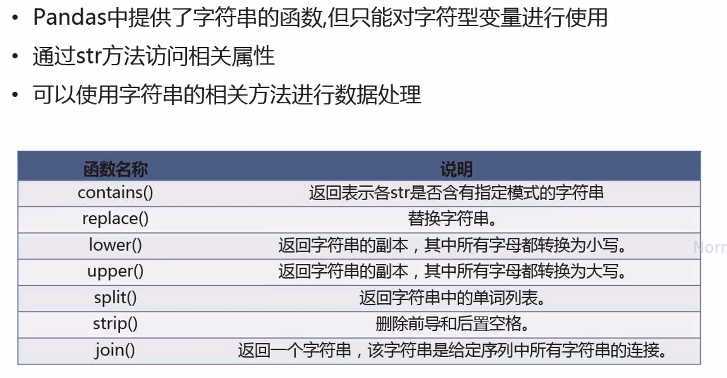
1、字符串数据处理
2、日期格式数据处理
3、利用函数或者映射对数据转换
1、数据分组groupby方法
2、分组对象聚合函数运用
3、分组对象和apply函数运用
1、重复值处理
2、缺失值处理
3、异常值处理
4、数据离散化
数据清洗实质上是将实际业务问题中,脏数据清洗干净,转换为‘干净的数据’,所谓的脏,指数据可能存在以下几种问题(主要问题):
1、数据缺失(Incomplete)是属性值为空的情况。如Occupancy=""
2、数据噪声(Noisy)是数据值不合常理的情况。如Salary="-100"
3、数据不一致(Inconsistent)是数据前后存在矛盾的情况。如Age="042"或者Birthday="01/09/1985"
4、数据冗余(Redundant)是数据量或者属性数目超出数据分析需要的情况。
5、离群点/异常值(Outliers)是偏离大部分值得数据
6、数据重复是在数据集中出现多次的数据
1、现实生活中,数据并非完美,需要进行清洗才能进行后面的数据分析
2、数据清洗是整个数据分析项目最耗费时间的一步
3、数据的质量最终决定了数据分析的准确性
4、数据清洗是唯一可以提高数据质量的方法,使得数据分析的结果也变得更加可靠
1、目前在Python中,numpy和pandas是最主流的工具
2、Numpy中的向量化运算使得数据处理变得高效
3、Pandas提供了大量数据清洗的高效方法
4、在Python中,尽可能多的使用numpy和pandas中的函数,提高数据清洗的效率
1、Numpy中常用的数据结构是ndarray格式
2、使用array函数创建,语法格式为array(列表或元祖)
3、可以使用其他函数例如arange、linspace、zeros等创建
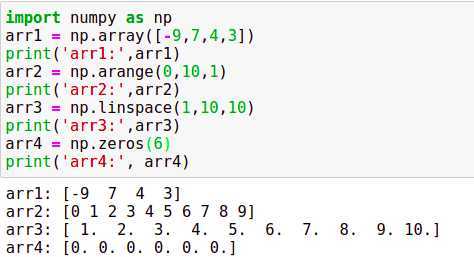
说明:ndim返回维度,shape返回数组的结构,size返回数组的总元素个数,dtype返回数组元素的类型
np.array[a,b] a:代表行索引 b:代表列索引
sort函数:从小到大进行排序,关键字axis确定轴向,reverse确定排序方向
argsort函数:返回的是数据中,从小到大的索引值
where函数:np.where(s>3,1,-1)s>3,返回1,否则-1
extract函数:np.extract(s>3,s) 条件满足找出,否则丢弃
通过pandas.Series来创建Series数据结构
pandas.Series(data,index,dtype,name)
上述参数中,data可以为list,array或者dict。
上诉参数中,index表示索引,必须与数据同长度,name代表对象的名称
通过pandas.DataFrame来创建DataFrame数据结构
pandas.DataFrame(data,index,dtype,columns)
上述参数中,data可以为list,array或者dict
上述参数中,index表示行索引,columns代表列名或者列标签
pandas内置了10多种数据源读取函数,常见的就是CSV和Excel
使用read_csv方法读取,结果为dataframe格式
在读取csv文件时,文件名称尽量是英文
参数较多,可以自行控制,但很多时候用默认参数
读取CSV时,注意编码,常用编码为utf-8,gbk,gbk2312和gb18030等
使用to_csv方法快速保存
df = pd.read_csv(‘meal_order_info.csv‘,encoding=‘gbk‘)df =pd.read_csv(‘meal_order_info.csv‘,encoding=‘gbk‘,nrows=10)df.to_csv(‘df.csv‘, index=False)
小技巧:1a.set_option(‘display.max_rows‘:100)
2import os
os.chdir(‘path‘)
整理的流程:

使用read_excel方法读取,结果为dataframe格式
读取excel文件和csv文件参数大致一样,但要考虑工作表sheet页
参数较多,可以自行控制,但很多时候用默认参数
读取excel时,注意编码,常用编码为utf-8,gbk,gbk2312和gb18030等
使用to_excel方法快速保存为xlsx格式
df = pd.read_excel(‘meal_info.xlsx‘,sheet_name=‘sheet1‘)
df = pd.read_excel(‘meal_info.xlsx‘,encoding=‘utf-8‘,nrows=10) df.to_excel(‘a.xlsx‘,sheet_name=‘sheet1‘,index=False,encoding=‘utf-8‘)
使用sqlalchemy建立连接
需要知道数据库的相关参数,如数据库IP地址、用户名和密码等
通过pandas中read_sql函数读入,读取完以后是dataframe格式
通过dataframe的to_sql方法保存
sql = ‘select * from meal_order_info‘ df1 = pd.read_sql(sql,conn) df.to_sql(‘testdf‘,con=conn,index=False,if_exists=‘replace‘)
数据库建立连接参数
conn = create_engine(‘mysql+pymysql://user:passward@IP:3306/test01‘)
root:用户名
passward:密码
IP:服务器IP,本地电脑用localhost
3306:端口号
test01:数据库名称
df.to_sql(name, con=engine,if_exists=‘replace/append/fail‘,index=False)
name是表名
con是连接
if_exists:表如果存在怎么处理。三个选项append代表追加,replace代表删除原表,建立新表,fail代表什么都不干
index=False 不插入索引index
1.1 数据常用筛选方法
在数据中,选择需要的行或者列
基础索引方式,就是直接引用
ioc[行索引名称或者条件,列索引名称或者标签]
iloc[行索引位置,列索引位置]
注意:区分loc和iloc
loc索引的是标签的名称,iloc索引的是行列的索引编号
在数据中,直接添加列
使用df.insert方法在数据中添加一列
掌握drop(labels, axis, inplace=True)的用法
labels表示删除的数据,axis表示作用轴,inplace=True表示是否对原数据生效
axis=0按行操作,axis=1按列操作
使用del函数直接删除其中一列
del basic[‘数据‘]
basic.drop(labels=[‘数量‘,‘价格‘], axis=1, inplace=True)
basic.drop(labels=range(6,11), axis=0, inplace=True)
basic.insert(位置, ‘新名称‘,需要插入的数据)
在数据中,可以使用rename修改列名称或者行索引名称
使用loc方法修改数据
条件与条件之前用&或者|连接,分别代表‘且‘,‘或‘
使用between和isin选择满足条件的行

df[df[‘buy_mount‘].between(4,10, inclusive=True)]
定义:在数据清洗过程中,很多时候需要将不用的数据整理在一起,方便后续的分析,这个过程也叫数据合并。
合并方法:常见的合并方法有堆叠和按主键进行合并,堆叠又分为横向堆叠和纵向堆叠,按主键合并类似于sql里面的关联操作。

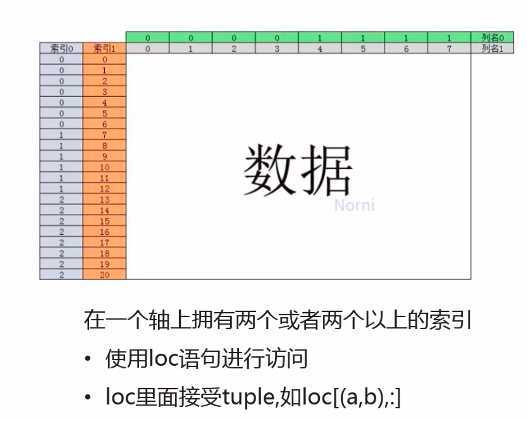
df.loc[(28,[20303,2344]),[‘auction_id‘,‘cat_id‘]]
Pandas中使用to_datetime()方法将文本格式转换为日期格式
dataframe数据类型如果为datatime64,可以使用dt方法取出年月日等
对于时间差数据,可以使用timedelta函数将其转换为指定时间单位的数值
时间差数据,可以使用dt方法访问其常用属性
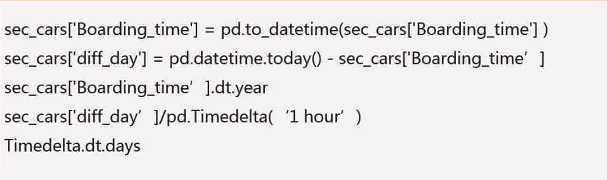
df[‘diff_day‘].astype(‘timedelta64[Y]‘)
在dataframe中使用apply方法,调用自定义函数对数据进行处理
函数apply,axis=0表示对行进行操作,axis=1表示对列进行操作
可以使用astype函数对数据进行转换
可以使用map函数进行数据转换


df2[‘性别‘]=df2[‘gender‘].map({‘0‘:‘女‘,‘1‘:‘男‘,‘2‘:‘未知‘})
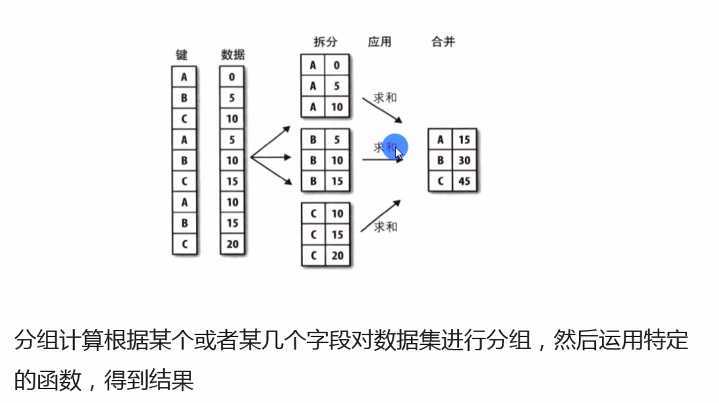
语法为df.groupby(by=)
分组对象GroupBy可以运用描述性统计方法,如count、mean、median、max、和min等
Group = load_info.groupby(by=‘product‘)
group1 = loan_info.groupby(by=[‘product‘,‘jgmc‘])
Group.mean()
Group.sum()
Group.max()
对分组对象使用agg聚合函数
Groupby.agg(func)
针对不同的变量使用不同的统计方法
grouped.agg([np.mean,np.max]).head(20)
grouped.agg({‘ye‘:np.mean,‘dkje‘:np.max})
loan_info[[‘dkje‘,‘ye‘,‘yqje‘]].agg([np.sum,np.mean])
函数apply既可用于分组对象,也可以作用于dataframe数据
Groupby.apply(func)
需要注意axis=0和axis=1的区别

apply只能接一个函数,这是和聚合函数的区别
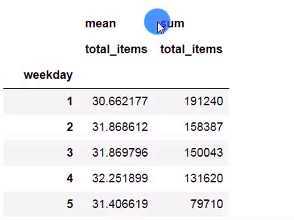
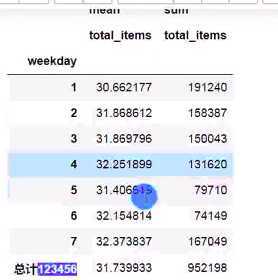
在数据分析中,数据透视表是常见的工具之一,需要根据行或列对数据进行各个维度数据的汇总,在pandas中,提供了相关函数解决此类问题,交叉表更多用于频数的分析。
透视表
pivot_table(data, index, columns,values, aggfnc, fill_value, margins, margins_name=)
index:行分组键
values:分组的字段,只能为数值型变量
aggfunc:聚合函数
margins:是否需要总计
fill_value:缺失值填充的字段

pd.pivot_table(data=df, index=‘weekday‘,values=‘total_items‘,aggfunc= [np.mean,np.sum],fill_name=0,margins=True,margins_name=‘总计‘)
交叉表用于计算分组频率
pd.crosstab(index,columns,normalize)
index:行索引
columns:列索引
normalize:数据对数据进行标准化,index表示行,column表示列
pd.crosstab(index=df[‘weekday‘], columns=df[‘discount%‘],marings=True,normalize=‘all‘
数据清洗一般先从重复值和缺失值开始处理
重复值一般采取删除法来处理
但有些重复值不能删除,例如订单明细数据或交易明细数据等
df[df.duplicated()]
np.sum(df.duplicated())
df.drop_duplicates()
df.drop_duplicates(subset=[‘appname‘,‘size‘],inplace=True)
缺失值首先需要根据实际情况定义
可以采取直接删除法
有时候需要使用替换法或者插值法
常用的替换法有均值替换、前向、后向替换和常数替换
df.dropna(how=‘all‘,axis=0) #how可取any或all,dropna函数删除一行数据
df.age.fillna(df.age.mean())
df.age.fillna(df.age.median())
df.fillna(20)
df[‘Exterior_Color‘].fillna(method=‘ffill‘) #前向填补
df[‘Exterior_Color‘].fillna(method=‘bfill‘) #后向填补
指那些偏离正常范围的值,不是错误值
异常值出现频率较低,但又会对实际项目分析造成偏差
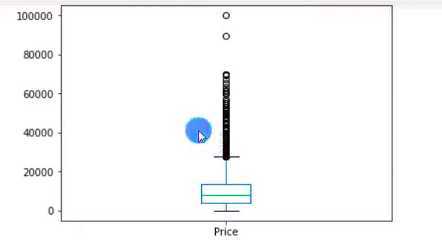
异常值一般用过箱线图法(分位差法)或者分布图(标准差法)来判断
异常值往往采取盖帽法或者数据离散化
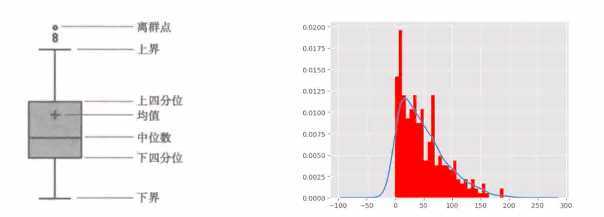
分位差等于上四分位减去下四分位
下界是低于下四分位减去1.5倍分位差
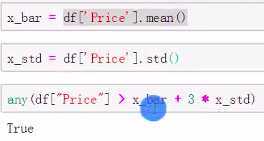
标准差函数std()
分位差法:

标准差法:
图像观看:
分布图方法:

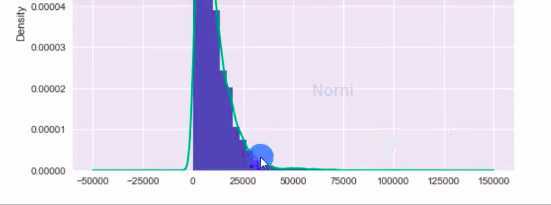
盖帽法:
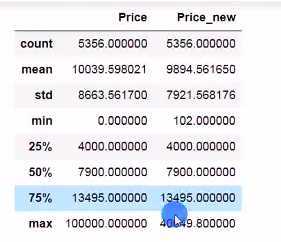
P99=df[‘Price‘].quantile(q=0.99)
P1 = df[‘Price‘].quantile(q=0.01)
df[‘Price_new‘]=df[‘Price‘]
df.loc[df[‘Price‘]>P99,‘Price_new‘]=P99
df.loc[df[‘Price‘]<P1,‘Price_new‘]=P1
df[[‘Price‘,‘Price_new‘]].describle()
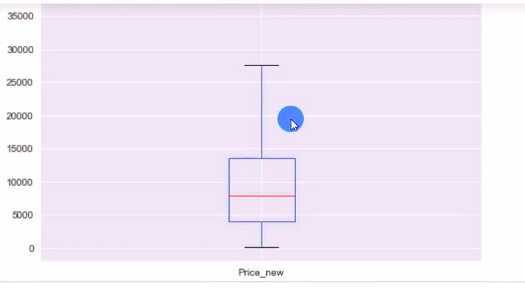
df[‘Price_new‘].plot(kind=‘box‘)
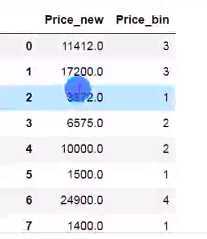
一般常用分箱方法是等频分箱或者等宽分箱
一般使用pd.cut或者pd.qcut函数

等宽分箱:
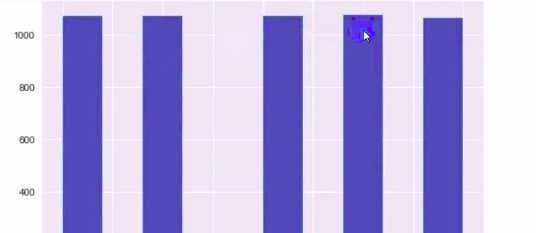
df[‘Price_bin‘] = pd.cut(df[‘Price_new‘],5,labels=range(5))
df[‘Price_bin‘].value_counts().plot(kind=‘bar‘)
或者df[‘Price_bin‘].value_counts().hist()
bins的值可以替换

df[[‘Price‘,‘Price_bin‘]]
等频分箱:
k=5
w = [1.0*i/k for i in range(k+1)]
df[‘Price_bin‘]=pd.qcut(df[‘Price_new‘], q=w, labels=range(5))
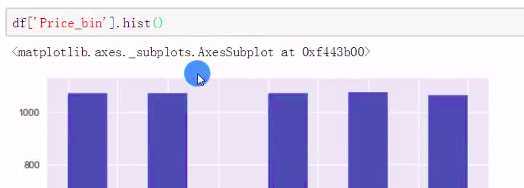
df[‘Price_bin‘].hist()
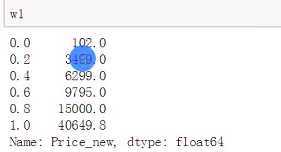
w1=df[‘Price_new‘].quantile(1.0*i/k for i in range(k+1))
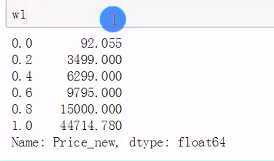
等频分段时要确保分段标准的最大值比实际最大值大,最小值比实际最小值小,否则会出现数据失真(左闭右开)。
w1[0]=w[0]*0.95
df[‘Price_bin‘] = pd.cut(df[‘Price_new‘],bins=w1,labels=range(5))



原文:https://www.cnblogs.com/nuochengze/p/12426527.html