转自:https://zhuanlan.zhihu.com/p/28095072
网络领域的新词发现是一个非常重要的nlp课题。在处理文本对象时,非常关键的问题在于“切词”这个环节,几乎所有的后续结果都依赖第一步的切词。因此切词的准确性在很大程度上影响着后续的处理,切词结果的不同,也就影响了特征的提取,跟数据挖掘一样,特征提取的好坏特别重要,不论用什么算法,特征好数据好结果才会好。
目前很多的切词模块可以处理大部分的通用语料,然而有两类文本集仍然处理的不是很好,就是:
1.网络文档
2.领域文档
这两类文本的特点在于包含大量新词,一般词典的涵盖程度比较低。对于领域文档,各领域的专家可以人工构建知识本体,拓展已有词库的不健全,此处不赘述。
已有的方法大致有两个思路:
1.基于构词法(语言规则,需要对特定语言语法规则的理解)
2.基于统计模型(基于字符排列的统计分析和基于词排列的统计分析)
挖掘新词的传统方法是,先对文本进行分词,然后猜测未能成功匹配的剩余片段就是新词。这似乎陷入了一个怪圈:分词的准确性本身就依赖于词库的完整性,如果词库中根本没有新词,我们又怎么能信任分词结果呢?此时,一种大胆的想法是,首先不依赖于任何已有的词库,仅仅根据词的共同特征,将一段大规模语料中可能成词的文本片段全部提取出来,不管它是新词还是旧词。然后,再把所有抽出来的词和已有词库进行比较,不就能找出新词了吗?有了抽词算法后,我们还能以词为单位做更多有趣的数据挖掘工作。
1.term在文章中出现的次数够多
可以统计文章中的素有片段的数量,给这些片段设一个阈值,超过此阈值才能有资格成为一个词。但仅仅这样是不够的,“的电影”出现了 389 次,“电影院”只出现了 175 次,然而我们却更倾向于把“电影院”当作一个词,因为直觉上看,“电影”和“院”凝固得更紧一些。
2.词的内部要足够稳定
凝固度用什么来衡量呢,答案是点间互信息(pointwise mutual information)
PMI =p(x,y)/(p(x)*p(y))
如果x,y独立 ,那么pmi等于1。如果不独立,则PMI大于1,当PMI足够大的时候就表示凝固度足够高。拿 “知”、“乎” 这两个字来说,假设在 5000 万字的样本中, “知” 出现了 150 万次, “乎” 出现了 4 万次。那 “知” 出现的概率为 0.03, “乎” 出现的概率为 0.0008。如果两个字符出现是个独立事件的话,”知”、“乎” 一起出现的期望概率是 0.03 * 0.0008 = 2.4e-05. 如果实际上 “知乎” 出现了 3 万次, 则实际上”知”、“乎” 一起出现的概率是 6e-03, 是期望概率的 250 倍。也就是说两个字越相关,点间互信息越大。
你以为这样就行了嘛,naive!
光看文本片段内部的凝合程度还不够,我们还需要从整体来看它在外部的表现。考虑“被子”和“辈子”这两个片段。我们可以说“买被子”、“盖被子”、“进被子”、“好被子”、“这被子”等等,在“被子”前面加各种字;但“辈子”的用法却非常固定,除了“一辈子”、“这辈子”、“上辈子”、“下辈子”,基本上“辈子”前面不能加别的字了。“辈子”这个文本片段左边可以出现的字太有限,以至于直觉上我们可能会认为,“辈子”并不单独成词,真正成词的其实是“一辈子”、“这辈子”之类的整体。可见,文本片段的自由运用程度也是判断它是否成词的重要标准。如果一个文本片段能够算作一个词的话,它应该能够灵活地出现在各种不同的环境中,具有非常丰富的左邻字集合和右邻字集合。
那我们有没有办法衡量这种特性呢?答案是熵。
真是神奇啊,如果所有的东西都能用公式来衡量就好了。但往往不是,比如一个人美不美,就很难用公式来衡量。一个人是不是善良也无法用公式来衡量,所以说人是复杂的动物。
3.左邻字和右邻字要够丰富
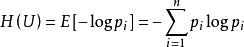
我们用信息熵来衡量一个文本片段的左邻字集合和右邻字集合有多随机。考虑这么一句话“吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮”,“葡萄”一词出现了四次,其中左邻字分别为 {吃, 吐, 吃, 吐} ,右邻字分别为 {不, 皮, 倒, 皮} 。根据公式,“葡萄”一词的左邻字的信息熵为 – (1/2) · log(1/2) – (1/2) · log(1/2) ≈ 0.693 ,它的右邻字的信息熵则为 – (1/2) · log(1/2) – (1/4) · log(1/4) – (1/4) · log(1/4) ≈ 1.04 。可见,在这个句子中,“葡萄”一词的右邻字更加丰富一些。
在实际运用中你会发现,文本片段的凝固程度和自由程度,两种判断标准缺一不可。只看凝固程度的话,程序会找出“巧克”、“俄罗”、“颜六色”、“柴可夫”等实际上是“半个词”的片段;只看自由程度的话,程序则会把“吃了一顿”、“看了一遍”、“睡了一晚”、“去了一趟”中的“了一”提取出来,因为它的左右邻字都太丰富了。
这次调研给我最大的收获是一个算法工程师的工程能力也很重要,算法大不了我花一周的时间去搞明白,但是你只是弄懂了却没有实现它的能力,或者效率不高,那有什么用呢?比如新词发现算法,半个小时的时间大家都明白了,有的人半个小时就把代码写出来了。有的人一天才写出来,有的人发现效率不高,又写了一个spark版本的。工程能力啊,代码能力啊一定要强。还是以码农自居比较好。
一种做法:
还有一种更直观的
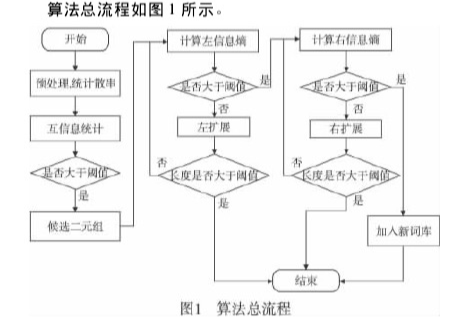
https://github.com/sing1ee/dict_build
原文:https://www.cnblogs.com/hellomaxwell/p/12451565.html