1、什么是装饰器
2、装饰器的作用
3、使用高阶函数模仿装饰器功能
1.定义:把一个函数名当做实参传给另一个函数
2.返回值中包含函数名
3.下面使用高阶函数虽然可以实现装饰器的一些功能,但是违反了装饰器不能改变调用方式的原则,
以前使用bar()现在将调用方式改编成了test1(bar)就是将bar的函数名当做变量传给了test1()

#! /usr/bin/env python # -*- coding: utf-8 -*- import time def timer(func): start_time = time.time() func() print ‘函数执行时间为‘, time.time() - start_time def test(): print ‘开始执行test‘ time.sleep(3) print ‘test执行结束‘ timer(test) ‘‘‘ 开始执行test test执行结束 函数执行时间为 3.00332999229 ‘‘‘
4.高阶函数——不修改高阶函数的调用方式增加新的功能(但是无法传参数)
注:bar = test2(bar) 等价于:@timer重新将函数名bar赋值,将原函数bar的内存地址当做实参传递该函数test2(),再将test2()赋值给bar
import time def bar(): time.sleep(3) print("in the bar") def test2(func): print(func) return func bar = test2(bar) bar()
5.嵌套函数
嵌套函数:在一个函数中嵌套另一个函数,并在函数内部调用
def foo(): print("in the foo") def bar(): print("in the bar") bar() foo()
4、能够适应90%的业务需求
import time def timer(func): #timer(test1) func=test1 def deco(*args,**kwargs): start_time = time.time() func(*args,**kwargs) #run test1 stop_time = time.time() print("running time is %s"%(stop_time-start_time)) return deco @timer # test1=timer(test1) def test1(): time.sleep(3) print("in the test1") @timer def test2(name): print("in the test2",name) test1() test2("tom")
5、对特定网页进行身份验证
import time user,passwd = ‘aaa‘,‘123‘ def auth(func): def wrapper(*args,**kwargs): username = input("Username:").strip() password = input("Password:").strip() if user == username and password == passwd: print("User has passed authentication") res = func(*args,**kwargs) #这里执行func()相当于执行调用的函数如home() return res #为了获得home()函数返回值,可以将执行结果赋值给res然后返回print(home())结果是"from home"而不是"None"了 else: exit("Invalid username or password") return wrapper def index(): print("welcome to index page") @auth def home(): print("welcome to home page") return "from home" @auth def bbs(): print("welcome to bbs page") index() print(home()) #在这里调用home()相当于调用wrapper() bbs()
6、实现对不同网页不同方式的身份认证
import time user,passwd = ‘aaa‘,‘123‘ def auth(auth_type): print("auth func:",auth_type) def outer_wrapper(func): def wrapper(*args, **kwargs): print("wrapper func args:", *args, **kwargs) if auth_type == "local": username = input("Username:").strip() password = input("Password:").strip() if user == username and passwd == password: print("\033[32;1mUser has passed authentication\033[0m") res = func(*args, **kwargs) # from home print("---after authenticaion ") return res else: exit("\033[31;1mInvalid username or password\033[0m") elif auth_type == "ldap": print("搞毛线ldap,不会。。。。") return wrapper return outer_wrapper def index(): print("welcome to index page") @auth(auth_type="local") # home = wrapper() def home(): print("welcome to home page") return "from home" @auth(auth_type="ldap") def bbs(): print("welcome to bbs page") index() print(home()) #wrapper() bbs()
#! /usr/bin/env python # -*- coding: utf-8 -*- import time def auth(auth_type): print("auth func:",auth_type) def outer_wrapper(func): def wrapper(*args, **kwargs): print("wrapper func args:", *args, **kwargs) print(‘运行前‘) func(*args, **kwargs) print(‘运行后‘) return wrapper return outer_wrapper @auth(auth_type="local") # home = wrapper() def home(): print("welcome to home page") return "from home" home()
7、使用闭包实现装饰器功能
闭包概念:
#! /usr/bin/env python # -*- coding: utf-8 -*- import time def timer(func): #timer(test1) func=test1 def deco(*args,**kwargs): # # 函数嵌套 start_time = time.time() func(*args,**kwargs) # 跨域访问,引用了外部变量func (func实质是函数内存地址) stop_time = time.time() print "running time is %s"%(stop_time-start_time) return deco # 内层函数作为外层函数返回值 def test(name): print "in the test2",name time.sleep(2) test = timer(test) # 等价于 ==》 @timer语法糖 test("tom") ‘‘‘ 运行结果: in the test2 tom running time is 2.00302696228 ‘‘‘
1、什么是生成器
2、定义
3、生成器哪些场景应用
import time t1 = time.time() g = (i for i in range(100000000)) t2 = time.time() lst = [i for i in range(100000000)] t3 = time.time() print(‘生成器时间:‘,t2 - t1) # 生成器时间: 0.0 print(‘列表时间:‘,t3 - t2) # 列表时间: 5.821957349777222
4、生成器的作用
print( [i*2 for i in range(10)] ) #列表生成式: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] print( (i*2 for i in range(10)) ) #生 成 器: <generator object <genexpr> at 0x005A3690>
g = (i*2 for i in range(10)) print( g.__next__() ) # 0 print( g.__next__() ) # 2
5、生成器工作原理
6、yield生成器运行机制
def fib(max_num): a,b = 1,1 while a < max_num: yield b a,b=b,a+b g = fib(10) #生成一个生成器:[1,2, 3, 5, 8, 13] print(g.__next__()) #第一次调用返回:1 print(list(g)) #把剩下元素变成列表:[2, 3, 5, 8, 13]
7、yield实现单线程下的并发效果
def consumer(name): print("%s 准备吃包子啦!" %name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了!" %(baozi,name)) c = consumer("Tom") c.__next__() b1 = "韭菜馅包子" c.send(b1) # c.send(b1)作用: # c.send()的作用是给yied的传递一个值,并且每次调用c.send()的同时自动调用一次__next__ ‘‘‘运行结果: Tom 准备吃包子啦! 包子[韭菜馅包子]来了,被[Tom]吃了! ‘‘‘
import time def consumer(name): print("%s 准备吃包子啦!" %name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了!" %(baozi,name)) def producer(name): c = consumer(‘A‘) c2 = consumer(‘B‘) c.__next__() c2.__next__() print("老子开始准备做包子啦!") for i in range(10): time.sleep(1) print("做了2个包子!") c.send(i) c2.send(i) producer("alex") ‘‘‘运行结果: A 准备吃包子啦! B 准备吃包子啦! 老子开始准备做包子啦! 做了2个包子! 包子[0]来了,被[A]吃了! 包子[0]来了,被[B]吃了! 做了2个包子! 包子[1]来了,被[A]吃了! 包子[1]来了,被[B]吃了! 做了2个包子! 包子[2]来了,被[A]吃了! 包子[2]来了,被[B]吃了! 做了2个包子! 包子[3]来了,被[A]吃了! 包子[3]来了,被[B]吃了! 做了2个包子! 包子[4]来了,被[A]吃了! 包子[4]来了,被[B]吃了! 做了2个包子! 包子[5]来了,被[A]吃了! 包子[5]来了,被[B]吃了! ‘‘‘
1、什么是迭代器
2、定义:
3、迭代器和可迭代对象
for循环的对象都是可迭代的(Iterable)类型;next()函数的对象都是迭代器(Iterator)类型,它们表示一个惰性计算的序列;list、dict、str等是可迭代的但不是迭代器,不过可以通过iter()函数获得一个Iterator对象。for循环本质上就是通过不断调用next()函数实现的4、迭代器的两个方法
a = iter([1,2,]) #生成一个迭代器 print(a.__next__()) print(a.__next__()) print(a.__next__()) #在这一步会引发 “StopIteration” 的异常
5、判断是迭代器和可迭代对象
注:列表,元组,字典是可迭代的但不是迭代器
from collections import Iterable print(isinstance([],Iterable)) #True print(isinstance({},Iterable)) #True print(isinstance((),Iterable)) #True print(isinstance("aaa",Iterable)) #True print(isinstance((x for x in range(10)),Iterable)) #True
6、列表不是迭代器,只有生成器是迭代器
from collections import Iterator t = [1,2,3,4] print(isinstance(t,Iterator)) #False t1 = iter(t) print(isinstance(t1,Iterator)) #True
7、自定义迭代器
#! /usr/bin/env python # -*- coding: utf-8 -*- class MyRange(object): def __init__(self, n): self.idx = 0 self.n = n def __iter__(self): return self def next(self): if self.idx < self.n: val = self.idx self.idx += 1 return self.n[val] else: raise StopIteration() l = [4,5,6,7,8] obj = MyRange(l) print obj.next() # 4 print obj.next() # 5 print obj.next() # 6
8、迭代器与生成器
#! /usr/bin/env python # -*- coding: utf-8 -* l = [1,2,3,4,5] # 列表是一个可迭代对象,不是一个迭代器 print dir(l) # 所以 l 中有 __iter__() 方法,没有 __next__()方法 iter_obj = l.__iter__() # __iter__()方法返回迭代器对象本身(这个迭代器对象就会有 next 方法了) print ‘###################################\n‘ print iter_obj.next() # 1 print iter_obj.next() # 2 print iter_obj.next() # 3
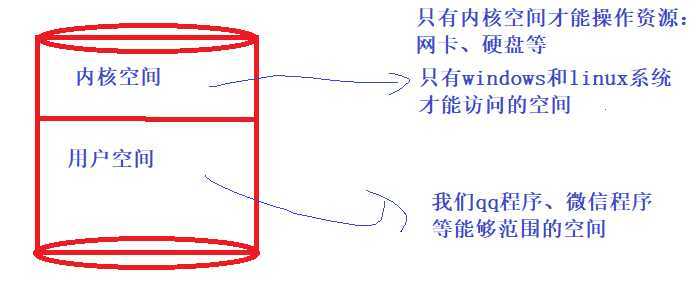
1、什么是进程(process)?(进程是资源集合)
2、进程是资源分配的最小单位( 内存、cpu、网络、io)
3、一个运行起来的程序就是一个进程
CPU分时
进程如何通信
为什么需要进程池
2、定义:进程是资源分配最小单位
3、进程并发性:
4、线程并发性:
5、有了进程为什么还要线程?
1.进程优点:
2. 进程的两个重要缺点
6、什么是线程(thread)(线程是操作系统最小的调度单位)
7、进程和线程的区别
8、进程和程序的区别
Python多线程编程中常用方法:
GIL全局解释器锁:
线程锁(互斥锁):
1、线程2种调用方式:直接调用, 继承式调用
import threading import time def sayhi(num): # 定义每个线程要运行的函数 print("running on number:%s" % num) time.sleep(3) #1、target=sayhi :sayhi是定义的一个函数的名字 #2、args=(1,) : 括号内写的是函数的参数 t1 = threading.Thread(target=sayhi, args=(1,)) # 生成一个线程实例 t2 = threading.Thread(target=sayhi, args=(2,)) # 生成另一个线程实例 t1.start() # 启动线程 t2.start() # 启动另一个线程 print(t1.getName()) # 获取线程名 print(t2.getName())
import threading import time class MyThread(threading.Thread): def __init__(self,num): threading.Thread.__init__(self) self.num = num def run(self):#定义每个线程要运行的函数 print("running on number:%s" %self.num) time.sleep(3) if __name__ == ‘__main__‘: t1 = MyThread(1) t2 = MyThread(2) t1.start() t2.start()
2、for循环同时启动多个线程
import threading import time def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) for i in range(50): t = threading.Thread(target=sayhi,args=(‘t-%s‘%i,)) t.start()
3、t.join(): 实现所有线程都执行结束后再执行主线程
import threading import time start_time = time.time() def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) t_objs = [] #将进程实例对象存储在这个列表中 for i in range(50): t = threading.Thread(target=sayhi,args=(‘t-%s‘%i,)) t.start() #启动一个线程,程序不会阻塞 t_objs.append(t) print(threading.active_count()) #打印当前活跃进程数量 for t in t_objs: #利用for循环等待上面50个进程全部结束 t.join() #阻塞某个程序 print(threading.current_thread()) #打印执行这个命令进程 print("----------------all threads has finished.....") print(threading.active_count()) print(‘cost time:‘,time.time() - start_time)
4、setDaemon(): 守护线程,主线程退出时,需要子线程随主线程退出
import threading import time start_time = time.time() def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep(3) for i in range(50): t = threading.Thread(target=sayhi,args=(‘t-%s‘%i,)) t.setDaemon(True) #把当前线程变成守护线程,必须在t.start()前设置 t.start() #启动一个线程,程序不会阻塞 print(‘cost time:‘,time.time() - start_time)
5、GIL锁和用户锁(Global Interpreter Lock 全局解释器锁)
import time import threading lock = threading.Lock() #1 生成全局锁 def addNum(): global num #2 在每个线程中都获取这个全局变量 print(‘--get num:‘,num ) time.sleep(1) lock.acquire() #3 修改数据前加锁 num -= 1 #4 对此公共变量进行-1操作 lock.release() #5 修改后释放
在有GIL的情况下执行 count = count + 1 会出错原因解析,用线程锁解决方法
# 1)第一步:count = 0 count初始值为0 # 2)第二步:线程1要执行对count加1的操作首先申请GIL全局解释器锁 # 3)第三步:调用操作系统原生线程在操作系统中执行 # 4)第四步:count加1还未执行完毕,时间到了被要求释放GIL # 5)第五步:线程1释放了GIL后线程2此时也要对count进行操作,此时线程1还未执行完,所以count还是0 # 6)第六步:线程2此时拿到count = 0后也要对count进行加1操作,假如线程2执行很快,一次就完成了 # count加1的操作,那么count此时就从0变成了1 # 7)第七步:线程2执行完加1后就赋值count=1并释放GIL # 8)第八步:线程2执行完后cpu又交给了线程1,线程1根据上下文继续执行count加1操作,先拿到GIL # 锁,完成加1操作,由于线程1先拿到的数据count=0,执行完加1后结果还是1 # 9)第九步:线程1将count=1在次赋值给count并释放GIL锁,此时连个线程都对数据加1,但是值最终是1
1 >> lock = threading.Lock() #定义一把锁 2 >> lock.acquire() #对数据操作前加锁防止数据被另一线程操作 3 >> lock.release() #对数据操作完成后释放锁
6、死锁
from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print(‘\033[41m%s 拿到A锁\033[0m‘ %self.name) mutexB.acquire() print(‘\033[42m%s 拿到B锁\033[0m‘ %self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print(‘\033[43m%s 拿到B锁\033[0m‘ %self.name) time.sleep(2) mutexA.acquire() print(‘\033[44m%s 拿到A锁\033[0m‘ %self.name) mutexA.release() mutexB.release() if __name__ == ‘__main__‘: for i in range(2): t=MyThread() t.start() # 运行结果:输出下面结果后程序卡死,不再向下进行了 # Thread-1 拿到A锁 # Thread-1 拿到B锁 # Thread-1 拿到B锁 # Thread-2 拿到A锁
7、递归锁:lock = threading.RLock() 解决死锁问题
from threading import Thread,Lock,RLock import time mutexA=mutexB=RLock() class MyThread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print(‘%s 拿到A锁‘ %self.name) mutexB.acquire() print(‘%s 拿到B锁‘ %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print(‘%s 拿到B锁‘ % self.name) time.sleep(0.1) mutexA.acquire() print(‘%s 拿到A锁‘ % self.name) mutexA.release() mutexB.release() if __name__ == ‘__main__‘: for i in range(5): t=MyThread() t.start() # 下面是运行结果:不会产生死锁 # Thread-1 拿到A锁 # Thread-1 拿到B锁 # Thread-1 拿到B锁 # Thread-1 拿到A锁 # Thread-2 拿到A锁 # Thread-2 拿到B锁 # Thread-2 拿到B锁 # Thread-2 拿到A锁 # Thread-4 拿到A锁 # Thread-4 拿到B锁 # Thread-4 拿到B锁 # Thread-4 拿到A锁 # Thread-3 拿到A锁 # Thread-3 拿到B锁 # Thread-3 拿到B锁 # Thread-3 拿到A锁 # Thread-5 拿到A锁 # Thread-5 拿到B锁 # Thread-5 拿到B锁 # Thread-5 拿到A锁
8、Semaphore(信号量)
# import threading,time # def run(n): # semaphore.acquire() # time.sleep(1) # print("run the thread: %s\n" %n) # semaphore.release() # # if __name__ == ‘__main__‘: # semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行 # for i in range(22): # t = threading.Thread(target=run,args=(i,)) # t.start() # # while threading.active_count() != 1: # pass #print threading.active_count() # else: # print(‘----all threads done---‘) # 代码结果说明:这里可以清晰看到运行时0-4是同时运行的没有顺序,而且是前五个, # 表示再semaphore这个信号量的定义下程序同时仅能执行5个线程
9、events总共就只有四个方法
1. event.set() : # 设置标志位 2. event.clear() : # 清除标志位 3. event.wait() : # 等待标志被设定 4. event.is_set() : # 判断标志位是否被设定
import time,threading event = threading.Event() #第一:写一个红绿灯的死循环 def lighter(): count = 0 event.set() #1先设置为绿灯 while True: if count > 5 and count <10: #2改成红灯 event.clear() #3把标志位清了 print("red light is on.....") elif count > 10: event.set() #4再设置标志位,变绿灯 count = 0 else: print("green light is on.....") time.sleep(1) count += 1 #第二:写一个车的死循环 def car(name): while True: if event.is_set(): #设置了标志位代表绿灯 print("[%s] is running"%name) time.sleep(1) else: print(‘[%s] sees red light, waiting......‘%name) event.wait() print(‘[%s] green light is on,start going.....‘%name) light = threading.Thread(target=lighter,) light.start() car1 = threading.Thread(target=car,args=("Tesla",)) car1.start()
import multiprocessing,time,threading #3 被多线程调用的函数 def thread_run(): print(threading.get_ident()) #打印线程id号 time.sleep(2) #2 被多进程调用的函数,以及在这个函数中起一个进程 def run(name): time.sleep(2) print("hello",name) t = threading.Thread(target=thread_run,) #在进程调用的函数中启用一个线程 t.start() #1 一次性启动多个进程 if __name__ == ‘__main__‘: for i in range(10): p = multiprocessing.Process(target=run,args=(‘bob %s‘%i,)) #启用一个多线程 p.start()
from multiprocessing import Process import queue import threading def f(): q.put([42, None, ‘hello‘]) if __name__ == ‘__main__‘: q = queue.Queue() #1 在父进程中定义一个队列实例q # p = threading.Thread(target=f,) #在线程程中就可以相互访问,线程中内存共享 p = Process(target=f,) #2 在父进程中起一个子进程 p,在子进程中使用父进程的q会报错 p.start() print(q.get()) p.join()
from multiprocessing import Process, Queue def f(qq): # 将符进程中的q传递过来叫qq qq.put([42, None, ‘hello‘]) # 此时子进程就可以使用符进程中的q if __name__ == ‘__main__‘: q = Queue() # 使用Queue()在父进程中定义一个队列实例q p = Process(target=f, args=(q,)) # 在父进程中起一个子进程 p,将父进程刚定义的q传递给子进程p p.start() print(q.get()) p.join() # 运行结果: [42, None, ‘hello‘]
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, ‘hello‘]) # 3 子进程发送数据,就像socket一样 print("son process recv:", conn.recv()) conn.close() if __name__ == ‘__main__‘: parent_conn, child_conn = Pipe() # 1 生成一个管道实例,实例一生成就会生成两个返回对象,一个是管道这头,一个是管道那头 p = Process(target=f, args=(child_conn,)) # 2 启动一个子进程将管道其中一头传递给子进程 p.start() print(parent_conn.recv()) # 4 父进程收消息 # prints "[42, None, ‘hello‘]" parent_conn.send(‘i am parent process‘) p.join() # 运行结果: # [42, None, ‘hello‘] # son process recv: i am parent process
from multiprocessing import Process, Manager import os def f(d, l): d[1] = ‘1‘ # 是个进程对字典放入的是同一个值,所以看上去效果不明显 l.append(os.getpid()) # 将这是个进程的进程id放入列表中 if __name__ == ‘__main__‘: with Manager() as manager: # 1 将Manager()赋值给manager d = manager.dict() # 2 定义一个可以在多个进程间可以共享的字典 l = manager.list(range(5)) # 3 定义一个可以在多个进程间可以共享的列表,默认写五个数据 p_list = [] for i in range(10): # 生成是个进程 p = Process(target=f, args=(d, l)) # 将刚刚生成的可共享字典和列表传递给子进程 p.start() p_list.append(p) for res in p_list: res.join() print(d) print(l)
from multiprocessing import Process, Lock def f(l, i): l.acquire() #一个进程要打印数据时先锁定 print(‘hello world‘, i) l.release() #打印完毕后就释放这把锁 if __name__ == ‘__main__‘: lock = Lock() #先生成一把锁 for num in range(5): Process(target=f, args=(lock, num)).start() # 运行结果: # hello world 4 # hello world 0 # hello world 2 # hello world 3 # hello world 1
from multiprocessing import Process,Pool import time,os def foo(i): time.sleep(2) print("in the process",os.getpid()) #打印子进程的pid return i+100 def call(arg): print(‘-->exec done:‘,arg,os.getpid()) if __name__ == ‘__main__‘: pool = Pool(3) #进程池最多允许5个进程放入进程池 print("主进程pid:",os.getpid()) #打印父进程的pid for i in range(10): #用法1 callback作用是指定只有当Foo运行结束后就执行callback调用的函数,父进程调用的callback函数 pool.apply_async(func=foo, args=(i,),callback=call) #用法2 串行 启动进程不在用Process而是直接用pool.apply() # pool.apply(func=foo, args=(i,)) print(‘end‘) pool.close() #关闭pool pool.join() #进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
僵尸进程
#!/usr/bin/env python #coding=utf8 import os, sys, time #产生子进程 pid = os.fork() if pid == 0: #子进程退出 sys.exit(0) #父进程休息30秒 time.sleep(30) # 先产生一个子进程,子进程退出,父进程休息30秒,那就会产生一个僵尸进程
[root@linux-node4 ~]# ps -ef| grep defunct root 110401 96083 0 19:11 pts/2 00:00:00 python defunct.py root 110402 110401 0 19:11 pts/2 00:00:00 [python] <defunct> root 110406 96105 0 19:11 pts/3 00:00:00 grep --color=auto defunct
1、什么是协程(进入上一次调用的状态)
2、协程的好处
3、协程缺点
4、使用yield实现协程相同效果
import time import queue def consumer(name): print("--->starting eating baozi...") while True: new_baozi = yield # 只要遇到yield程序就返回,yield还可以接收数据 print("[%s] is eating baozi %s" % (name, new_baozi)) time.sleep(1) def producer(): r = con.__next__() # 直接调用消费者的__next__方法 r = con2.__next__() # 函数里面有yield第一次加括号调用会变成一个生成器函数不执行,运行next才执行 n = 0 while n < 5: n += 1 con.send(n) # send恢复生成器同时并传递一个值给yield con2.send(n) print("\033[32;1m[producer]\033[0m is making baozi %s" % n) if __name__ == ‘__main__‘: con = consumer("c1") con2 = consumer("c2") p = producer()
5、协程为何能处理大并发1:Greenlet遇到I/O手动切换
from greenlet import greenlet def test1(): print(12) #4 gr1会调用test1()先打印12 gr2.switch() #5 然后gr2.switch()就会切换到gr2这个协程 print(34) #8 由于在test2()切换到了gr1,所以gr1又从上次停止的位置开始执行 gr2.switch() #9 在这里又切换到gr2,会再次切换到test2()中执行 def test2(): print(56) #6 启动gr2后会调用test2()打印56 gr1.switch() #7 然后又切换到gr1 print(78) #10 切换到gr2后会接着上次执行,打印78 gr1 = greenlet(test1) #1 启动一个协程gr1 gr2 = greenlet(test2) #2 启动第二个协程gr2 gr1.switch() #3 首先gr1.switch() 就会去执行gr1这个协程
6、协程为何能处理大并发2:Gevent遇到I/O自动切换
7、Gevent实现简单的自动切换小例子
import gevent def func1(): print(‘\033[31;1m第一次打印\033[0m‘) gevent.sleep(2) # 为什么用gevent.sleep()而不是time.sleep()因为是为了模仿I/O print(‘\033[31;1m第六次打印\033[0m‘) def func2(): print(‘\033[32;1m第二次打印\033[0m‘) gevent.sleep(1) print(‘\033[32;1m第四次打印\033[0m‘) def func3(): print(‘\033[32;1m第三次打印\033[0m‘) gevent.sleep(1) print(‘\033[32;1m第五次打印\033[0m‘) gevent.joinall([ # 将要启动的多个协程放到event.joinall的列表中,即可实现自动切换 gevent.spawn(func1), # gevent.spawn(func1)启动这个协程 gevent.spawn(func2), gevent.spawn(func3), ]) # 运行结果: # 第一次打印 # 第二次打印 # 第三次打印 # 第四次打印 # 第五次打印 # 第六次打印
8、使用Gevent实现并发下载网页与串行下载网页时间比较
from urllib import request import gevent,time from gevent import monkey monkey.patch_all() #把当前程序所有的I/O操作给我单独做上标记 def f(url): print(‘GET: %s‘ % url) resp = request.urlopen(url) data = resp.read() print(‘%d bytes received from %s.‘ % (len(data), url)) #1 并发执行部分 time_binxing = time.time() gevent.joinall([ gevent.spawn(f, ‘https://www.python.org/‘), gevent.spawn(f, ‘https://www.yahoo.com/‘), gevent.spawn(f, ‘https://github.com/‘), ]) print("并行时间:",time.time()-time_binxing) #2 串行部分 time_chuanxing = time.time() urls = [ ‘https://www.python.org/‘, ‘https://www.yahoo.com/‘, ‘https://github.com/‘, ] for url in urls: f(url) print("串行时间:",time.time()-time_chuanxing) # 注:为什么要在文件开通使用monkey.patch_all() # 1. 因为有很多模块在使用I / O操作时Gevent是无法捕获的,所以为了使Gevent能够识别出程序中的I / O操作。 # 2. 就必须使用Gevent模块的monkey模块,把当前程序所有的I / O操作给我单独做上标记 # 3.使用monkey做标记仅用两步即可: 第一步(导入monkey模块): from gevent import monkey 第二步(声明做标记) : monkey.patch_all()
9、通过gevent自己实现单线程下的多socket并发
import gevent from gevent import socket,monkey #下面使用的socket是Gevent的socket,实际测试monkey没用 # monkey.patch_all() def server(port): s = socket.socket() s.bind((‘0.0.0.0‘,port)) s.listen(5) while True: cli,addr = s.accept() gevent.spawn(handle_request,cli) def handle_request(conn): try: while True: data = conn.recv(1024) print(‘recv:‘,data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as e: print(e) finally: conn.close() if __name__==‘__main__‘: server(8001)
import socket HOST = ‘localhost‘ # The remote host PORT = 8001 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"),encoding="utf8").strip() if len(msg) == 0:continue s.sendall(msg) data = s.recv(1024) print(‘Received‘, repr(data)) s.close()
10、协程本质原理
11、epoll处理 I/O 请求原理
12、select处理协程
13、select、epool、pool
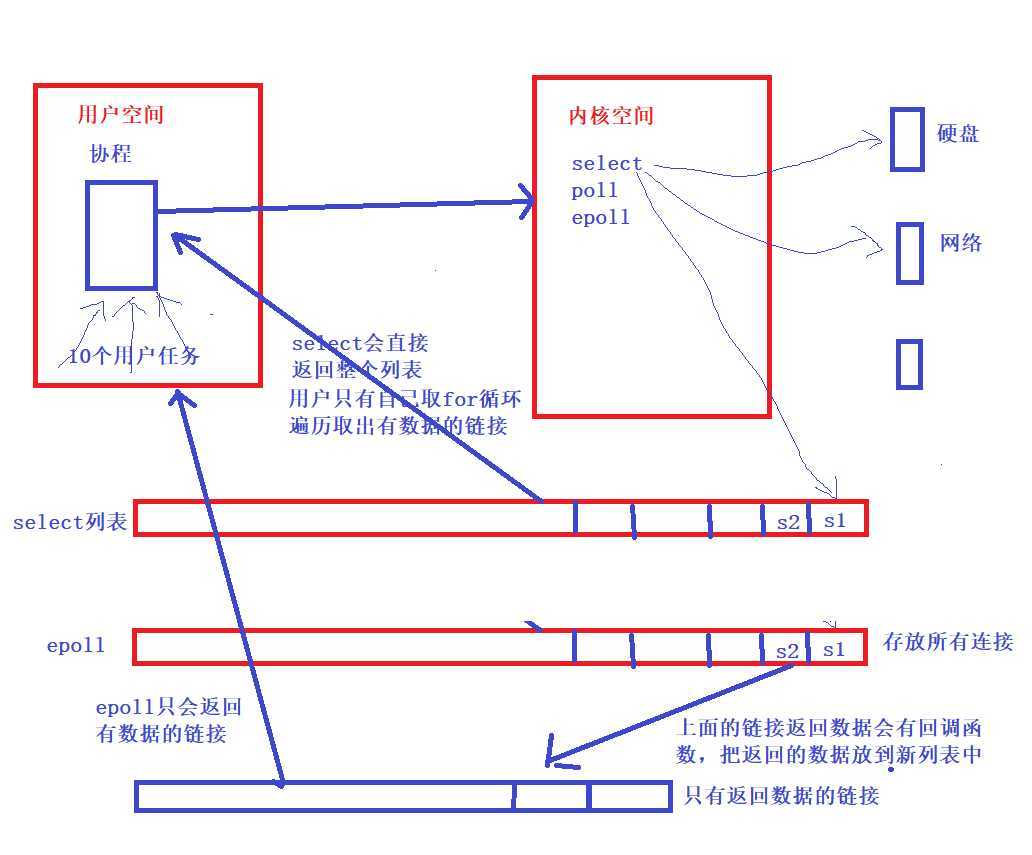
Python进程池和线程池(ThreadPoolExecutor&ProcessPoolExecutor)
1. Executor
2. Future
from concurrent.futures import ThreadPoolExecutor import time def return_future_result(message): time.sleep(2) return message pool = ThreadPoolExecutor(max_workers=2) # 创建一个最大可容纳2个task的线程池 future1 = pool.submit(return_future_result, ("hello")) # 往线程池里面加入一个task future2 = pool.submit(return_future_result, ("world")) # 往线程池里面加入一个task print(future1.done()) # 判断task1是否结束 time.sleep(3) print(future2.done()) # 判断task2是否结束 print(future1.result()) # 查看task1返回的结果 print(future2.result()) # 查看task2返回的结果 # 运行结果: # False # 这个False与下面的True会等待3秒 # True # 后面三个输出都是一起打出来的 # hello # world
import concurrent.futures import urllib.request URLS = [‘http://httpbin.org‘, ‘http://example.com/‘, ‘https://api.github.com/‘] def load_url(url, timeout): with urllib.request.urlopen(url, timeout=timeout) as conn: return conn.read() # We can use a with statement to ensure threads are cleaned up promptly with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor: # Start the load operations and mark each future with its URL # future_to_url = {executor.submit(load_url, url, 60): url for url in URLS} # 这一句相当于下面for循环获取的字典 future_to_url = {} for url in URLS: future_to_url[executor.submit(load_url,url,60)] = url # {‘future对象‘:‘url‘} future对象作为key,url作为value for future in concurrent.futures.as_completed(future_to_url): # as_completed返回已经有返回结果的future对象 url = future_to_url[future] # 通过future对象获取对应的url try: data = future.result() # 获取future对象的返回结果 except Exception as exc: print(‘%r generated an exception: %s‘ % (url, exc)) else: print(‘%r page is %d bytes‘ % (url, len(data)))
from concurrent.futures import ThreadPoolExecutor # 创建线程池 executor = ThreadPoolExecutor(10) def test_function(num1,num2): return "%s + %s = %s"%(num1,num2,num1+num2) result_iterators = executor.map(test_function,[1,2,3],[5,6,7]) for result in result_iterators: print(result) # 1 + 5 = 6 # 2 + 6 = 8 # 3 + 7 = 10
import concurrent.futures import urllib.request URLS = [‘http://httpbin.org‘, ‘http://example.com/‘, ‘https://api.github.com/‘] def load_url(url): with urllib.request.urlopen(url, timeout=60) as conn: return conn.read() # We can use a with statement to ensure threads are cleaned up promptly with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor: future_dic = {} for url, data in zip(URLS, executor.map(load_url, URLS)): print(‘%r page is %d bytes‘ % (url, len(data))) future_dic[url] = data # {‘url‘:‘执行结果‘} url作为key,执行结果作为value # ‘http://httpbin.org‘ page is 13011 bytes # ‘http://example.com/‘ page is 1270 bytes # ‘https://api.github.com/‘ page is 2039 bytes
使用线程池、进程池、协程向多个url并发获取页面数据比较
import requests url_list = [ ‘https://www.baidu.com‘, ‘http://dig.chouti.com/‘, ] for url in url_list: result = requests.get(url) print(result.text)
import requests from concurrent.futures import ProcessPoolExecutor def fetch_request(url): result = requests.get(url) print(result.text) url_list = [ ‘https://www.baidu.com‘, ‘https://www.google.com/‘, #google页面会卡住,知道页面超时后这个进程才结束 ‘http://dig.chouti.com/‘, #chouti页面内容会直接返回,不会等待Google页面的返回 ] if __name__ == ‘__main__‘: pool = ProcessPoolExecutor(10) # 创建线程池 for url in url_list: pool.submit(fetch_request,url) # 去线程池中获取一个进程,进程去执行fetch_request方法 pool.shutdown(False)
import requests from concurrent.futures import ThreadPoolExecutor def fetch_request(url): result = requests.get(url) print(result.text) url_list = [ ‘https://www.baidu.com‘, ‘https://www.google.com/‘, #google页面会卡住,知道页面超时后这个进程才结束 ‘http://dig.chouti.com/‘, #chouti页面内容会直接返回,不会等待Google页面的返回 ] pool = ThreadPoolExecutor(10) # 创建一个线程池,最多开10个线程 for url in url_list: pool.submit(fetch_request,url) # 去线程池中获取一个线程,线程去执行fetch_request方法 pool.shutdown(True) # 主线程自己关闭,让子线程自己拿任务执行
from concurrent.futures import ThreadPoolExecutor import requests def fetch_async(url): response = requests.get(url) return response.text def callback(future): print(future.result()) url_list = [‘http://www.github.com‘, ‘http://www.bing.com‘] pool = ThreadPoolExecutor(5) for url in url_list: v = pool.submit(fetch_async, url) v.add_done_callback(callback) pool.shutdown(wait=True)
import gevent import requests from gevent import monkey monkey.patch_all() # 这些请求谁先回来就先处理谁 def fetch_async(method, url, req_kwargs): response = requests.request(method=method, url=url, **req_kwargs) print(response.url, response.content) # ##### 发送请求 ##### gevent.joinall([ gevent.spawn(fetch_async, method=‘get‘, url=‘https://www.python.org/‘, req_kwargs={}), gevent.spawn(fetch_async, method=‘get‘, url=‘https://www.google.com/‘, req_kwargs={}), gevent.spawn(fetch_async, method=‘get‘, url=‘https://github.com/‘, req_kwargs={}), ])
原文:https://www.cnblogs.com/yangmaosen/p/12452827.html
