上一部分介绍了机器学习的本质是找到一个最优化的映射关系,也就是函数/模型。接下来几章我会陆续给大家介绍AI的数学基础,本章将首先给大家介绍线性代数如何应用于AI。
一元线性函数
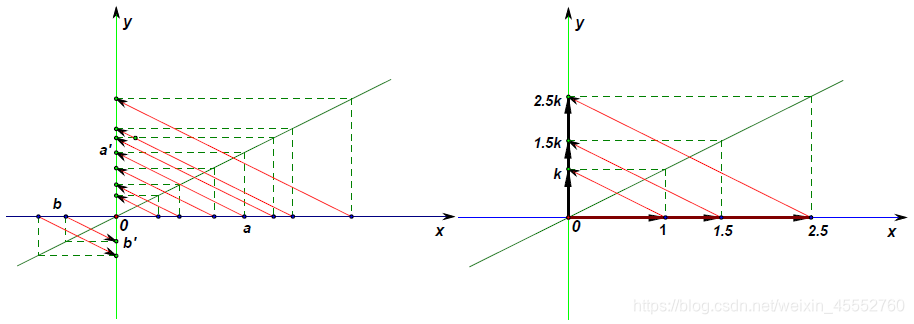
在中学的初等数学里,把函数\(f(x)=kx+b\) (\(k,b\)是不变量),称为一元线性函数,因为在平面直角坐标系中这个函数的图形就是一条线,就是变量(包括自变量和因变量)之间的映射关系描述为一条线,把这种函数形象的称之为“线性”函数(如下图\(L_1\));如果\(b=0\),则这个函数就变成了\(f(x)=kx\)的形式,也即是一条过原点的直线,如下图\(L_2\)。此时的变量之间的映射是单个数值之间的映射,这类单独的数我们称之为标量(scalar)。
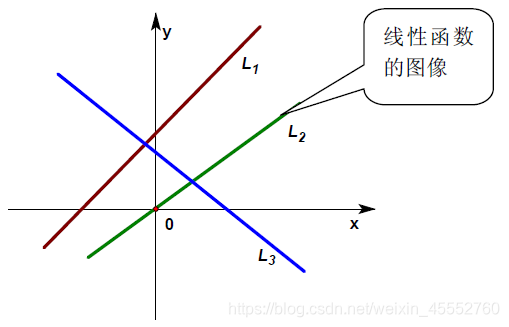
在大学的代数里,为了线性函数的进一步推广(如推广至双线性函数、多线性函数、线性空间、线性泛函,... ...),把一元线性函数\(f(x)=kx+b\)的\(b\)舍掉,成了\(f(x)=kx\)的形式。即只有过原点的最简单的直线\(f(x)=kx\)才能被称为一元线性函数。因为只有这样才能满足线性函数性质。
线性函数性质:可加性和比例性
1)可加性:即如果函数\(f(x)\)是线性的,则有:和的函数等于函数的和。
\(f(x_1+x_2)=f(x_1)+f(x_2)\)
2)比例性:也叫做齐次性,数乘性或均匀性,即如果函数\(f(x)\)是线性的,那么有:比例的函数等于函数的比例;或者说自变量缩放,函数也同等比例地缩放。
\(f(kx)=kf(x)\) 其中\(k\)是常数。
下图左右分别描述了最简单的标量映射(\(k>0\))及其基本性质:
多元线性函数
事实上,高等数学里的线性概念正是从最简单的比例函数进行推广的,在大学里所学习的线性代数里的线性函数概念被推广成一个多元线性方程组所表示的映射关系。如方程组:
这与我们定义的\(f(x)=kx\)形式相去甚远,使形式统一,我们对变量进行了重新定义:
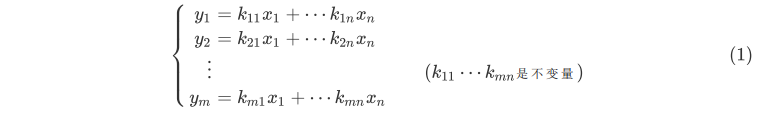
1)初等数学的线性函数的自变量由一个数\(x\)扩展为一个竖排的数组\(\left[ \begin{matrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{matrix} \right]\),应变量是一个数\(y\)也扩展
定义为一个竖排的数组\(\left[ \begin{matrix} y_1 \\ y_2 \\ \vdots \\ y_m \end{matrix} \right]\),这些\(n\)元数组和\(m\)元数组称之为列向量(vector)。
2)初等线性函数的比例系数\(k\)扩展为由所有\(k_{ij}\)构成的一个的数的方阵,称之为系数矩阵(matrix):
\[\left[ \begin{matrix} k_{11} & k_{12} & \cdots & k_{1n}\\ k_{21} & k_{22} & \cdots & k_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ k_{m1} & k_{m2} & \cdots & k_{mn} \end{matrix} \right]\]
小结
标量、向量、矩阵、张量之间的联系
标量(scalar)
一个标量表示一个单独的数,它不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。我们用斜体表示标量。标量通常被赋予小写的变量名称。向量(vector)
一个向量表示一组有序排列的数。通过次序中的索引,我们可以确定每个单独的数。通常我们赋予向量粗体的小写变量名称,比如xx。向量中的元素可以通过带脚标的斜体表示。向量\(X\)的第一个元素是\(X_1\),第二个元素是\(X_2\),以此类推。我们也会注明存储在向量中的元素的类型(实数、虚数等)。矩阵(matrix)
矩阵是具有相同特征和纬度的对象的集合,表现为一张二维数据表。其意义是一个对象表示为矩阵中的一行,一个特征表示为矩阵中的一列,每个特征都有数值型的取值。通常会赋予矩阵粗体的大写变量名称,比如\(A\)。张量(tensor)
在某些情况下,我们会讨论坐标超过两维的数组。一般地,一个数组中的元素分布在若干维坐标的规则网格中,我们将其称之为张量。使用 \(A\) 来表示张量“A”。张量\(A\)中坐标为\((i,j,k)\)的元素记作\(A_{(i,j,k)}\)。四者之间关系
标量是0阶张量,向量是一阶张量。举例:
标量就是知道棍子的长度,但是你不会知道棍子指向哪儿。
向量就是不但知道棍子的长度,还知道棍子指向前面还是后面。
张量就是不但知道棍子的长度,也知道棍子指向前面还是后面,还能知道这棍子又向上/下和左/右偏转了多少。张量与矩阵的区别
- 从代数角度讲, 矩阵它是向量的推广。向量可以看成一维的“表格”(即分量按照顺序排成一排), 矩阵是二维的“表格”(分量按照纵横位置排列), 那么\(n\)阶张量就是所谓的\(n\)维的“表格”。 张量的严格定义是利用线性映射来描述。
- 从几何角度讲, 矩阵是一个真正的几何量,也就是说,它是一个不随参照系的坐标变换而变化的东西。向量也具有这种特性。
- 张量可以用3×3矩阵形式来表达。
- 表示标量的数和表示向量的三维数组也可分别看作1×1,1×3的矩阵。
3)然后定义一种系数矩阵与向量(矩阵)相乘的运算法则,则式(1)可以改写成如下形式:
\[\left[ \begin{matrix} y_1 \\ y_2 \\ \vdots \\ y_m \end{matrix} \right]=\left[ \begin{matrix} k_{11} & k_{12} & \cdots & k_{1n}\\ k_{21} & k_{22} & \cdots & k_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ k_{m1} & k_{m2} & \cdots & k_{mn} \end{matrix} \right]\left[ \begin{matrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{matrix} \right] \tag {2}\]
式(2)与(1)等价。
矩阵和向量相乘结果
若使用爱因斯坦求和约定(Einstein summation convention),矩阵\(A\), \(B\)相乘得到矩阵\(C\)可以用下式表示:
\[ a_{ik}*b_{kj}=c_{ij} \]
其中,\(a_{ik}\), \(b_{kj}\), \(c_{ij}\)分别表示矩阵\(A, B, C\)的元素,\(k\)出现两次,是一个哑变量(Dummy Variables)表示对该参数进行遍历求和。
而矩阵和向量相乘可以看成是矩阵相乘的一个特殊情况,例如:矩阵\(B\)是一个\(n \times 1\)的矩阵。
4)式(2)可进一步简写为:
\(y=f(X)=KX\)
其中:\[y=f(X)=\left[ \begin{matrix} y_1 \\ y_2 \\ \vdots \\ y_m \end{matrix} \right], K=\left[ \begin{matrix} k_{11} & k_{12} & \cdots & k_{1n}\\ k_{21} & k_{22} & \cdots & k_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ k_{m1} & k_{m2} & \cdots & k_{mn} \end{matrix} \right], X=\left[ \begin{matrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{matrix} \right]。 \]
到此为止,我们终于看到初等线性函数和高等线性函数的概念在形式上得到了统一,同时也引入了标量、向量、矩阵、张量等概念,这些在机器学习的计算中都是最常用的基本单元。那么,这些基本单元究竟应用于机器学习的什么地方呢?下面插入一个例子
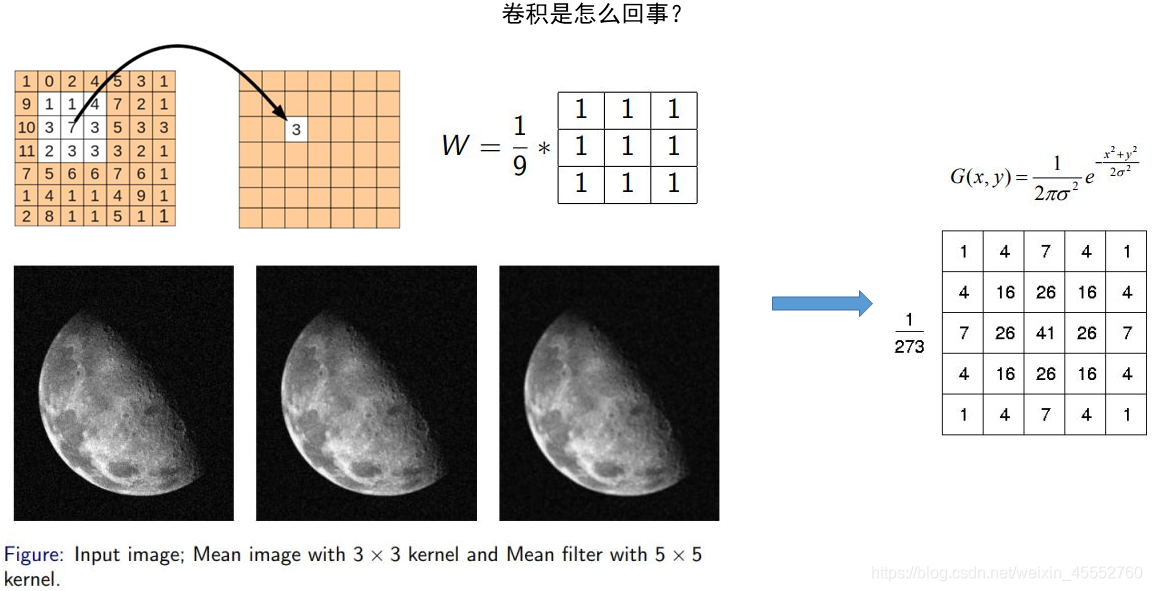
例子:卷积是怎么回事?
在最初接触图像处理的时候,我们一般是从图像的平滑(高低通滤波等)开始的,如下图所示:
如上图的平滑,一个典型的8领域平滑,其结果中的每个值都来源于原对应位置和其周边8个元素与一个\(3 X 3\)矩阵的乘积,也就相当于对原矩阵,按照顺序将各区域元素与\(W\)矩阵相乘,\(W\)被称作核(Kernel, \(3X3\))。
也就是,这个核对图像进行操作,相当于对图像进行了低通滤波(如图中左下角月球图片,亮暗交界的地方变得平滑)。因此这个核也被称为滤波器,整个操作过程按照概念称为卷积。
扩展来讲,对二维图像的滤波操作可以写成卷积,比如常见的高斯滤波、拉普拉斯滤波(算子)等。
图像识别中的卷积
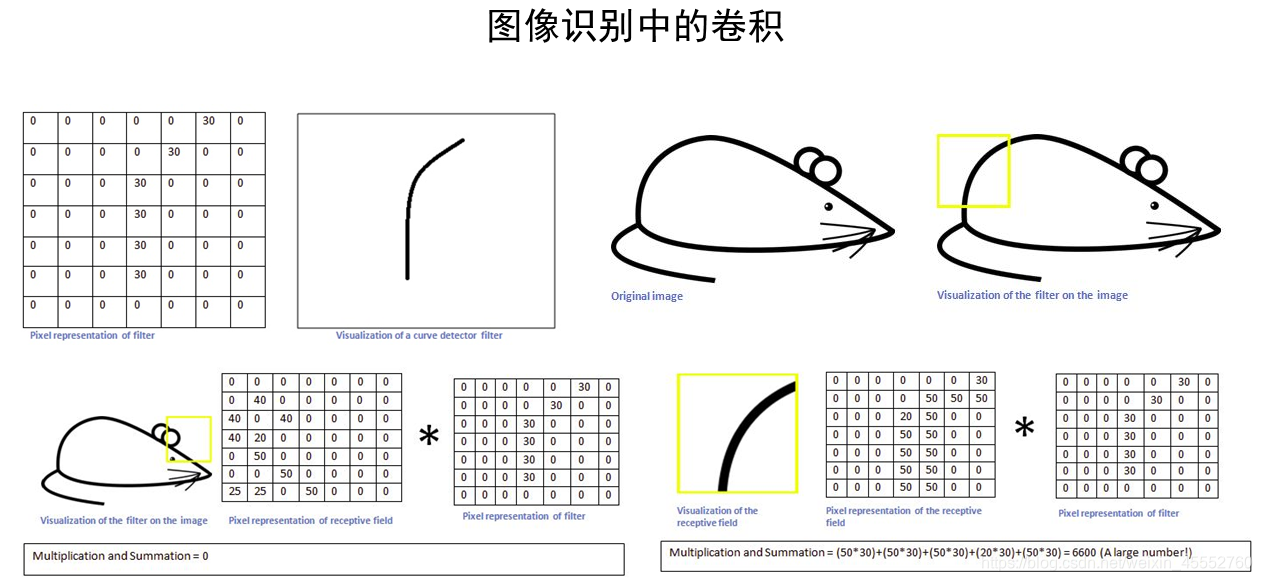
不如我们预想一个识别问题:我们要识别图像中的某种特定曲线,也就是说,这个滤波器要对这种曲线有很高的输出,对其他形状则输出很低,这也就像是神经元的激活。
想要识别一条曲线(左上),对应用一个矩阵表示。
假设上面的核(滤波器)按照卷积顺序沿着右上图移动。
那么当它移动到尾部黄色方框的位置时,按照矩阵操作,将这个区域的图像像素值与滤波器相乘,我们得到一个很大的值(6600)(右下),类似激活了神经元,识别出是我们想要找的曲线。
而当这个滤波器移动到其他区域,如耳部黄色方框,我们得到一个相对很小的值(左下),表明神经元没有激活,该线段不是我们想要的曲线。
对整个原图进行一次卷积,得到的结果中,在那个特定曲线和周边区域,值就很高,在其他区域,值相对低。这就是一张激活图。对应的高值区域就是我们所要检测曲线的位置。
扩展一下,通俗语言来说,当我们判别整个图像是不是小鼠的时候,应用检测各种形状的卷积核(如检测耳朵的圆圈、眼睛的黑点、胡须的直线等),再综合这些卷积核的信息,就得到图片各个部位的激活图,如果符合小鼠的图片,代表该图片是小鼠图片,否则就不是激活图片。
若对VGG16网络的各层卷积核进行可视化(可视化工具toolbox:yosinski/deep-visualization-toolbox),结果如下所示:
conv1
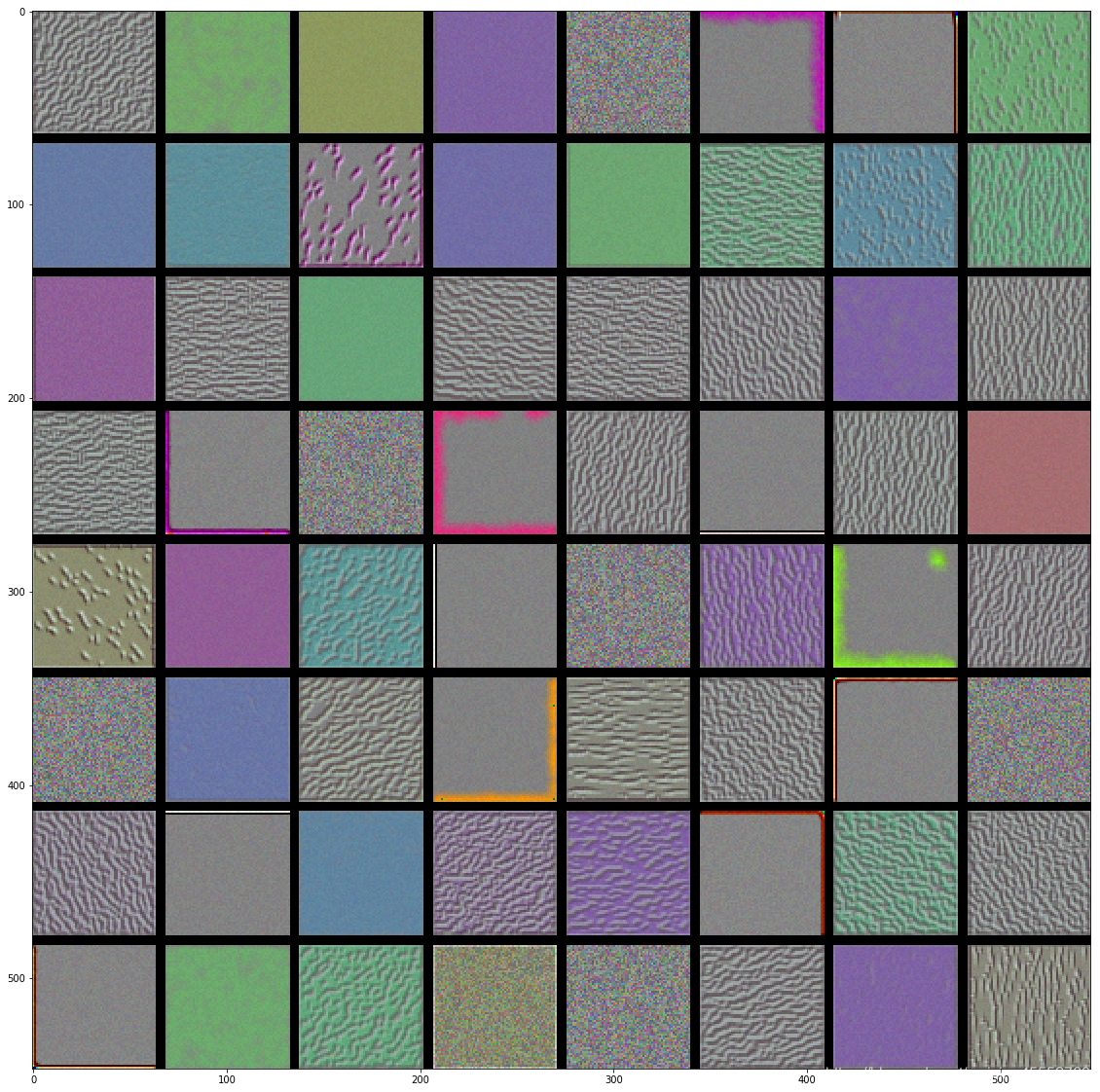
conv2
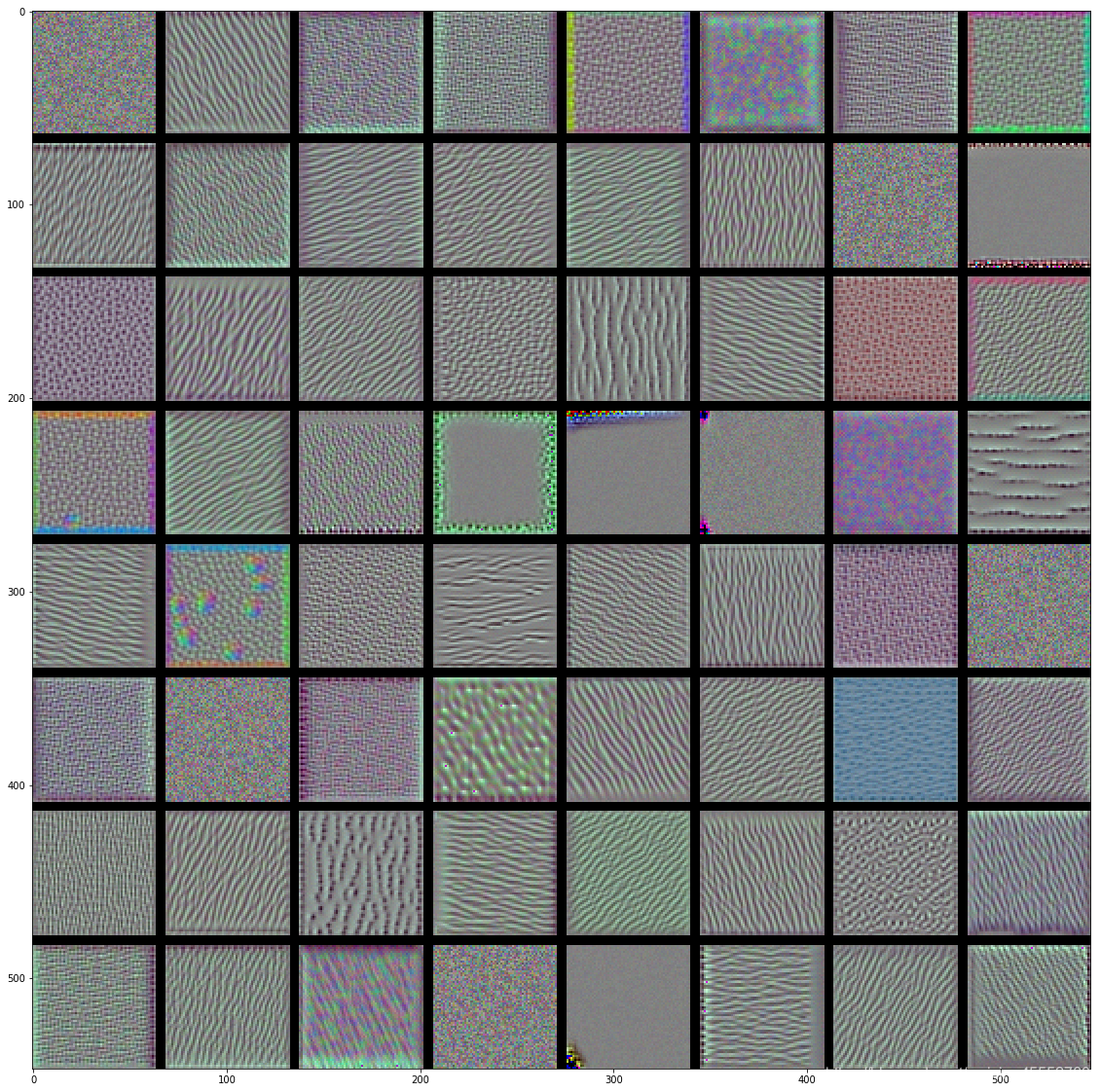
conv3
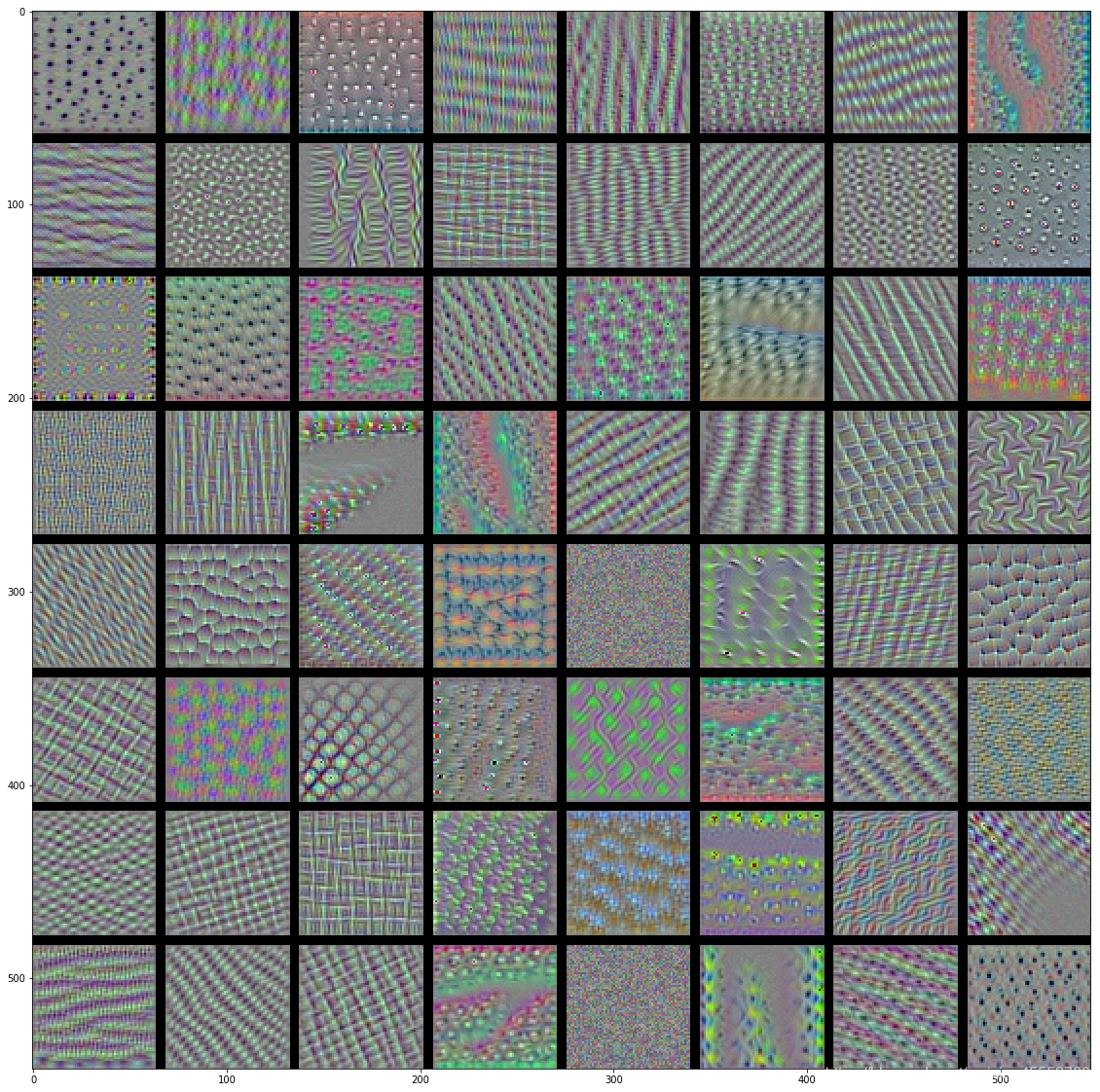
conv4
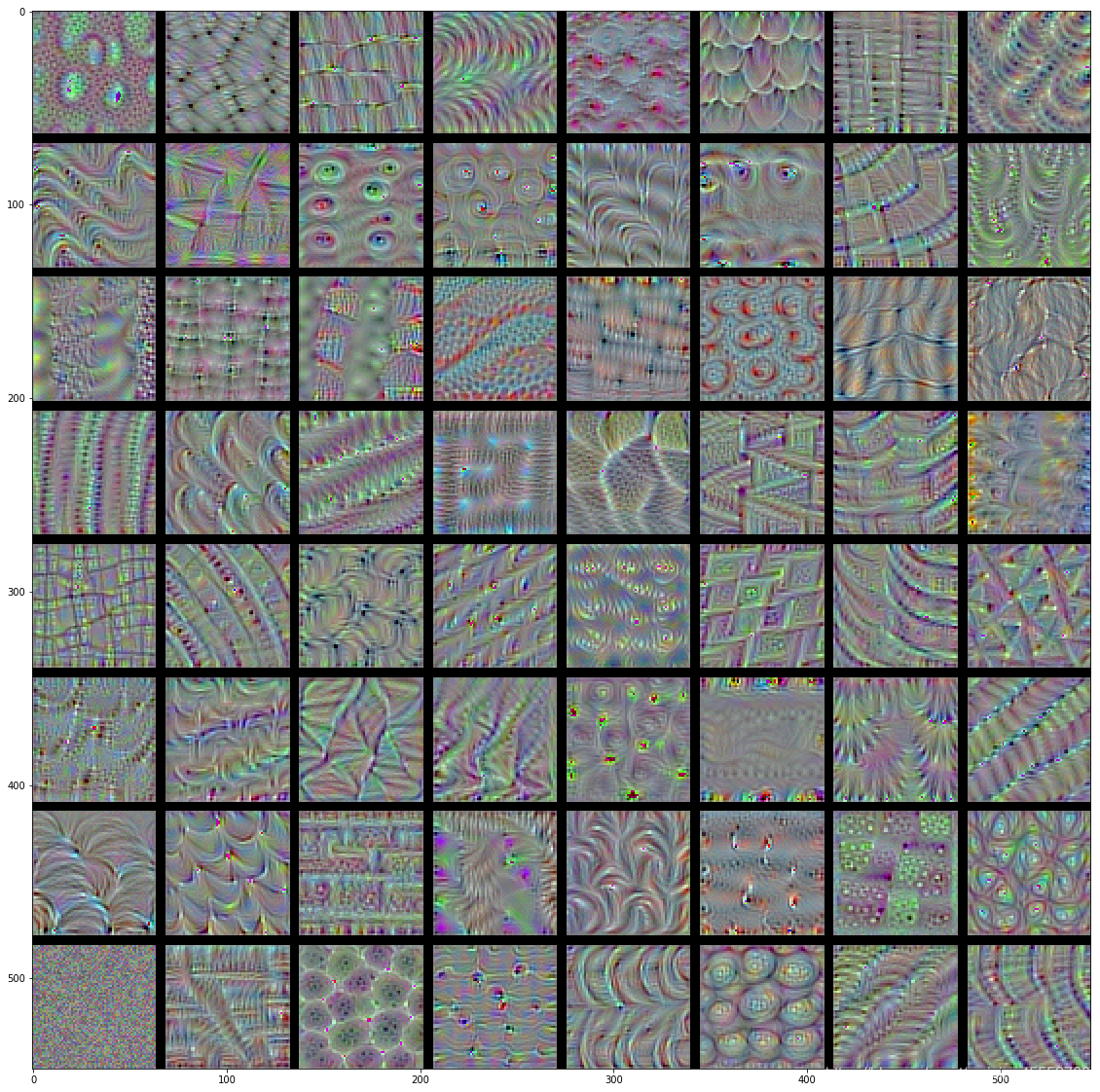
conv5

VGG16卷积核:
- 低层的卷积核似乎对颜色,边缘信息感兴趣。
- 越高层的卷积核,感兴趣的内容越抽象(非常魔幻啊),也越复杂。
- 高层的卷积核感兴趣的图像越来越难通过梯度上升获得(conv5有很多还是随机噪声的图像)
针对这个图像识别的例子,大家可能会有一个疑问:如果我们用一个复杂一点的卷积核,囊括图中小鼠所有部位的特征,这样一次性解决,这样不好么?非得整这么复杂????
答案是阔以的,但是\(\cdots\),你只能识别这一张图片,其他变换的形态的图片(如,没有尾巴的、大耳朵的等等)都是不能识别的,那这样最终的函数模型不是我们想要的,这样的模型它“太聪明”了,它能记录它见过的特定图片的所有细节,但是不认识新的同类图片,这种情况下,我们称之为模型过拟合了,没有泛化性能。
上文图像识别中,我们引出了过拟合问题,本部分将以例子形式进一步说明什么是过拟合以及处理方案中的数学问题:范数。
什么是过拟合问题?

假设我们现在买了一个机器人(如上图),想让它学会区分汉字,如下图:前5个字属于一个类别,后5个字属于第二个类别。这十个字是目前拥有的唯一训练数据。

现在,不幸的是,机器人“太聪明”了,它有足够大的内存来记住5个字符,在看到所有的10个字后,机器人学会了对它们进行分类的方法:它完全记住了前5个字。只要不在记住的前5个字中,机器人就会将该字归类为第二类。这种方法对10个训练数据来说是很有效的,可以达到100%的准确率。但是,当提供一个新的字进行判断时:

该字的正确类标为第一类。但由于它从未出现在训练数据中,机器人以前从未见过它。根据它的处理方案,它会把这个字放到第二类,这实际上是不符合类别的特性模式的:

对人来说这种分布模式是很明显的:属于第一类的字都有相同的部首“扌”,但是机器人失败了。这就是过拟合问题:模型的复杂度太高(也就是太聪明了),能记住它见过的每一个细节,但是应对新事物的能力不行,没有泛化能力。
你可能会说,这是因为训练数据量太小了,没见过怎么会认识。是的,从某种角度可以这么说,但是带扌的字很多,不可能全都涵盖,而且,根据小学老师强调的,我们要举一反三,不能死记硬背????
So,我们放大招,对机器人进行了改进:一顿操作猛如虎。现在好了,一顿暴揍干到失忆??,并且记忆芯片受损,和dong~哥一样变成了脸盲,对于见过的字只能记住特性。

再次让机器人通过查看所有10个字再次进行训练,并且一遍遍强迫它重复直到达到相同的准确度。在记忆受损的情况下被强迫记忆,过程是缓慢而痛苦的,因为它根本认不全那5个字,它只能寻找一个更简单的模式,终于在重复1w遍之后,开窍了,它发现了同类中的一些共同特性(因为每次都出现,强化记忆),就是第一类中共有的“扌”。
这个机器人(模型)简化的过程,在机器学习中叫作正则化(regularization),而在正则化过程中通常使用\(L_1\)范数及\(L_2\)范数等对模型进行简化:它暴揍你的机器(模型),使其变“笨”。因此,它不能再死记硬背内容,而是必须从数据中寻找更简单的模式。如,当机器人记忆完整5个字时,它的“大脑”存储了一个大小为5的向量:\([把,打,扒,捕,拉]\)。敲打(正则化)之后,只能记住共同的分布模式,“大脑”存储新的向量:\([扌,0,0,0,0]\),显然,这是一个更为稀疏的向量。当机器人(模型)发现新字中与“扌”匹配时,都会分为第一类,而其余的分为第二类。
上硬汉——范叔
上文引入了动不动就一顿揍的正则化/范数, 我们以上文线性函数\[y=f(X)=KX\]为例来看看范叔范数到底哪儿硬。

什么是范数?
范数有很多种,它是根据性质来定义的,满足以下三条性质的都可以称为范数:
设\(V\)是数域\(P\)上的线性空间,\(\Vert\vec{\alpha}\Vert\)是以\(V\)中的向量\(\vec{\alpha}\)为自变量的非负实值函数,如果它满足以下三个条件:
(1)非负性:当\(\vec{\alpha}\neq0\)时,\(\Vert\vec{\alpha}\Vert>0\);当\(\vec{\alpha}=0\)时,\(\Vert\vec{\alpha}\Vert=0\);
(2)齐次性:对任意\(k\in P\),\(\vec{\alpha}\in V\),有\(\Vert k\vec{\alpha}\Vert=\vert k\vert\Vert\vec{\alpha}\Vert\);
(3)三角不等式:对任意\(\vec{\alpha},\vec{\beta}\in V\),有\(\Vert\vec{\alpha}+\vec{\beta}\Vert\leq\Vert\vec{\alpha}\Vert+\Vert\vec{\beta}\Vert\),
则称\(\Vert\vec{\alpha}\Vert\)为向量\(\vec{\alpha}\)的范数,并定义了范数的线性空间为赋范线性空间。
数学的定义真的是\(\cdots\)太抽象了????,不用管它,我们使用直观实际的例子进行定义:
向量的范数(norm)
定义一个向量为:\(\vec{a}=[-5, 6, 8, -10]\)。任意一组向量设为\(\vec{x}=(x_1,x_2,...,x_N)\)。其不同范数求解如下:
\[ \Vert\vec{x}\Vert_1=\sum_{i=1}^N\vert{x_i}\vert \tag {3} \]
\[ \Vert\vec{x}\Vert_2=\sqrt{\sum_{i=1}^N{\vert{x_i}\vert}^2} \tag {4} \]
\[ \Vert\vec{x}\Vert_{-\infty}=\min{|{x_i}|} \tag {5} \]
\[ \Vert\vec{x}\Vert_{+\infty}=\max{|{x_i}|} \tag {6} \]
\[ L_p=\Vert\vec{x}\Vert_p=\sqrt[p]{\sum_{i=1}^{N}|{x_i}|^p} \tag {6} \]
扩展——矩阵的范数
定义一个矩阵\(A=[-1, 2, -3; 4, -6, 6]\)。 任意矩阵定义为:\(A_{m\times n}\),其元素为 \(a_{ij}\)。
矩阵的范数定义为
\[ \Vert{A}\Vert_p :=\sup_{x\neq 0}\frac{\Vert{Ax}\Vert_p}{\Vert{x}\Vert_p} \tag {7} \]
当向量取不同范数时, 相应得到了不同的矩阵范数。
- 矩阵的1范数(列范数):矩阵的每一列上的元
素绝对值先求和,再从中取个最大的,(列和最大),上述矩阵\(A\)的1范数先得到\([5,8,9]\),再取最大的最终结果就是:9。
\[ \Vert A\Vert_1=\max_{1\le j\le n}\sum_{i=1}^m|{a_{ij}}| \tag {8} \]
- 矩阵的2范数:矩阵\(A^TA\)的最大特征值开平方根,上述矩阵\(A\)的2范数得到的最终结果是:10.0623。
\[ \Vert A\Vert_2=\sqrt{\lambda_{max}(A^T A)} \tag {9} \]
其中, \(\lambda_{max}(A^T A)\) 为 \(A^T A\) 的特征值绝对值的最大值。
- 矩阵的无穷范数(行范数):矩阵的每一行上的元素绝对值先求和,再从中取个最大的,(行和最大),上述矩阵\(A\)的行范数先得到\([6;16]\),再取最大的最终结果就是:16。
\[ \Vert A\Vert_{\infty}=\max_{1\le i \le m}\sum_{j=1}^n |{a_{ij}}| \tag {10} \]
- 矩阵的核范数:矩阵的奇异值(将矩阵svd分解)之和,这个范数可以用来低秩表示(因为最小化核范数,相当于最小化矩阵的秩——低秩),上述矩阵A最终结果就是:10.9287。
- 矩阵的L0范数:矩阵的非0元素的个数,通常用它来表示稀疏,L0范数越小0元素越多,也就越稀疏,上述矩阵\(A\)最终结果就是:6。
- 矩阵的L1范数:矩阵中的每个元素绝对值之和,它是L0范数的最优凸近似,因此它也可以表示稀疏,上述矩阵\(A\)最终结果就是:22。
- 矩阵的F范数:矩阵的各个元素平方之和再开平方根,它通常也叫做矩阵的L2范数,它的优点在于它是一个凸函数,可以求导求解,易于计算,上述矩阵A最终结果就是:10.0995。
\[ \Vert A\Vert_F=\sqrt{(\sum_{i=1}^m\sum_{j=1}^n{| a_{ij}|}^2)} \tag {11} \]
- 矩阵的L21范数:矩阵先以每一列为单位,求每一列的F范数(也可认为是向量的2范数),然后再将得到的结果求L1范数(也可认为是向量的1范数),很容易看出它是介于L1和L2之间的一种范数,上述矩阵\(A\)最终结果就是:17.1559。
- 矩阵的 p范数
\[ \Vert A\Vert_p=\sqrt[p]{(\sum_{i=1}^m\sum_{j=1}^n{| a_{ij}|}^p)} \tag {12} \]
前文已经介绍过,范数是正则化手段,防止模型自作聪明,那到底是如何做到的呢?
梦回线性方程组,在式(2)中,如果\(m<n\),即样本量很小,而每个样本的特征很多,对于这样的模型,\(X\)的解决方案是无限的。此时通过\(L_1\)正则化,可以使得向量\(X\)更小(更稀疏),因为它的大多数特性对于泛化来说都是无用的。
另一个比喻是:“假设你是一个拥有大量人口且GDP总量也很大的国家的国王,但是人均数量非常低,典型的国富民弱,根据经济学理论,国家的危险系数已经很高了,辛运的是,你是一个有远大抱负的机灵鬼,意识到了这个危险,因此,在相同的GDP目标下,你要求国民高效、努力工作、实行配额淘汰制。结果,许多低效、没有贡献的人因为你的严厉而死亡淘汰,而那些在你的暴政中活下来的人变得真正有能力且高效“。在这个比喻中,你可以认为这里的人口是\(X\)的大小,而淘汰制就是正则化。在正则化的稀疏解决方案中,你可以确保\(X\)剩余的组件都非常强大,每个组件都必须学会一些特殊技能才能留下来,即能从数据中捕获一些有用的数据特征和分布模式。
这是废什么话,还是没说到点子上,不要怪我,但凡能直接啃得动的,也不会炖这么久????~
其实,到目前为止,我们已经证明了为什么稀疏性可以避免过拟合。一般地,常见的是在损失函数中加入\(L_1\),\(L_2\)范数等,并优化迫使范数变小以产生稀疏性,这是为什么呢?以及怎么产生的稀疏性(即如何产生稀疏解的)?
例如,对于向量\([0.1,0.1]\)和向量\([1000,0]\),前者显然不是稀疏的,但是它具有较小的\(L_1\)范数。这是因为我们的优化目标是整个模型的损失函数,所以应该将损失函数与\(L_1\)范数看作是一个整体,而不是单独优化。
进入高能
为进一步介绍范数是如何产生稀疏性的,我们将示例具体化:我们想要找到一条与二维空间中的一组点匹配的的线。课本里说,两点确定一条直线(这个是真的),但是如果训练数据只有一个点呢?这意味着将拥有无限的解决方案:通过该点的每条线都是一个解。假设该点位于\([10,5]\),并且将其中一条线被定义为\(y=a*x+b\)。现在只有一个点,我们只能确定如下关系:
\[\left[ \begin{matrix} 10 & 1 \end{matrix} \right]\times\left[ \begin{matrix} a \\ b \end{matrix} \right]=[5] \tag{13}\]
如下图,即是关于\(a,b\)的直线\(l\):\(b=5-10*a\),直线\(l\)上所有点都是问题的一个解。
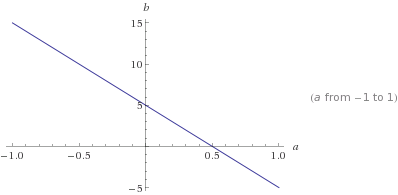
那现在如何找到具有\(L_1\)范数的稀疏解呢?
回顾\(L_1\)的定义:向量所有分量的绝对值之和。如,向量\([\vec{x},\vec{y}]\),则其\(L_1\)范数为\(\vert \vec{x} \vert+\vert \vec{y} \vert\)。
当\(L_1\)范数等于某常数\(c\)时(\(\vert \vec{x} \vert+\vert \vec{y} \vert=c\)),其几何图像如下图,
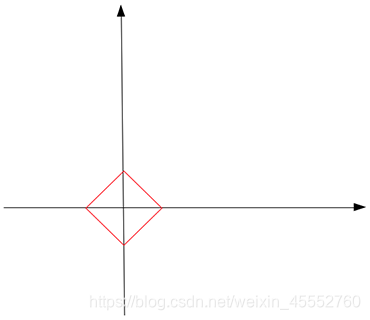
在二维空间中看起来是方形的,但是在高位空间中,它是一个多面体。注意,在红色方形上,并不是所有点都是稀疏的,只有\(x\)或\(y\)分量为零的点(图形的尖端)才是稀疏的(回顾前面的例子)。现在,通过不断的从原点增大\(c\)来“触摸”蓝色线条(待解),直觉上,\(L_1\)的尖端将会先碰到蓝线,这就是我们需要的稀疏解。这句话说得太草率了点??~
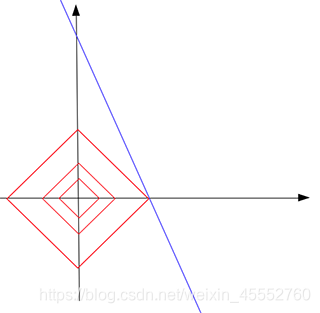
如上图,红色\(L_1\)增长了3倍知道它接触蓝线\(b=5-10*a\)。和我们的直觉一样,触摸点位于\(L_1\)的尖端,触点是\([0.5,0]\)是稀疏的,是不是很巧。因此,我们可以说,在所有可能的解(蓝线上所有点)中找到了具有最小\(L_1\)范数(0.5)的解,也就是我们问题的稀疏解\([0.5,0]\)。在触点处,常数\(c=0.5\)是所有可能解中能找到的最小\(L_1\)范数。
总能找到具有\(L_1\)范数的稀疏解吗?
辣么,\(L_1\)范数总能找到稀疏解吗?不一定。假设我们要找的还是二维空间中的一条线,但这次的训练数据点只有\([1,1000]\),在这种情况下,求解\(b=1000-a\)与\(L_1\)范数触点是一条平行线:
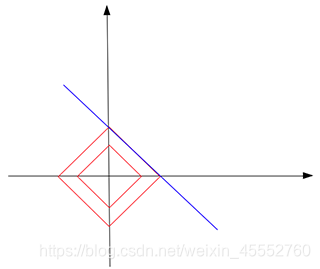
结果,他们触点不止是尖端,而是一条线,这次利用\(L_1\)范数不仅不能找到唯一解,而且大多数正则化解决方案任然不稀疏(除了两个尖端的点)。
但是,当我们扩展到高维数据之后,触点为尖端的概率是非常高的:你可以想象一下仙人球或者刺猬,把它们的刺当作是坐标系(实际数据中也往往是高维数据),然后用手逐渐靠近,(啊~,坏银——是不是手疼),最先触碰到的,大概率是尖端,也就是有稀疏解的点。

以上以实例的形式介绍了范数为什么能产生稀疏解,进而防止过拟合问题。
那~有的人可能会问了:\(L_1\)范数是正则化中找到稀疏解的最佳方案么?那其他范数呢?
我:不知道是WiFi信号不好,还是西瓜不好吃,哪来这么多问题~????
行吧,既然有人问了,那就再啃两口:
事实证明,在我们的式(6)中,当\(0<=p<1\)时,\(L_p\)范数给出了最好的结果,这可以通过不同范数的形状来解释:
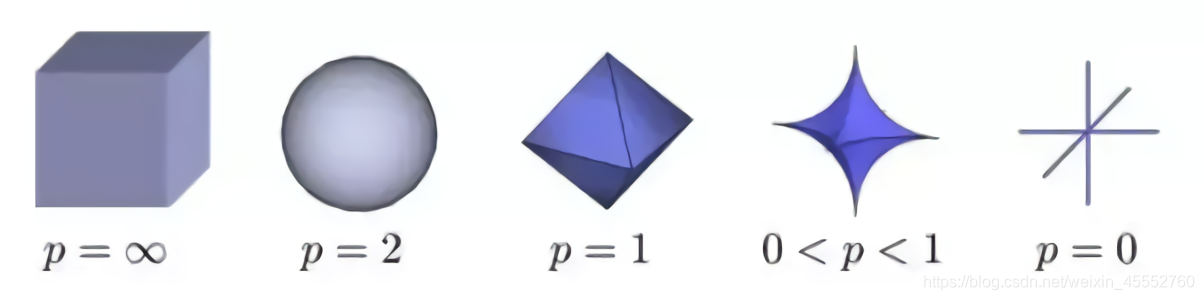
如图所示,当\(p<1\)时,形状比较尖锐,想象用手摸摸啥感受,更容易触碰到尖峰。而当\(p=2\)时,形状变成平滑的球,没什么威胁性。那为什么不全都用\(p<1\)的情况呢?问这个问题的人,请看下图,我就想问问你受得了几棒??!

说人话就是:计算困难,你的机器受不了。
小结
当你的训练数据样本不多,而相比之下样本特征维度较多时,容易发生过拟合问题,在这种情况下,模型倾向于记住包含噪声在内的所有数据细节(因为模型复杂度过高,而数据量太少),以获得更好的训练分数。为避免这种情况,将正则化应用于模型以减小其复杂度。正则化的一种方法是确保训练模型是稀疏的,即大部分分量为0,这些0分量本质上是无用的,所以实质上模型的大小是减小了。
扩展:深度学习中的另一种正则化方式:dropout
论文:
Improving neural networks by preventing co-adaptation of feature detectors
arXiv preprint arXiv: 1207.0580, 2012
G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. SalakhutdinovDropout: A Simple Way to Prevent Neural Networks from Overfitting
JMLR(Journal of Machine Learning Research), 2014
G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov解决什么问题(What)
很大的神经网络在小数据集上训练,往往会导致过拟合
对每个训练样本,采用dropout的方法,随机删除一半的神经元,可以有效减少过拟合
模型结合通常能够提高机器学习方法的表现。但是,训练大网络的计算代价太高,又要训练一些不同的大网络,代价就更高了,而且还需要大量的数据,现实中往往没有足够的数据。就算训练了那么多大网络,用来实际应用也是不可行的,因为模型太大导致了很慢的响应速度。
可以使用dropout来防止过拟合,它起到了一个(和结合多个不同网络)近似的效果为什么能解决(Why)
因为dropout防止了复杂的共适应co-adaptation,co-adaptation的意思是每个神经元学到的特征,必须结合其它的特定神经元作为上下文,才能提供对训练的帮助。
减小co-adaptation,就是要使每个神经元学到的特征,能更通用地提供帮助,它必须组合大量的内部上下文信息。具体做法(How)
每次更新参数之前,每个神经元有一定的概率被丢弃,假设为p%,p可以设为50或者根据验证集的表现来选取,输入层的p比较小,保留概率接近于1
测试阶段不dropout,保留所有单元的权重,而且要乘以保留概率1-p%,为了保证输出期望一致
dropout不只用于前馈神经网络,还可以用于图模型,比如玻尔兹曼机。对dropout的直观解释(Why)
对每个样本都随机地丢弃一半的单元,使得每个单元不能依赖其它单元来做出决策(这样学到的特征更独立)
训练阶段对于每个mini-batch网络的结构是不一样的(因为随机丢弃了一半的单元),测试阶段每个单元乘以保留概率。这样的效果近似于对多个不同的瘦网络做平均(类似集成的效果,能提供更准确的预测)
可以视作一种正则方法,通过给隐藏单元增加噪音生物学上的motivation(Where)
有性生殖取一半父亲基因,一半母亲基因,还有低概率的基因突变,产生后代
无性生殖直接取父代的基因,加低概率的基因突变,产生后代
直觉上无性生殖更好,因为它把父代的优秀基因直接传给了后代。但是有性生殖是物种演化中最重要的方式,一个可能的解释是自然选择的准则并不是保持个体健康,而是基本的混合交流。基因不能依赖于当前已存在的基因,它需要和其它的基因共同协同学习有用的东西。
基于这个理论,使用dropout可以减小和固有神经元之间的依赖,使得它们可以随机地和其它神经元来共同学习,这可以使得神经元更加鲁棒,能够学到更多有用的特征。权重约束
使用权重约束(也叫Max-norm),大的学习率衰减,高动量可以提升模型表现
用w表示任一隐藏单元的输入向量,当w的l2范式要大于某个阈值c时,把它约束为c。
这样可以使用更大的学习率,因为不用担心w的范式太大导致权重爆炸
dropout提供的噪音允许优化探索不同区域的权重空间(原先难以抵达的区域),所以可以使用较大的学习率衰减,从而做更少的探索,最后陷入最小值
为什么又回来看矩阵呢?不要问我为什么,我想看哪就看哪????,我还看女神呢我!
So,矩阵及其分解在机器学习中到底有什么作用?先看一张女神上野树里(Ueno Juri)的照片图,像素为\(450*333\)。禁止舔屏!

根据我们的认识,图片实际上对应着一个矩阵,矩阵的大小就是像素的大小,比如这张图对应的矩阵大小就是\(450*333\),矩阵上每个元素的数值对应着像素值。记这个像素矩阵为\(A\)。现在我们对矩阵\(A\)进行奇异值分解(先不用管这个是啥操作,后面都会整明白)。直观上,奇异值分解将矩阵分解成若干个秩1矩阵之和,用公式表示就是:
\[A=\sigma_1u_1v_1^T+\sigma_2u_2v_2^T+\dots+\sigma_ru_rv_r^T \tag{14}\]
其中等式右边每一项前的系数\(\sigma\)就是奇异值(先不用管这个概念),\(u\)和\(v\)分别表示列向量,秩1矩阵的意思是矩阵秩为1。注意到每一项\(uv^T\)都是秩为1的矩阵。我们假设奇异值满足\(\sigma_1\geq\sigma_2\geq\dots\geq\sigma_r>0\) (奇异值大于0是个重要的性质,此处先不用管),如果不满足的话重新排序顺序即可。
既然奇异值有从大到小排列的顺序,辣么问题来了,如果只保留大的奇异值,舍去较小的奇异值,这样式(14)里的等式自然不再成立,那会得到怎样的矩阵——也就是图像呢?
令\(A_1=\sigma_1u_1v_1^T\),这只保留式(14)中等式右边第一项,得到图形如下:

结果发现完全看不清,我们试着多增加几项:
\(A_5=\sigma_1u_1v_1^T+\sigma_2u_2v_2^T+\sigma_3u_3v_3^T+\sigma_4u_4v_4^T+\sigma_5u_5v_5^T\),再作图

隐约可以辨别这是短发伽椰子的脸\(\dots\dots\)但还是很模糊, 毕竟只取了5个特征值。下面再取20个奇异值试试,也就是式(14)等式右边前20项构成\(A_{20}\):

虽然还有些马赛克样子的模糊,但是我们总算能辨别出这是\(Juri\)的脸。当进一步取到前50项构成\(A_{50}\)时:

终于,我们得到了和原图像差别不大的图像。也就是说当\(k\)从1不断增大,\(A_k\)不断逼近\(A\)。回到公式(14),矩阵\(A\)表示一个\(450*333\)的矩阵,需要保存\(450\times333=149850\)个元素的值。等式右边\(u\)和\(v\)分别是\(450*1\)和\(333*1\)的向量,每一项有\(1+450+333=784\)个元素。如果我们要存储很高清的图片,而又受限于存储空间的限制,在尽可能保证图像可识别的精度的前提下,我们可以保留奇异值较大的若干项,舍去奇异值较小的项即可。例如在上面的例子中,如果我们只保留奇异值分解的前50项,则需要存储元素为\(784\times50=39200\),和存储原始矩阵\(A\)相比,存储量仅为后者的26%。
以上为我们对矩阵分解中奇异值分解的直观解释:奇异值往往对应着矩阵中隐含的重要信息,且重要性和奇异值大小相关。每个矩阵\(A\)都可以表示为一系列秩为1的“小矩阵”之和,而奇异值则衡量了这些“小矩阵”对于\(A\)的权重。
这是矩阵在机器学习里最常用的一方面:图片压缩。上述过程是一个矩阵的奇异值分解(SVD)过程,上面这个例子也是告诉大家矩阵分解到底有啥用,不然一脸懵逼的看完了也不知道是干嘛的,哈哈哈,话不多说,具体是怎么实现的呢?得先再卖个关子,在讨论SVD之前,我们得先了解什么是特征值,什么是特征向量~??
先了解两个概念:
正交矩阵:若一个方阵其行与列皆为正交的单位向量,则该矩阵为正交矩阵,且该矩阵的转置和其逆相等。两个向量正交的意思是两个向量的内积为 \(0\)。
正定矩阵:如果对于所有的非零实系数向量\(z\),都有 \(z^TA_z > 0\),则称矩阵\(A\)是正定的。正定矩阵的行列式必然大于 0, 所有特征值也必然\(>0\)。相对应的,半正定矩阵的行列式必然\(≥0\)。
关于特征值、特征向量,内容量可以很大,我们先从它的几何意义讲起。
特征值分解
因为线性变换过程中总在各种基(可以简单理解为向量空间的坐标抽)之间变来变去,所以图中都会把向量空间的基和原点画出来。在\(\vec{i},\vec{j}\)下有向量\(\vec{v}\):
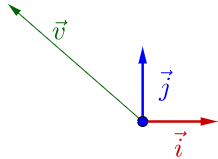
随便左乘一个矩阵\(A\),图像目前看上去没什么特殊:
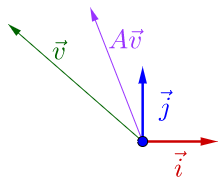
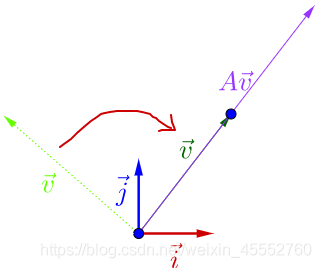
再调整一下\(\vec{v}\)的方向,图像开始变得特殊了:
从图中可以看到,调整后的\(\vec{v}\)和\(A\vec{v}\)在同一条线上,只是\(A\vec{v}\)的长度相对\(\vec{v}\)的长度变长了。此时,我们就称\(\vec{v}\)是\(A\)的特征向量,而\(A\vec{v}\)的长度是\(\vec{v}\)的长度的\(\lambda\)倍,\(\lambda\)就是特征值。从而得出了特征值与特征向量的定义式:
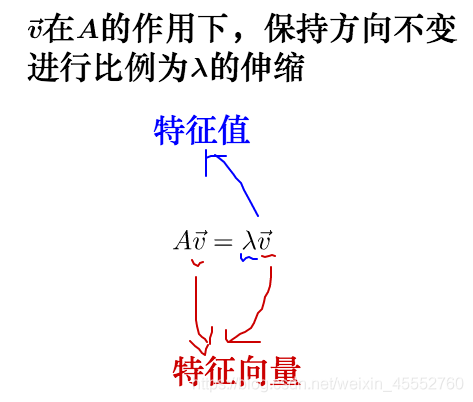
其实,矩阵\(A\)不止一个特征向量,还有一个特征向量:
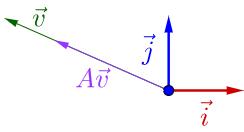
容易从\(A\vec{v}\)相对于\(\vec{v}\)是变长了还是缩短看出,这两个特征向量对应的特征值\(\lambda\),一个大于1,一个小于1。从特征向量和特征值的定义式还可以看出,特征向量所在的直线上的向量都是特征向量:
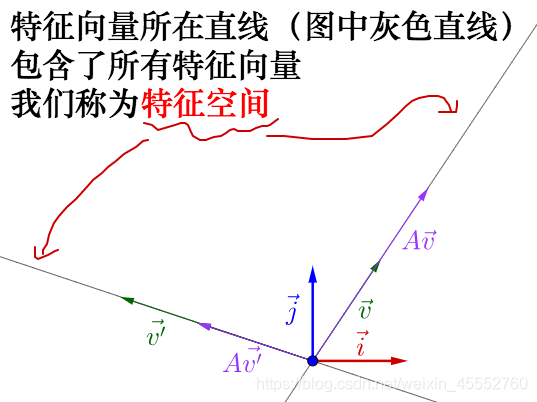
为了进一步说明特征值、奇异值的几何意义,我们引入一个实例:
线性代数中最让人深刻的一点是,要将矩阵和空间中的线性变换视为同样的事物。比如对角阵\(M\)作用在任何一个向量上
\[\left[ \begin{matrix} 3 & 0 \\ 0 & 1 \end{matrix} \right]\times\left[ \begin{matrix} x \\ y \end{matrix} \right]=\left[\begin{matrix} 3x \\ y \end{matrix} \right] \tag{15}\]
对角阵:是指主对角线之外的元素皆为0的矩阵。
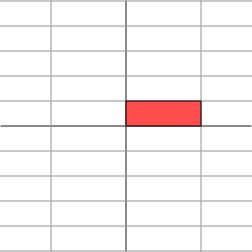
其几何意义为在水平\(x\)方向上拉伸3倍,\(y\)方向保持不变的线性变换。换言之,对角矩阵起到的作用是将水平垂直网格拉伸(或反射后水平拉伸)的线性变换。如下图所示
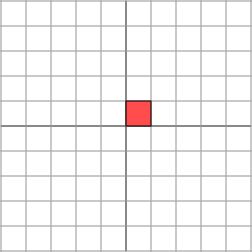
变换后
如果\(M\)不是对角阵,而是一个对称矩阵:
\[M=\left[ \begin{matrix} 2 & 1 \\ 1 & 2 \end{matrix} \right]\]
对称矩阵:是指以主对角线为对称轴,各元素对应相等的矩阵。
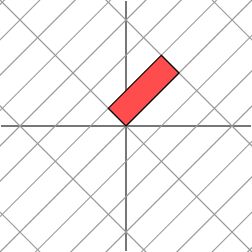
辣么,我们也总可以找到一组网格线(正交基),使得矩阵作用在该网格上仅仅表现为拉伸变换,没有旋转变换,如下图
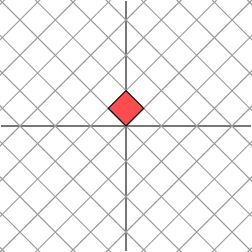
变换后
接下来,考虑更一般的非对称矩阵:
\[M=\left[ \begin{matrix} 1 & 1 \\ 0 & 1 \end{matrix} \right]\]
此时,我们再也找不到一组网格(正交基),使得矩阵作用在该网格上之后只有拉伸变换(因为对一般非对称矩阵无法保证在实数域上可对角化)。辣么,我们退而求其次,找一组网格,使得矩阵作用在该网格上之后允许有拉伸变换和旋转变换,但要保证变换后的网格依旧是相互垂直。这是可以做到的:
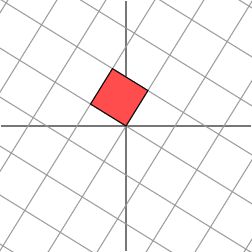
变换后
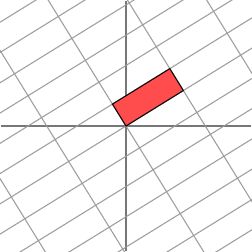
我们的矩阵特征值分解,就是这种拉伸与旋转变换。经典的特征值分解定义:
对于矩阵\(A\),如果可以对角化的话,可以通过相似矩阵进行下面的特征值分解:
\(A=P\Lambda P^{-1}\)
其中\(\Lambda\)为对角阵,每一个对角线上的元素就是一个特征值,\(P\)的列向量是单位化的特征向量。
可对角化:如果一个方块矩阵\(A\)相似于对角矩阵,也就是说,如果存在一个可逆矩阵\(P\)使得\(P^{-1}\Lambda P\)是对角矩阵,则称\(A\)是可对角化的。
比较抽象,数学概念一向如此,举个栗子:
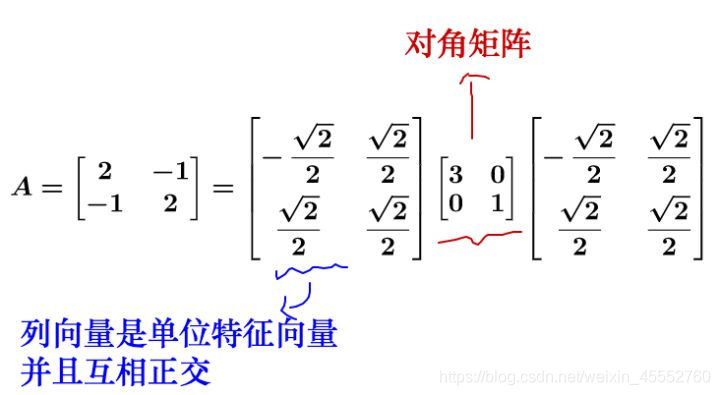
对于方阵而言,矩阵不会进行维度的升降,所以矩阵代表的变换只有两种:
最后的而变换就是两种变换的合成。我们可以拆解来看:
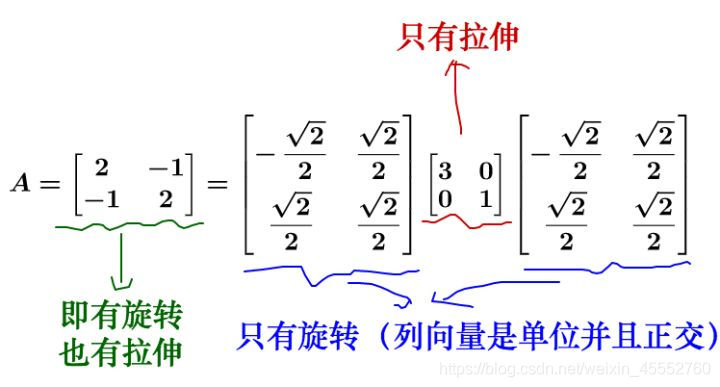
小结
- 特征值分解可以得到特征值与特征向量,特征值表示对应的特征有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。
- 当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前\(N\)个特征向量,那么就对应了这个矩阵最主要的\(N\)个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。
奇异值分解(SVD)
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵。比如,有\(N\)个学生,每个学生有\(M\)科成绩,这样形成的一个\(N*M\)的矩阵就不一定是方阵,我们怎样才能描述这样普通矩阵的重要特征呢?
奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法: \(A=U\Sigma V^T\)。
假设A是一个\(M*N\)的矩阵,那么得到的U是一个\(M*M\)的方阵(里面的向量是正交的,\(U\)里面的向量称为左奇异向量)
\(\Sigma\)是一个\(M*N\)的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值)
\(V^T\)(V的转置)是一个\(N*N\)的矩阵(里面的向量也是正交的,\(V\)里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片
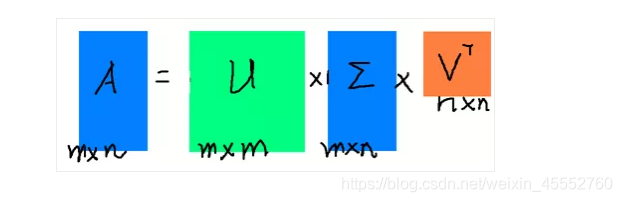
奇异值与特征值如何对应?
首先,将矩阵\(A\)转置\(A^T\),将会得到一个方阵\(A^TA\),对这个方阵进行特征分解,可以得到:
\((A^TA)v_i=\lambda_iv_i\)
公式里得到的\(v\),就是我们上面提到的右奇异向量。此外还可以得到:
\(\sigma_i=\sqrt{\lambda_i}\) , \(u_i=\frac{1}{\sigma_i}Av_i\)
推导:
矩阵\(A\)的奇异值分解为:
\(A_{nxp}=U_{nxn}\Sigma_{nxp}V^T_{pxp}\)
其中,\(U^TU=I_{nxn}, V^TV=I_{pxp}\),即\(U\)和\(V\)是正交的。相应的\(A^T=V\Sigma U^T\)
令\(M=AA^T\),则\(M^T=A^TA\),(\(M\)与\(M^T\)都是对称半/正定矩阵),展开有
\(M=AA^T=U\Sigma V^TV\Sigma U^T=U\Sigma\Sigma U^T=U\Sigma^2U^T=U\left[ \begin{matrix} \sigma_{1}^2 \\& \ddots\\&& \sigma_{r}^2 \end{matrix} \right]U^T\),其中\(r\)是矩阵\(A\)的秩
上式等式两边右乘以一个\(U\),有
\(MU=U\Sigma^2=U\left[ \begin{matrix} \sigma_{1}^2 \\& \ddots\\&& \sigma_{r}^2 \end{matrix} \right]\)
该式子即为方阵\(M=AA^T\)的特征分解式:\(U\)是矩阵的特征向量,而\(\sigma_1^2,\dots,\sigma_r^2\)为对应的特征值。
同理,对\(M^T=A^TA\),有
\(M^T=A^TA=V\Sigma U^TU\Sigma V^T=V\Sigma\Sigma V^T=V\Sigma^2V^T=V\left[ \begin{matrix} \sigma_{1}^2 \\& \ddots\\&& \sigma_{r}^2 \end{matrix} \right]V^T\),其中\(r\)是矩阵\(A\)的秩
上式等式左右两边乘以一个\(V\),有
\(M^TV=V\Sigma^2=V\left[ \begin{matrix} \sigma_{1}^2 \\& \ddots\\&& \sigma_{r}^2 \end{matrix} \right]\)
该式子即为方阵\(M^T=A^TA\)的特征分解式:\(V\)是矩阵的特征向量,而\(\sigma_1^2,\dots,\sigma_r^2\)为对应的特征值。
这里的\(\sigma\)就是上面提到的奇异值,\(u\)就是上面提到的左奇异向量。奇异值\(\sigma\)跟特征值类似,在矩阵\(\Sigma\)中也是从打到小排列,而且\(\sigma\)的减小特别快,在很多情况下,前10%甚至1%的奇异值加和就占了全部奇异值之和的99%以上,这也就是说,我们可以使用前\(r\)大的奇异值来近似描述矩阵,也即是
\(A_{m\times n}\approx U_{m\times r}\Sigma_{r\times r}V^T_{r\times n}\)
\(r\)是远远小于\(m,n\)的数,这样矩阵的乘法看起来就是下面这样:
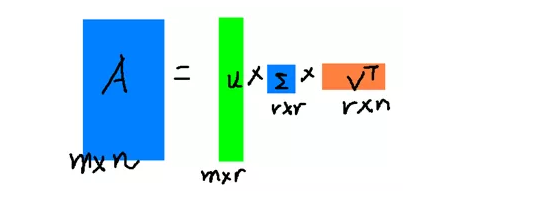
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,\(r\)越接近于\(n\),则相乘的结果越接近于\(A\)。而这三个矩阵的面积之和(从存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵\(A\),我们如果想要压缩空间来表示原矩阵\(A\),我们存下这里的三个矩阵:\(U\)、\(\Sigma\)、\(V\)就好了。回到本节开篇,女神上野树里的例子,知道为什么能压缩这么小吧~
那~奇异值有什么几何意义呢
奇异值分解的几何含义为:对于任何一个矩阵,我们要找到一组两两正交单位向量序列,使得矩阵作用在此向量序列上后得到新的向量序列保持两两正交。奇异值的几何含义:这组变换后的新的向量序列的长度。光说不练,都是抽象的~ 来个例子
现有正交单位向量\(v_1\)和\(v_2\):
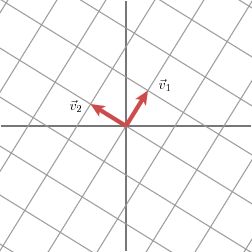
当矩阵\(M\)作用在正交单位向量\(v_1\)和\(v_2\)上之后:
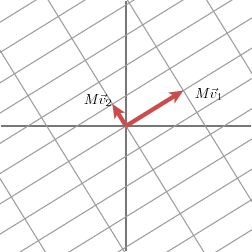
得到\(Mv_1\)和\(Mv_2\)也是正交的。
令\(u_1\)和\(u_2\)分别是\(Mv_1\)和\(Mv_2\)方向上的单位向量,即\(Mv_1=\sigma_1u_1\),\(Mv_2=\sigma_2u_2\),写在一起就是\(M\left[ \begin{matrix} v_1 & v_2\end{matrix} \right]=\left[ \begin{matrix} \sigma_1u_1 & \sigma_2u_2\end{matrix} \right]\),整理得到:
\[M=M\left[ \begin{matrix} v_1 & v_2\end{matrix} \right]\left[\begin{matrix} v^T_1 \\ v^T_2 \end{matrix} \right]=\left[ \begin{matrix} \sigma_1u_1 & \sigma_2u_2\end{matrix} \right]\left[\begin{matrix} v^T_1 \\ v^T_2 \end{matrix} \right]=\left[ \begin{matrix} u_1 & u_2\end{matrix} \right]\left[ \begin{matrix} \sigma_1 & 0 \\ 0 & \sigma_2\end{matrix} \right]\left[\begin{matrix} v^T_1 \\ v^T_2 \end{matrix} \right] \tag{16}\]
这样就得到矩阵\(M\)的奇异值分解。奇异值\(\sigma_1\)和\(\sigma_2\)分别是\(Mv_1\)和\(Mv_2\)的长度。进一步地,很容易推广到一般\(n\)维情形。
再来一个数值化实例:
假设矩阵\(A\)的奇异值分解为:
\[A=\left[ \begin{matrix} u_1 & u_2\end{matrix} \right]\left[ \begin{matrix} 3 & 0 \\ 0 & 1\end{matrix} \right]\left[\begin{matrix} v^T_1 \\ v^T_2 \end{matrix} \right] \tag{17}\]
其中\(u_1\),\(u_2\),\(v_1\),\(v_2\)是二维平面的向量。根据奇异值分解的性质,\(u_1\),\(u_2\)线性无关,\(v_1\),\(v_2\)线性无关。那么对二维平面上任意的向量\(x\),都可以表示为:\(x=\xi_1v_1+\xi_2v_2\)。
当\(A\)作用在\(x\)上时,有
\[y=Ax=A\left[\begin{matrix} v_1 & v_2 \end{matrix} \right]\left[\begin{matrix} \xi_1 \\ \xi_2 \end{matrix}\right]=\left[ \begin{matrix} u_1 & u_2\end{matrix} \right]\left[ \begin{matrix} 3 & 0 \\ 0 & 1\end{matrix} \right]\left[\begin{matrix} v^T_1 \\ v^T_2 \end{matrix} \right]\left[\begin{matrix} v_1 & v_2 \end{matrix} \right]\left[\begin{matrix} \xi_1 \\ \xi_2 \end{matrix}\right]=3\xi_1u_1+\xi_2u_2 \tag{18}\]
令\(\eta_1=3\xi_1\),\(\eta_2=\xi_2\),我们可以得出结论:如果\(x\)在单位圆\(\xi_1^2+\xi_2^2=1\)上,那么\(y\)正好在椭圆\(\eta_1^2/3^2+\eta_2^2/1^2=1\)上。这表明:如图所示,矩阵\(A\)将二维平面单位圆变换成椭圆,而两个奇异值正好是椭圆的两个半轴长,长轴所在直线是\(span\{u_1\}\),短轴所在的直线是\(span\{u_2\}\)。
\(span\{u_1\}\)指\(u_1\)空间中的生成子空间。
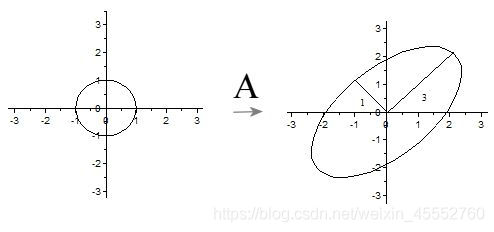
推广到一般情形:一般矩阵\(A\)将单位球\(\Vert x\Vert_2=1\)变换为超椭球面\(E_m=\{y\in C^m:y=Ax, x\in C^n, \Vert x\Vert_2=1 \}\),那么矩阵\(A\)的每个奇异值恰好就是超椭球的每条半轴长度。
终于啃完了特征值分解及奇异值分解~:joystick:????
思考两个问题,从上野树里的例子中,SVD的应用之一是图片压缩,而PCA也能作压缩,那
1、SVD与PCA是什么关系?
2、想想SVD还有没有其他的应用,比如说,推荐(电影、产品、...)
本博客所有内容仅供学习,不为商用,如有侵权,请联系博主谢谢。
[1] 同济大学数学系.高等数学(第七版)[M],高等教育出版社,2014.
[2] 范数:https://medium.com/mlreview/l1-norm-regularization-and-sparsity-explained-for-dummies-5b0e4be3938a
[3] 任广千,胡翠芳,线性代数的几何意义——图解线性代数, 2010
[4] 特征分解:https://www.zhihu.com/question/21874816/answer/181864044
[5] SVD:https://www.zhihu.com/question/22237507
[6] Jim Liang, Getting Started with Machine Learning,2018
[7] 周志华.机器学习[M].清华大学出版社,2016.
[8] Ian,Goodfellow,Yoshua,Bengio,Aaron...深度学习[M],人民邮电出版,2017
原文:https://www.cnblogs.com/RoyalFlush/p/12458280.html