声明:本文参考https://blog.csdn.net/u013733326/article/details/79907419
一、实验的目的:使用优化的梯度下降算法,所以需要做一下几件事:
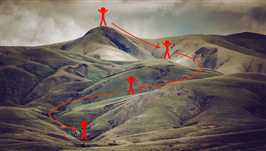
把丘陵的海拔想象成损失函数,最小化损失函数就像找到丘陵的最低点。在训练的每一步中,都会按照梯度方向(下山最快的方向)更新参数,使损失函数减小,最后尽可能地到达最低点。如上图所示即为最快的下山路径。
二、实验内容
1、没有任何优化的梯度下降法(GD),也叫作批梯度下降法,即一次梯度下降都遍历所有的训练集。参数更新的公式如下:
$$W^{\left [ l \right ]}=W^{\left [ l \right ]}-\alpha dW^{\left [ l \right ]}\quad\quad\left ( 1 \right )$$
$$b^{\left [ l \right ]}=b^{\left [ l \right ]}-\alpha db^{\left [ l \right ]}\quad\quad\left ( 1 \right )$$
注:$\alpha$是学习率、$l$是当前的层数
Course 2 - 改善深层神经网络 - 优化算法(Batch、Mini-Batch、Momentum、RMSprop、Adam)
原文:https://www.cnblogs.com/xiazhenbin/p/12467172.html