参考:http://www.52nlp.cn/%e7%90%86%e8%ae%ba-%e6%9c%b4%e7%b4%a0%e8%b4%9d%e5%8f%b6%e6%96%af%e6%a8%a1%e5%9e%8b%e7%ae%97%e6%b3%95%e7%a0%94%e7%a9%b6%e4%b8%8e%e5%ae%9e%e4%be%8b%e5%88%86%e6%9e%90#more-10451
一、理论
朴素贝叶斯法是基于贝叶斯定理和特征条件独立假设的分类方法,‘朴素’之名来源于特征条件独立的假设,这是一个很强,很简单的假设,因为它意味着不同特征之间不会相互影响,这大大简化了计算。
首先,从给定的数据集出发,(这些数据集包括用多个特征描述的输入x,以及x对应的类别标记y,X是定义在输入空间上的随机变量,而Y是定义在输出空间上的随机变量,P(X,Y)是X,Y的联合概率分布)求出P(X,Y);然后根据贝叶斯定理,对给定的输入x,求出后验概率最大的输出y。
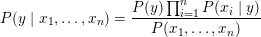
如上式,左边是我们要求的,即当给一个要预测的输入x=(x1,x2...,xn)时,要求x的类别y的概率,我们希望有这样一个y值,使得左边的概率最大;右边是可以根据数据集估计出来的概率,且分母是与类别无关的常数,不管y是多少,分母都不变,它只与初始数据集有关,所以当我们只想判断不同y取值下的大小时,可以省去。
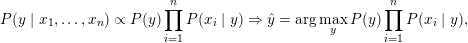
现在将问题简单了一些,只求argmax[y],右边可以根据数据集统计结果得出,即我们选择不同类别的输入x,计算它们的类别概率与给定类别下的特征组合的条件概率的乘积,然后比较大小即可,最大的就是要预测的类别值。
那么朴素贝叶斯是在学什么呢,可以知道,我们不需要去精确的计算P(X,Y)的参数,(朴素贝叶斯法是一种生成方法,同时考虑X和Y的随机性,就算想计算也不能直接计算P(X,Y),必须要通过下面两种方法估计后,再相乘得到联合概率分布)朴素贝叶斯的学习只要通过足够多的数据集估计出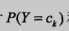 和
和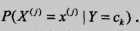 即可。
即可。
极大似然估计方法如下,就是比较简单的计数法:
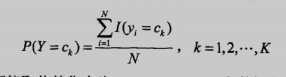
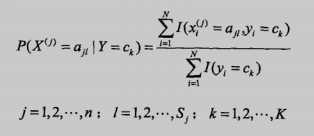
还有一种是贝叶斯估计,考虑到有时候可能因为数据集很少,某个特征出现分子为0的情况,然后导致后验概率也为0,造成全盘皆输的局面,简单来说就是为了防止出现0的情况使用了平滑:
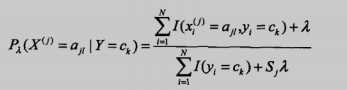
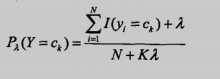
二、项目:识别留言板侮辱性评论
参考:http://www.52nlp.cn/%e5%ae%9e%e7%8e%b0-%e6%9c%b4%e7%b4%a0%e8%b4%9d%e5%8f%b6%e6%96%af%e6%a8%a1%e5%9e%8b%e7%ae%97%e6%b3%95%e7%a0%94%e7%a9%b6%e4%b8%8e%e5%ae%9e%e4%be%8b%e5%88%86%e6%9e%90
原文:https://www.cnblogs.com/liuxiangyan/p/12483615.html