http://cs231n.github.io/classification/
图像分类:
本质:从一组固定的类别中为输入图像分配一个标签的任务
计算机中的图像:对于计算机而言,图像用一个大型的三维数字数组(宽,高,通道)
目标:将代表图像的三维数组变成一个单独的标签,例如‘猫’。
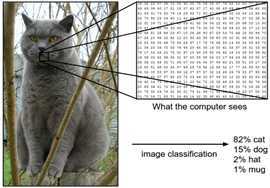
(图像分类的任务是预测给定图像的单个标签)
图像分类的挑战:
viewpoint varation:一个物体可以从多个不同的角度被照相机捕捉
scale variation: 图像的大小会有变化:
deformation:许许多多物体都不是刚体,本身会有变形产生
occlusion:感兴趣的区域可能被遮挡
illumination condition:照明条件对图片像素的值的影响很大
background clutter:物体的特征区域可能和背景熔接在一起
intra-class variation:感兴趣的类别通常自己又会有多种类别。
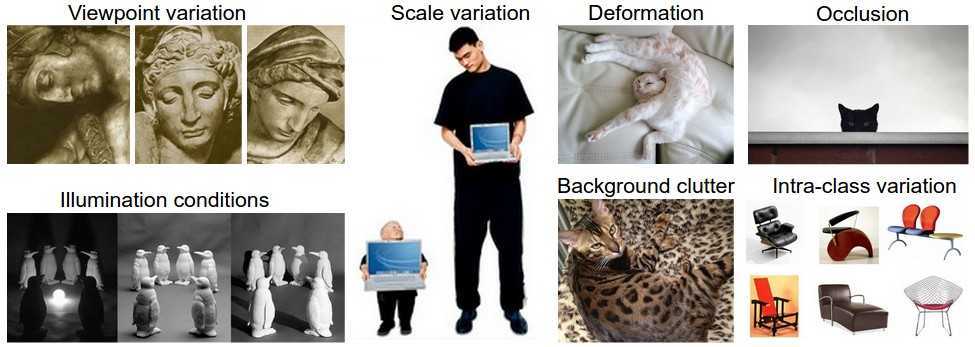
(一个好的图像分类模型必须对所有的这些变异的交叉保持良好的分类效果)
数据驱动方法:
不直接在代码中指明每种类别的兴趣区域的外观,我们会像对待孩子一样,给计算机提供很多示例。类别(数据),然后开发学习算法(计算)
图像分类的过程:
输入:我们的输入包含一组N幅图像,每幅图像都标记有K个不同的类别之一。我们将此数据称为训练集。
学习:我们的任务是使用训练集学习每个类别的模样。我们将此步骤称为训练分类器或学习模型。
预测:最后,我们通过要求分类器预测从未见过的一组新图像的标签来评估分类器的质量。然后,我们将这些图像的真实标签与分类器预测的标签进行比较。直观地,我们希望很多预测与真实答案(我们称之为基本事实)相匹配。
最近邻分类器(NN):
工作原理:获取预测图像,将其与每个训练图像进行比较,并预测最近的训练图像标签。
L1距离,L2距离:
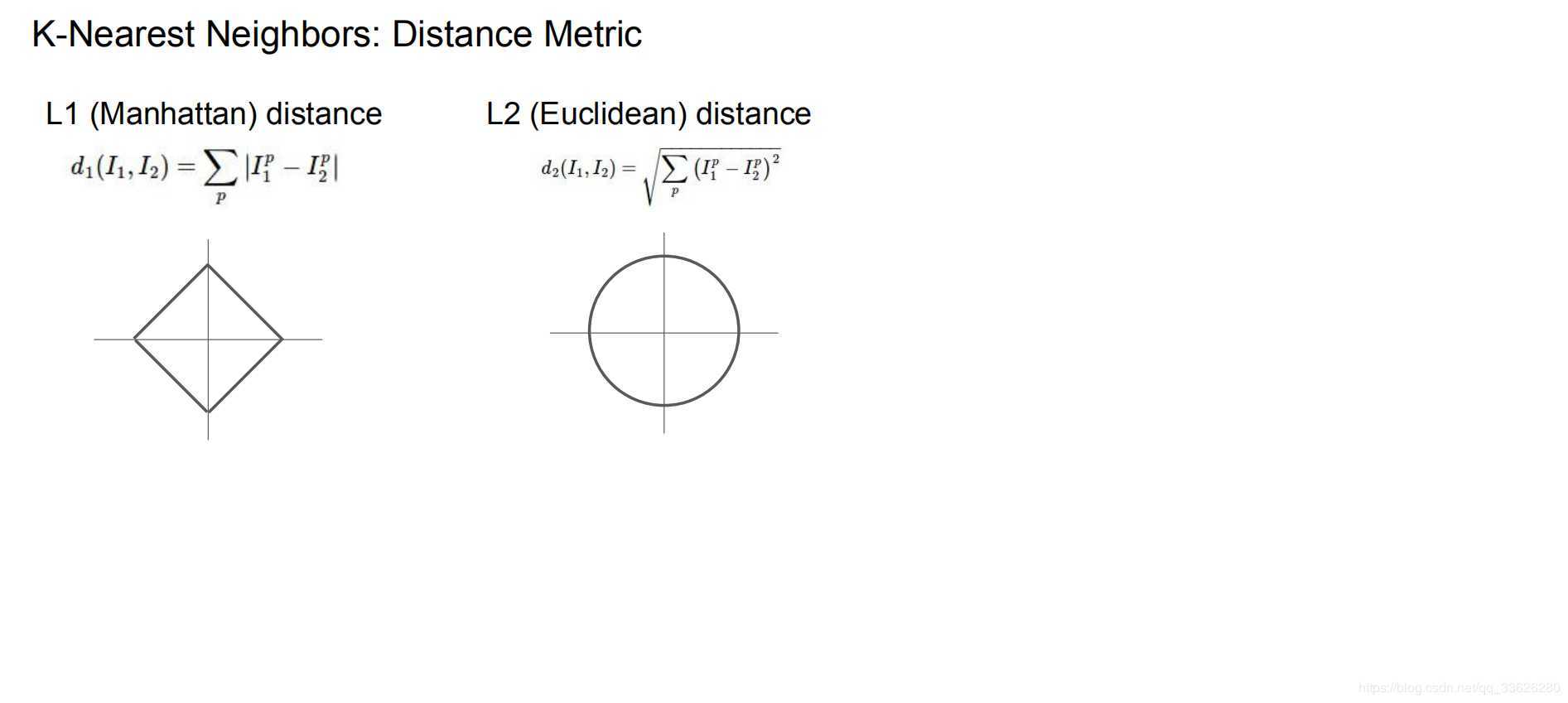
L1:他计算的是第一维差的绝对值加上第二维差的绝对值,可以想象成直角三角形的两条直角边的长度和
L2,他计算的是第一维差的平方加上第二维差的平方再求和,然和开根。由勾股,可以想象成直角三角形的斜边长
最邻近分类器选择L1S时:
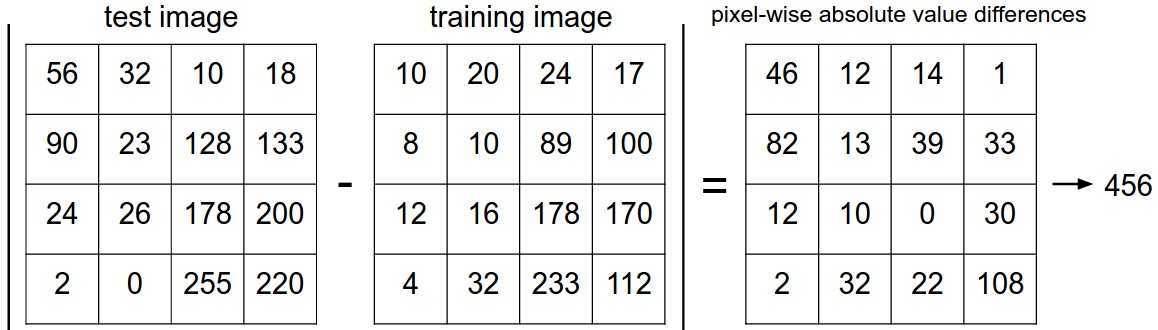
(将两张图片逐个像素值相减,然后将差异值相加。如果两张图像相同,则结果为0,如果计算值很大则说明两张图像差别很大)
k-最邻近分类器(k - Nearest Neighbor Classifier——KNN):
在对图像进行分类时,找到K个最接近的图像。当K=1时,即找到一个最接近的图像,就变成了最邻近分类。
在实际操作中:K(超参)的选择很关键
超参调整:
千万不能在测试集上调整超参,会出现过拟合的状况,获得的性能过于乐观与部署的模型
在训练集中分出一部分用作测试集,叫做验证集。
最近邻近分类器的优缺点:
优点:实施和理解简单
缺点:分类器无需花费任何时间训练,只需要存储训练数据。但是测试时,由于要与每个单独的训练示例进行比较,所以测试时会有大量的计算成本。
import numpy as np class NearestNeighbor(object): def __init__(self): pass def train(self, X, y): """ X is N x D where each row is an example. Y is 1-dimension of size N """ # the nearest neighbor classifier simply remembers all the training data self.Xtr = X self.ytr = y def predict(self, X): """ X is N x D where each row is an example we wish to predict label for """ num_test = X.shape[0] # lets make sure that the output type matches the input type Ypred = np.zeros(num_test, dtype = self.ytr.dtype) # loop over all test rows for i in xrange(num_test): # find the nearest training image to the i‘th test image # using the L1 distance (sum of absolute value differences) distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) min_index = np.argmin(distances) # get the index with smallest distance Ypred[i] = self.ytr[min_index] # predict the label of the nearest example return Ypred
调整超参
assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print ‘accuracy: %f‘ % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))原文:https://www.cnblogs.com/djrcomeon/p/12485849.html