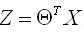
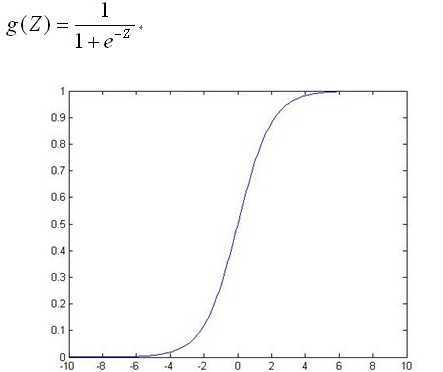
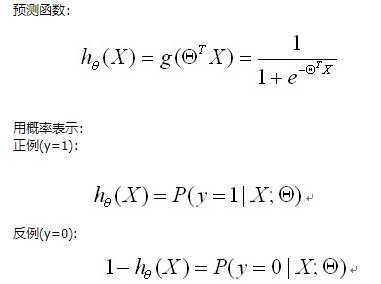
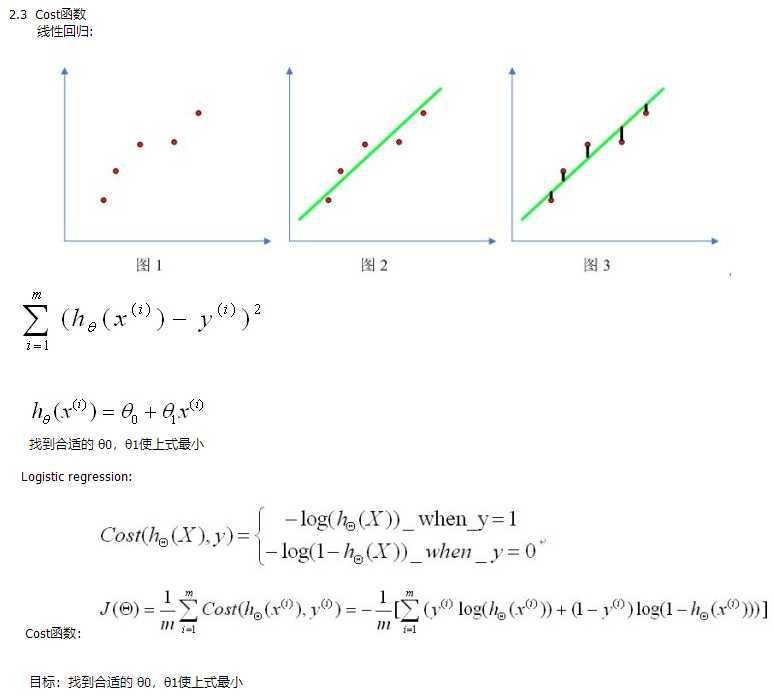

import numpy as np import random # m denotes the number of examples here, not the number of features def gradientDescent(x, y, theta, alpha, m, numIterations): #阿尔法是学习率,m是总实例数,numIterations更新次数 xTrans = x.transpose() #转置 for i in range(0, numIterations): hypothesis = np.dot(x, theta) #预测值 loss = hypothesis - y # avg cost per example (the 2 in 2*m doesn‘t really matter here. # But to be consistent with the gradient, I include it) cost = np.sum(loss ** 2) / (2 * m) print("Iteration %d | Cost: %f" % (i, cost)) # avg gradient per example gradient = np.dot(xTrans, loss) / m # update theta = theta - alpha * gradient return theta def genData(numPoints, bias, variance): #创建数据,参数:实例数,偏置,方差 x = np.zeros(shape=(numPoints, 2)) #行数为numPoints,列数为2,数据类型为Numpy arrray y = np.zeros(shape=numPoints) #标签,只有1列 # basically a straight line for i in range(0, numPoints): #0到numPoints-1 # bias feature x[i][0] = 1 #x的第一列全为1 x[i][1] = i # our target variable y[i] = (i + bias) + random.uniform(0, 1) * variance return x, y # gen 100 points with a bias of 25 and 10 variance as a bit of noise x, y = genData(100, 25, 10) m, n = np.shape(x) numIterations= 100000 alpha = 0.0005 theta = np.ones(n) theta = gradientDescent(x, y, theta, alpha, m, numIterations) print(theta)
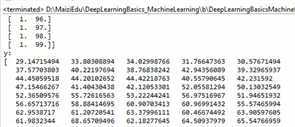
生成x和y的值如下:
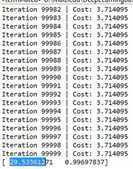
程序执行结果:
原文:https://www.cnblogs.com/fenglivoong/p/12487613.html
