Ceph 的监控可视化界面方案很多----grafana、Kraken。但是从Luminous开始,Ceph 提供了原生的Dashboard功能,通过Dashboard可以获取Ceph集群的各种基本状态信息。
mimic版 (nautilus版) dashboard 安装。如果是 (nautilus版) 需要安装 ceph-mgr-dashboard
1、在每个mgr节点安装,尽量保证在每个节点都安装dashboard因为当一个节点挂了的话,去访问其他的节点,其他的节点没有这个dashboard的话就访问不到了
#yum -y install ceph-mgr-dashboard
#ceph mgr module ls |more
{
"enabled_modules": [
"dashboard",
"iostat",
"restful"
],
"disabled_modules": [
{
"name": "ansible",
"can_run": true,2、开启mgr功能#ceph mgr module enable dashboard
开启之后可以查看我们的开启的模块
也可以通过ceph -s查看集群状态
这里会列出显示的services,这里显示mgr安装在三个节点上
#ceph -s
cluster:
id: 75aade75-8a3a-47d5-ae44-ec3a84394033
health: HEALTH_OK
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 34m)
mgr: cephnode01(active, since 5m), standbys: cephnode02, cephnode03
mds: cephfs:2 {0=cephnode02=up:active,1=cephnode03=up:active} 1 up:standby
osd: 3 osds: 3 up (since 47m), 3 in (since 23h)
rgw: 1 daemon active (cephnode01)3、生成并安装自签名的证书
#ceph dashboard create-self-signed-cert 4、创建一个dashboard登录用户名密码
#ceph dashboard ac-user-create guest 1a2s3d4f administrator
{"username": "guest", "lastUpdate": 1583304693, "name": null, "roles": ["administrator"], "password": "$2b$12$RgzO9RZzWWCYVcPSs3ACXO5dClSJH1gLh3QAc6GlaDQbhzKKHAXFC", "email": null}5、查看服务访问方式
#ceph mgr services
{
"dashboard": "https://cephnode01:8443/"
}6、登录页面
7、登录ceph-dashboard的管理页面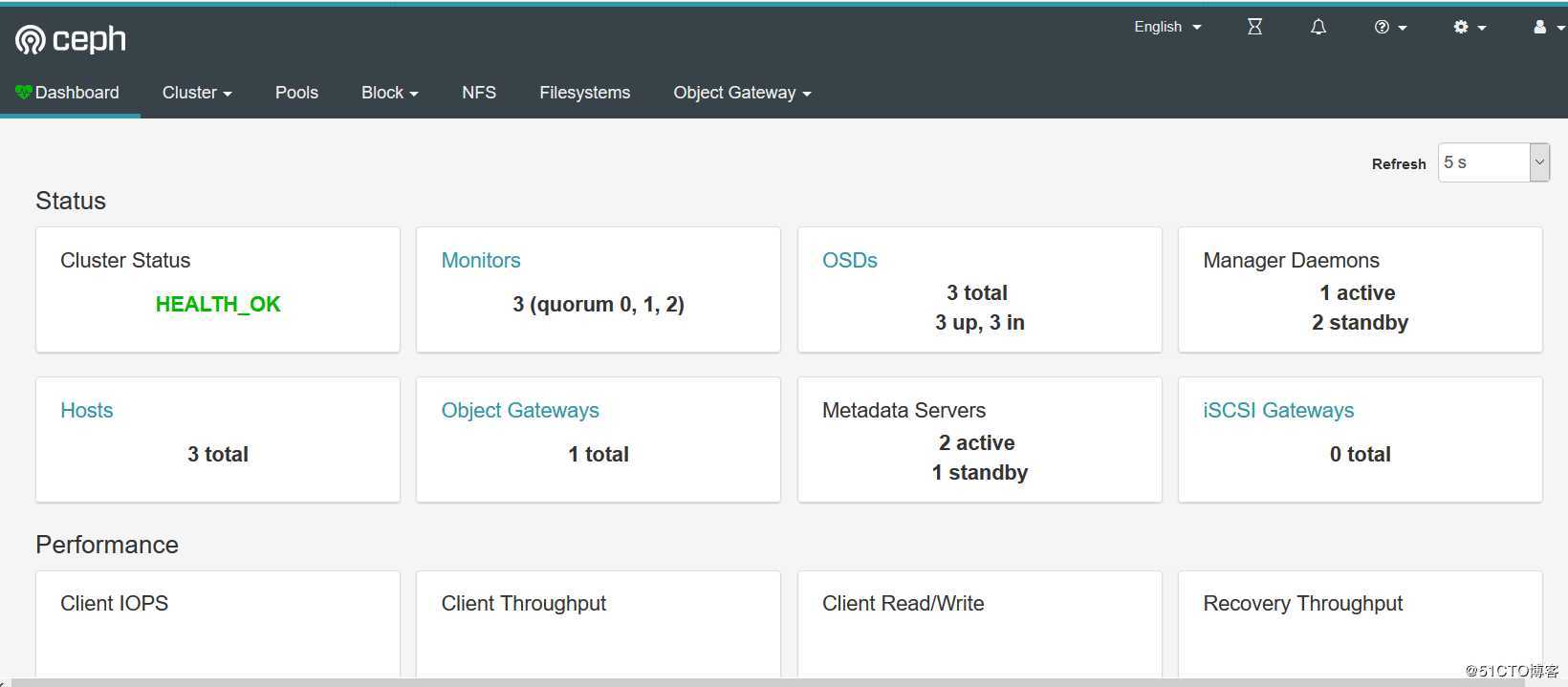
关于创建访问ui的用户基于权限的设置,包含管理员,只读,块的管理者,cephfs的管理者都可以去创建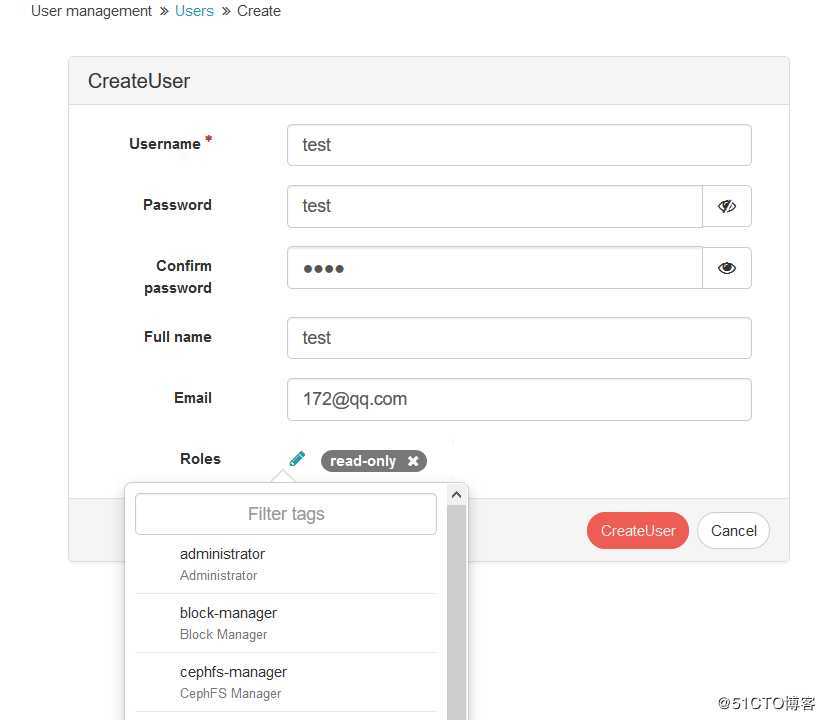
这里我是用k8s将prometheus和grafana部署起来的,这里就不再将部署细节进行展示了,之前写过这类的文档,另外就是我们首先是去拿ceph的数据,怎么去拿呢?要就需要ceph提供的本身的mgr的模块对prometheus开启。
这里在k8s中部署prometheus的文档:https://blog.51cto.com/14143894/2438026
把这行获取收集ceph数据的模版加入configmap文件中
- job_name: ‘ceph_cluster‘
honor_labels: true
scrape_interval: 5s
static_configs:
- targets: [‘192.168.1.5:9283‘]
labels:
instance: ceph部署完查看目前是没有获取到ceph的数据的,因为我们现在还没有拿到数据

四、ceph mgr prometheus插件配置
这里去获取ceph的数据的方式有很多种,比如使用ceph-exporter是采集ceph集群数据的客户端程序运的,在nautilus版本中可以直接开启这个进程,开启之后就会自动的将数据拿到,然后通过prometheus进行收集起来,再通过grafana将ceph的图形展示出来
这个在ceph管理节点开启
# ceph mgr module enable prometheus
# netstat -nltp | grep mgr 检查端口
tcp 0 0 0.0.0.0:6800 0.0.0.0:* LISTEN 10311/ceph-mgr
tcp 0 0 0.0.0.0:6801 0.0.0.0:* LISTEN 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.10:45594 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.11:51040 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.11:51044 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.10:45602 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.10:45600 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.11:51042 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.12:60668 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.12:60666 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:45600 192.168.1.10:6800 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.11:51038 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.12:60670 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:33400 192.168.1.10:3300 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.10:45598 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.10:45596 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.12:60672 ESTABLISHED 10311/ceph-mgr
tcp 0 0 192.168.1.10:6800 192.168.1.10:45592 ESTABLISHED 10311/ceph-mgr
tcp6 0 0 :::9283 :::* LISTEN 10311/ceph-mgr
tcp6 0 0 192.168.1.10:9283 192.168.1.15:22202 ESTABLISHED 10311/ceph-mgr
# curl 192.168.1.10:9283/metrics 测试返回值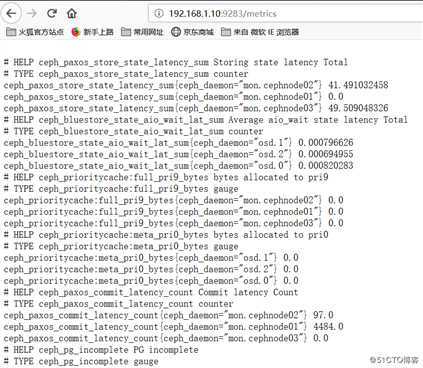
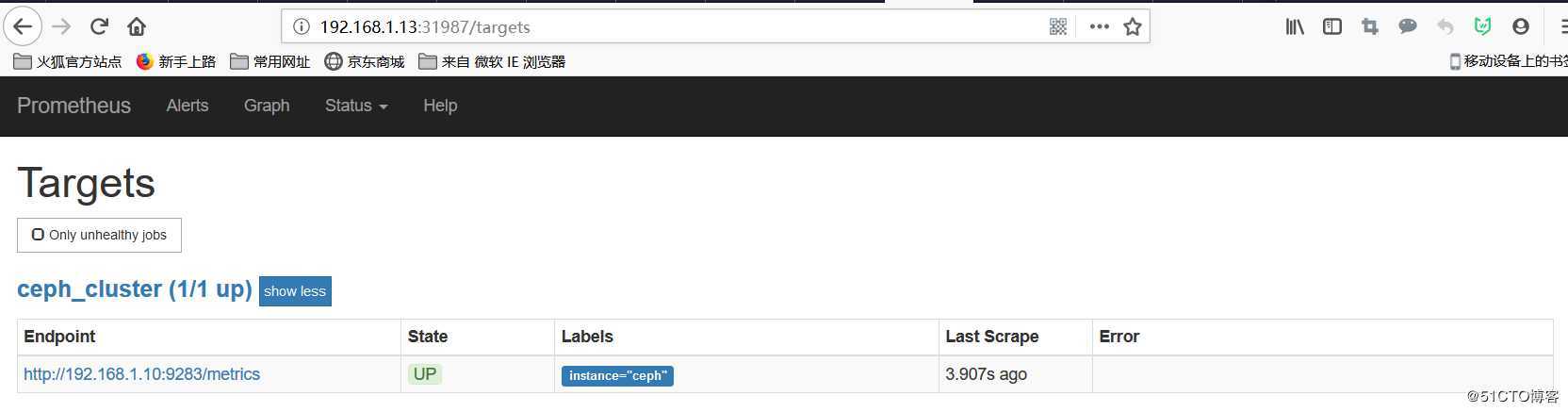
查看数据已经被prometheus收集到,并显示为UP状态
1)、浏览器登录 grafana 管理界面
2)、添加data sources,点击configuration--》data sources
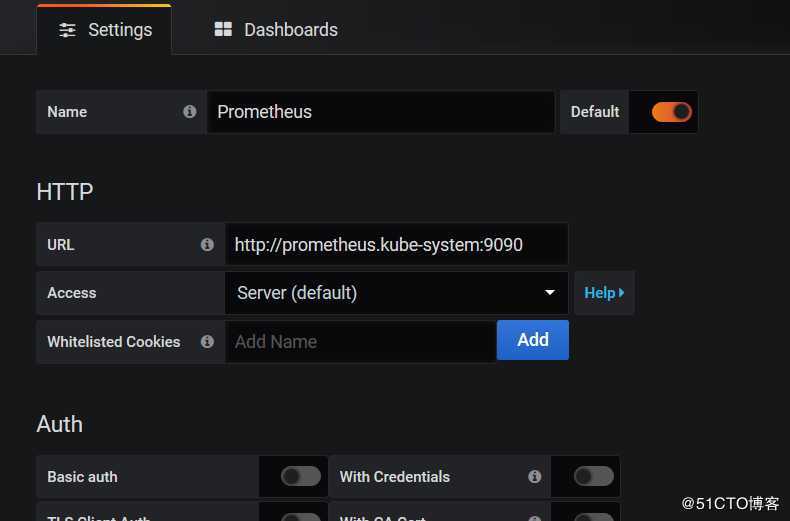
3)、grafana官方提供了很多的模版
https://grafana.com/grafana/dashboards
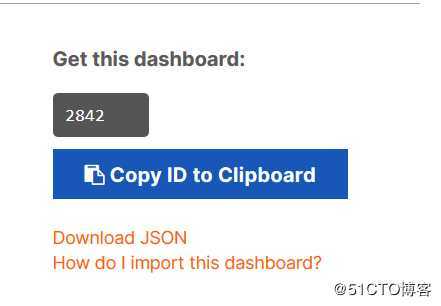
4)、搜索ceph的dashboard ,这里我选择的是2842这个模版,这个主要是监控集群
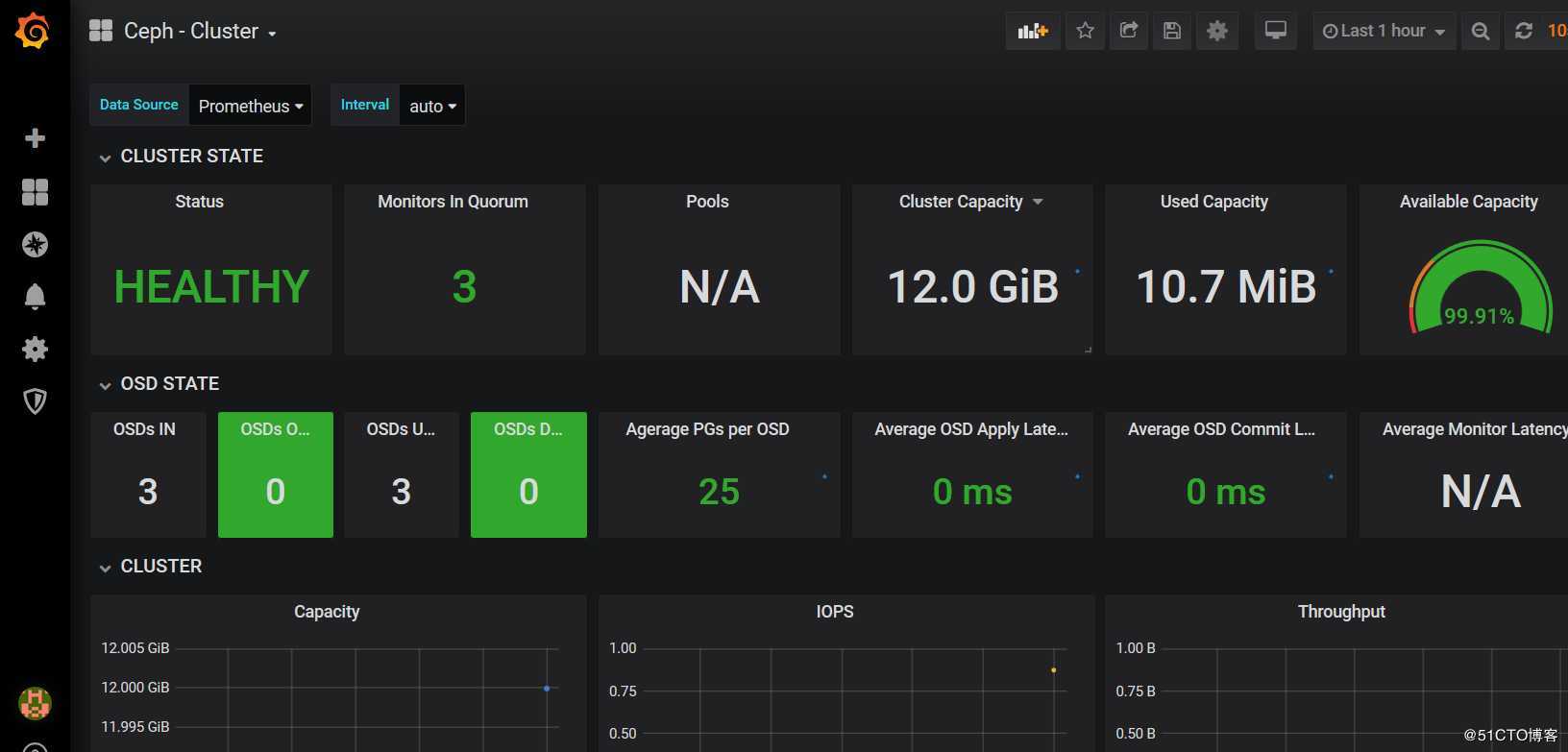
5.1、监控Ceph-cluster集群
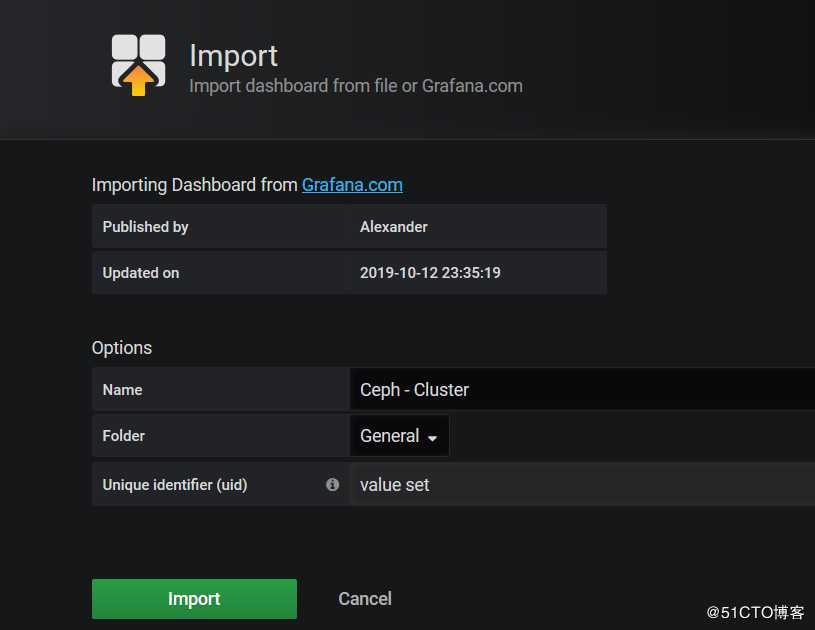
5、import导入
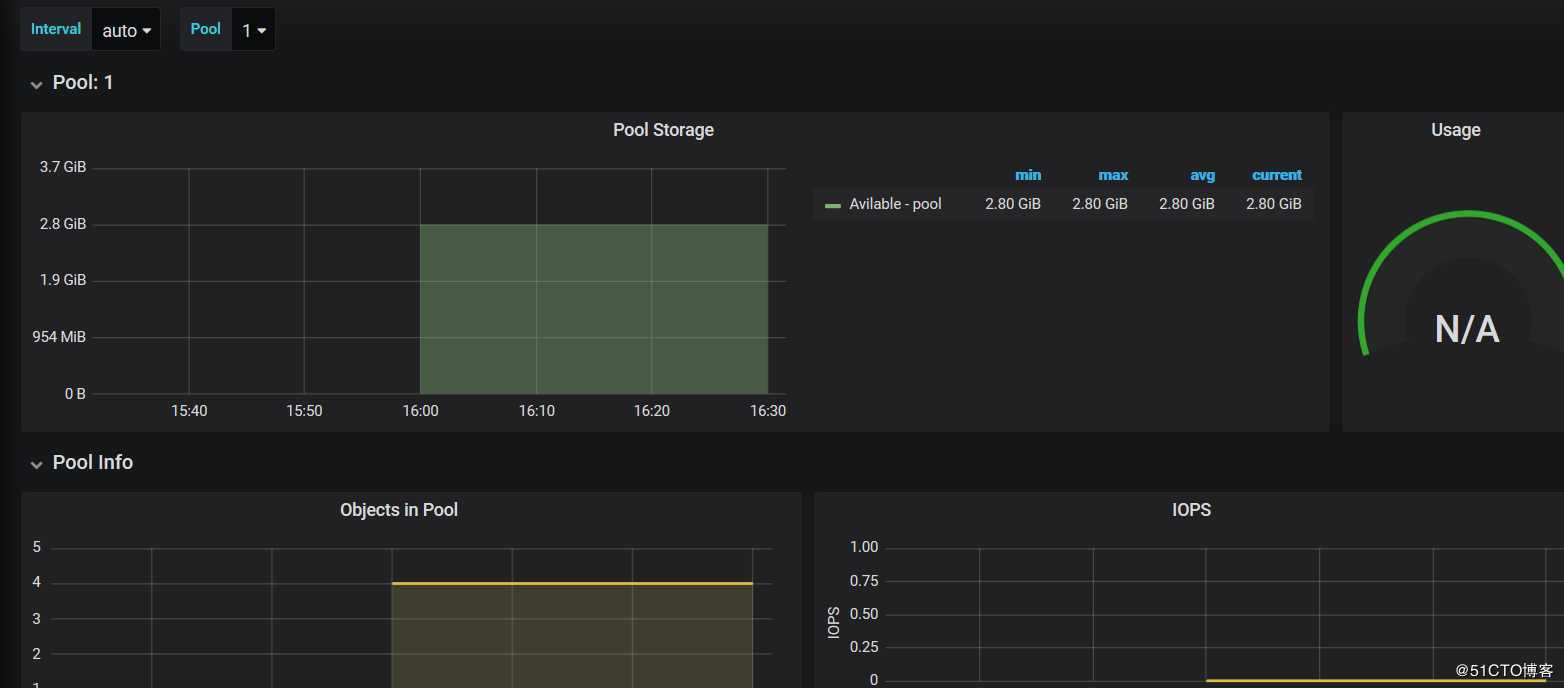
这样就监控到我们的ceph集群的状态了,并可以看到ceph的pools、OSD等相关数据
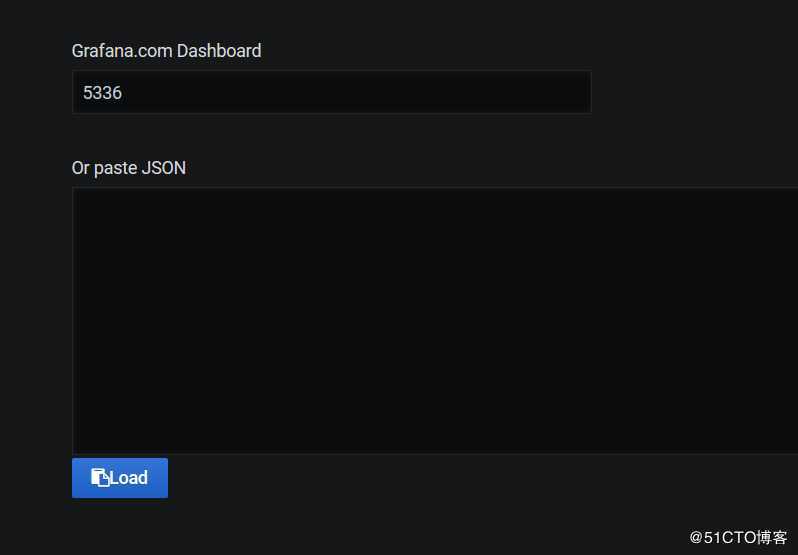
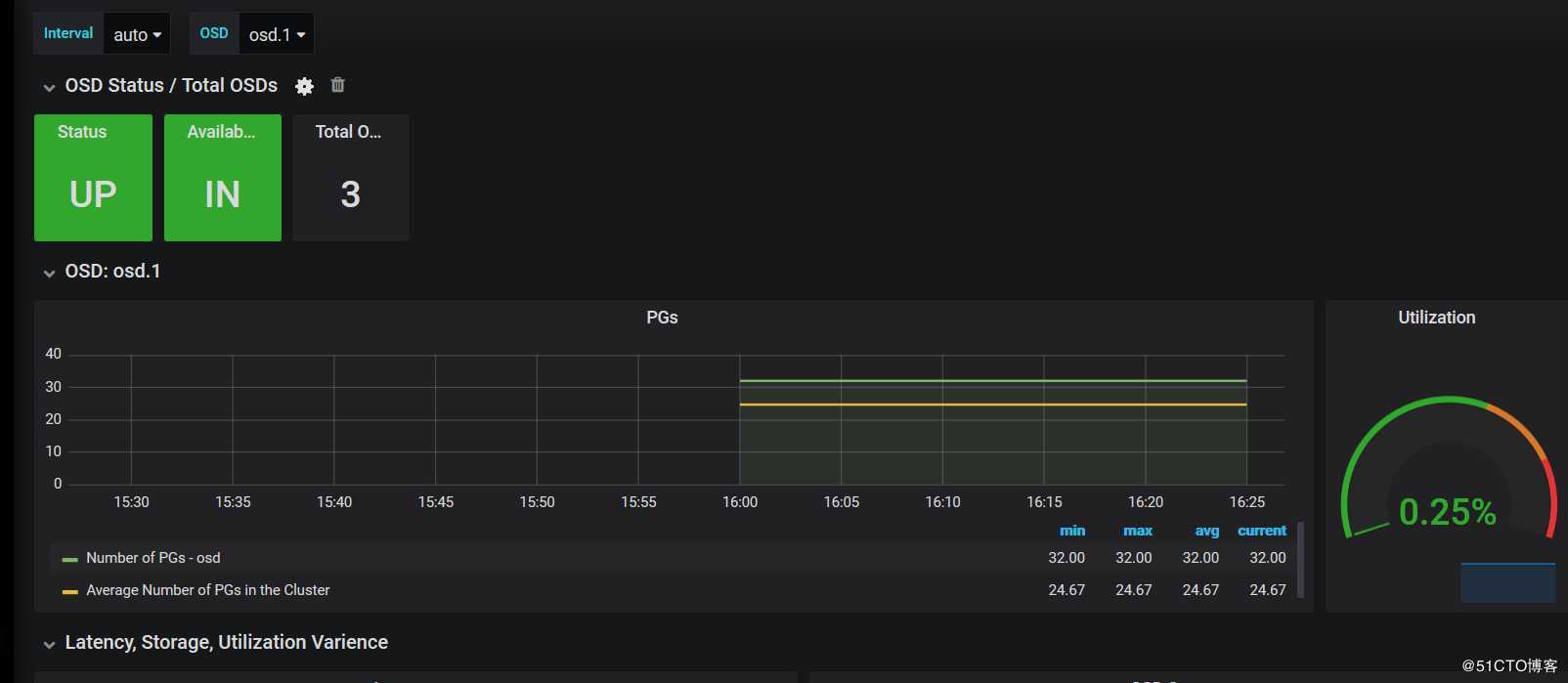
5.2、监控OSD,模版编号5336
5.3、监控POOLS ,监控模版编号5342
import导入模版
原文:https://blog.51cto.com/14143894/2478095