parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:
那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。
首先,导入库文件和配置环境:
import os from pyspark import SparkContext, SparkConf from pyspark.sql.session import SparkSession os.environ["PYSPARK_PYTHON"]="/usr/bin/python3" #多个python版本时需要指定 conf = SparkConf().setAppName(‘test_parquet‘) sc = SparkContext(‘local‘, ‘test‘, conf=conf) spark = SparkSession(sc)
然后,使用spark进行读取,得到DataFrame格式的数据:host:port 属于主机和端口号
parquetFile = r"hdfs://host:port/Felix_test/test_data.parquet" df = spark.read.parquet(parquetFile)
而,DataFrame格式数据有一些方法可以使用,例如:
1. df.first() :显示第一条数据,Row格式
print(df.first())
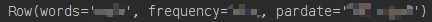
2. df.columns:列名
3. df.count():数据量,数据条数
4. df.toPandas():从spark的DataFrame格式数据转到Pandas数据结构
5. df.show():直接显示表数据
6. type(df):显数据示格式

参考:
https://blog.csdn.net/worldchinalee/article/details/82781263
原文:https://www.cnblogs.com/qi-yuan-008/p/12493082.html