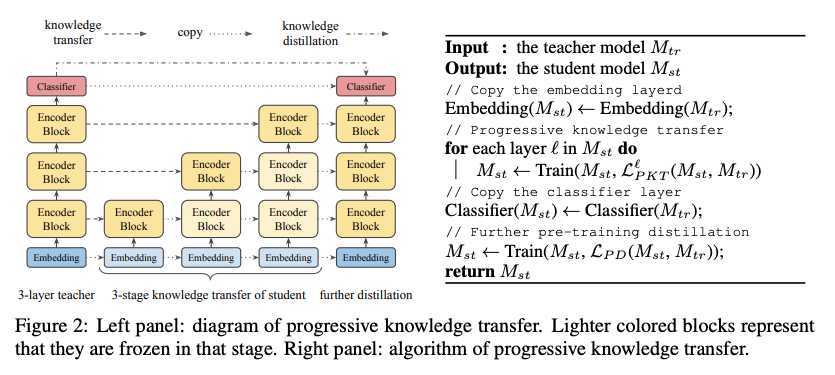
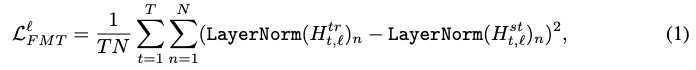
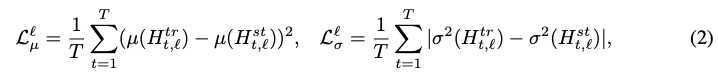
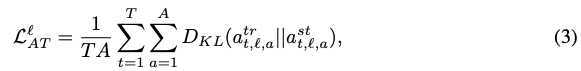
作者在这里构造了四类损失函数来对模型中各层的参数进行约束来训练模型,具体模型结构如下:
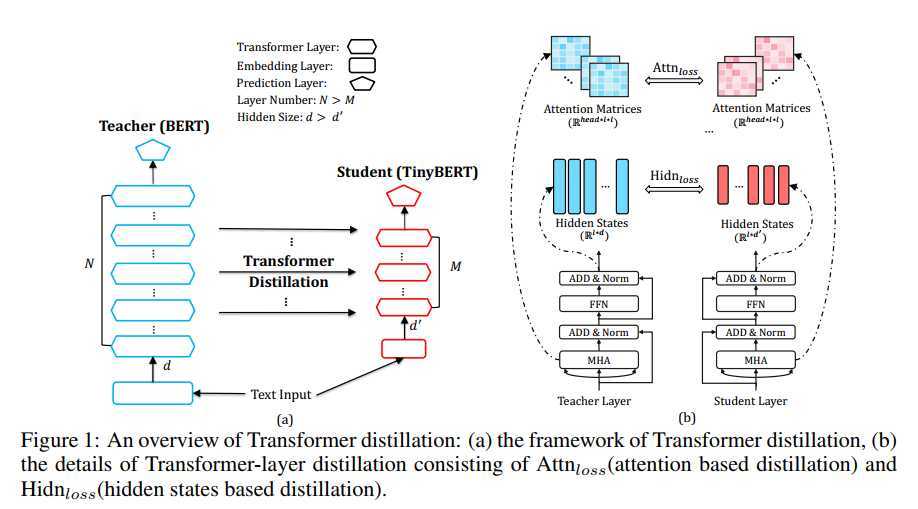
作者构造了四类损失,分别针对embedding layer,attention 权重矩阵,隐层输出,predict layer。可以将这个统一到一个损失函数中:
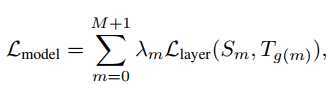
上面式子中????λm表示每一层对应的系数,????Sm表示studnet网络的第m层,????(??)Tg(m)表示teacher网络的第n层,其中??=??(??)n=g(m)。并且有??(0)=0g(0)=0,??(??+1)=??+1g(M+1)=N+1,0表示embedding layer,M+1和N+1表示perdict layer。
针对上面四层具体的损失函数表达式如下:
attention 权重矩阵
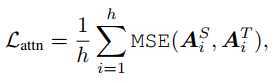
h为multi attention中头数
隐层输出
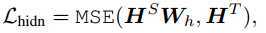
因为student网络的隐层大小通常会设置的比teacher的小,因此为了在计算时维度一致,这里用一个矩阵???Wh将student的隐层向量线性映射到和teacher同样的空间下。
embedding layer
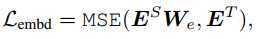
????Ws同理上。
以上三种损失函数都采用了MSE,主要是为了将模型的各项参数对齐。
predict layer
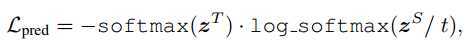
predict layer也就是softmax层,在这里的损失函数是交叉熵,t是温度参数,在这里设置为1。
以上四种损失函数是作者针对transformer提出的知识蒸馏方法。除此之外作者认为除了对pre-training蒸馏之外,在fine-tuning时也利用teacher的知识来训练模型可以取得在下游任务更好的效果。因此作者提出了两阶段知识蒸馏,如下图所示:
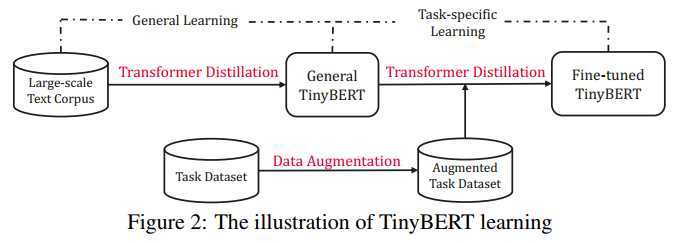
本质上就是在pre-training蒸馏一个general TinyBERT,然后再在general TinyBERT的基础上利用task-bert上再蒸馏出fine-tuned TinyBERT。
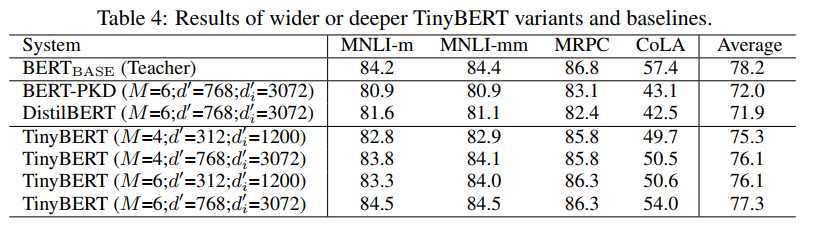
作者给出了TinyBERT的效果:
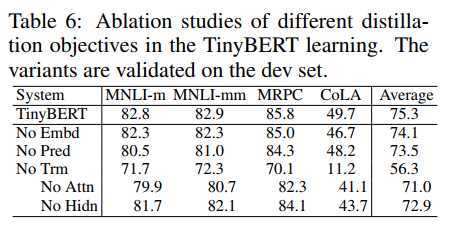
另外作者也给出了四种损失对最终结果的贡献:
还有就是关于??=??(??)n=g(m)这个式子中??(??)g(m)怎么选择,假设student的层数为4层,这里的??=??(??)=3??n=g(m)=3m,作者将这种称为Uniform-strategy。另外作者还和其他的??(??)g(m)做了对比:

Top-strategy指用teacher最后4层,Bottom-strategy指用前面4层,其实这里的映射函数,我感觉可能还有更优的方案,例如取平均,或者用attention来做,可能效果会更好。