磁盘:
ms级别内存:
ns级别从寻址的速度上,磁盘比内存慢了10W倍
磁盘有磁道、扇区,一扇区为512 Byte,如果每次从磁盘读取512 Byte会带来一个成本问题,即索引体积太大,所以操作系统无论读多少数据,最少从磁盘读取4K大小的数据。
一般操作系统
4K,不会造成浪费,也支持存储一些小文件,假如说服务器想做视频录像之类的,4K大小的话,就有点得不偿失,不如换的大一点,一次性读的东西多一些,减少磁盘寻址时间。4K大小其实取决于上层应用对IO的使用量,是IO密集型还是一些小文件。
开始数据是存储在文件中的,随着文件变大,数据增多,查询会变慢。为什么?磁盘I/O成为瓶颈,数据库出现,定义每个data page 大小为4K,把数据存储到一个个的data page中,与操作系统读取数据大小一致,即每次都是一次I/O,但是此时还是全量IO,并没有加快查询速度,必须建立索引,索引也是4K大小,指向每个data page。数据和索引都是存储在磁盘中的,在内存中还有一个B+树(树干),流程为:用户请求,命中索引,索引加载到内存,然后解析完,得知下次该读取哪一页上的数据,再将其加载到内存读取。充分利用内存读取快,磁盘存储容量大的特点。
关系型数据库在建表的时候,都必须给出
schema,类型:字节宽度,即固定大小,即使没有给出具体值,也会用占位来填充,存储的时候倾向于行级存储,这样每次修改数据的时候,直接填充或覆盖数据,不会造成移动数据。
这里引出一个问题:数据库表数据量大的时候,性能下降?(从寻址和带宽两个方面回答)
前提:如果表有索引
增删改:会变慢,因为要维护索引,即索引中的数据需要移动。
查询速度:
如果是1个或少量请求的话,查询速度依然很快。
如果是大量并发请求,而刚好查询的数据又落在不同的page页上,磁盘的带宽会影响查询速度。原因是需要依次把page页上的数据加载到内存,当数据量大的时候,就会很慢。
基于纯磁盘速度慢,纯内存数据库SAP HANA太奢侈,缓存技术诞生。
?Memcached也是k,v存储形式,但是value没有类型的概念,而Redis的value有类型的概念。
通常存储数据的方式有三种:
- k = 1 k = a
- k = [1,2,3] k = [a,b,c]
- k = {k=a} k = {[1,2],[3,4],[5,6]}
操作系统都有kernel,每个client连接都会先连接到kernel,Redis进程与内核之间使用的是epoll,非阻塞多路复用,epoll是系统内核提供的一种系统调用,来遍历多个client连接,谁有请求就处理谁。
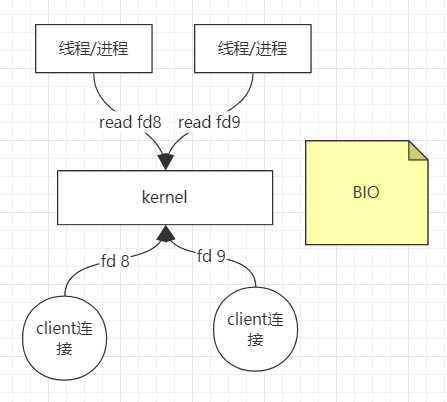
BIO:早期的BIO模型,客户端连接系统内核后,线程从内核中读取文件,只能是read读取(socket blocking),如果没有数据,则会一直阻塞,所以只能开辟多个线程/进程处理。如果只有一个cpu的话,某一时间片上的某一时间点的cpu是空闲的,并不是一直在处理,导致资源浪费,线程过多的话,切换上下文需要成本,硬件没有被充分利用。问题:上下文切换成本高,资源浪费。
Linux系统中一切皆文件,都由文件描述符
fd(file descriptor)来表示,0是标准输入,1是标准输出,2是错误输出,再开启新的IO会产生更多的描述符
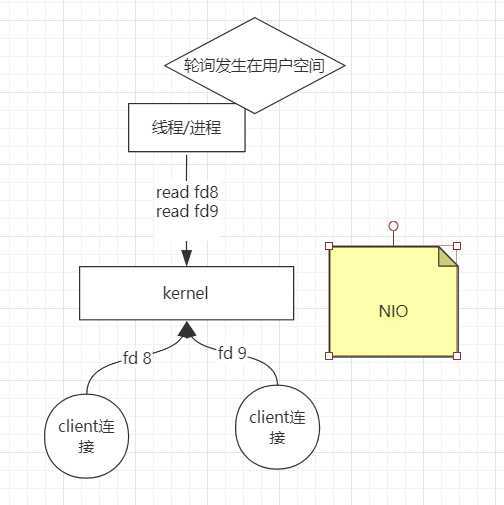
NIO:于是内核发生变化,内核中的socket可以是non-block的,此时只需要一个线程/进程处理,轮询文件描述符,轮询发生在用户空间。此时是同步非阻塞NIO。此时出现了一个成本问题,如果有1000个fd,用户进程需要调用1000次kernel。
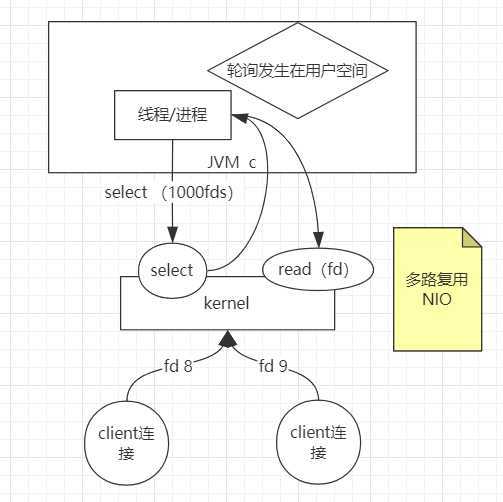
多路复用NIO:于是内核继续升级,由用户轮询改为内核轮询,内核增加了一个系统调用select,(用man指令看select),支持一次性传多个fds,把1000个fd传给kernel之后,由kernel来轮询哪些连接有数据(相当于过滤一遍),然后再返回给线程/进程,此时再循环去读返回的fds,减少了用户态与内核态的切换。此时为多路复用NIO。此时的问题是,用户态和内核态之间 fd拷来拷去。
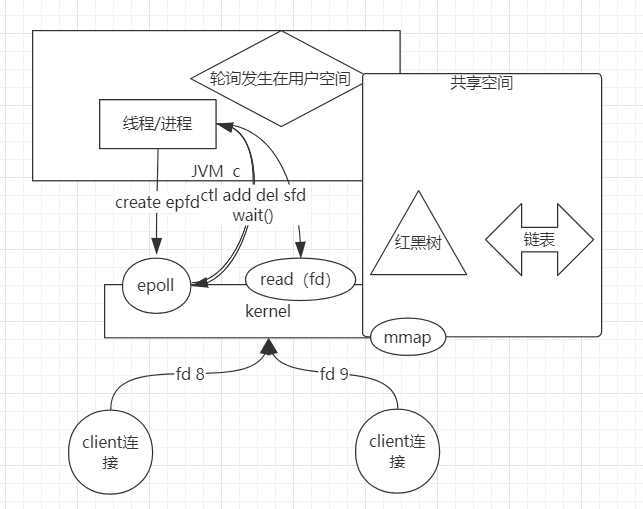
共享空间:进程有进程的内存空间,内核有内核的内存空间,进程是无法访问内核空间的,所以内核提供了系统调用方法。为了解决这个问题,于是内核与用户之间有了共享空间,系统调用为mmap内存映射,共享空间数据结构为红黑树+链表,线程/进程就可以把之前的1000个fds放到共享空间(红黑树)中,然后kernel从中读取fd通过所有的IO处理,把准备好的数据放到链表里,上层用户空间就可以直接从链表中读取。
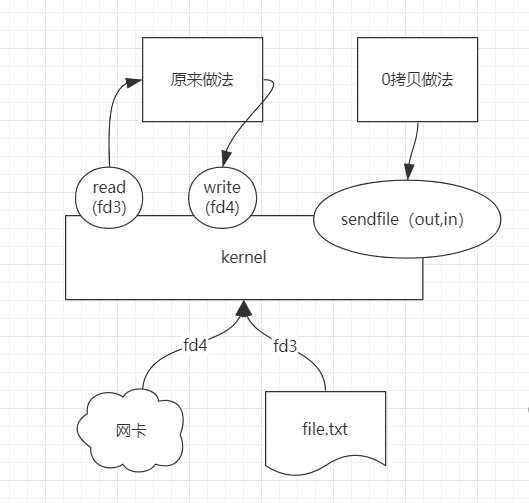
网卡、文件都有IO,传统的用户去读写的时候,是先从kernel中read数据,再write到kernel,这个过程会有数据拷贝。内核提供了一个sendfile的系统调用,直接把out、in一块传入,由kernel直接读写,实现零拷贝。
原文:https://www.cnblogs.com/tobyhomels/p/12505681.html