Introduction
(1)Motivation:
当前很少的ReID工作关注到了跨模态的匹配(cross-modality)。作者的工作集中在RGB图像和IR图像的匹配上,如下图示例:

(2)Contribution:
① 设计了跨模态生成对抗网络cmGAN,也是首次采用GAN来解决跨模态ReID问题;
② 设计了一个联合损失函数,结合了id损失和跨模态三元组损失;
The Proposed cmGAN
(1)问题定义:
RGB图像集合定义为 V,IR图像集合定义为 I,多模态集合可以表示为:![]() ,其中
,其中![]() 表示训练集,
表示训练集,![]() 表示测试集。
表示测试集。![]() 为RGB图像提取的特征向量,
为RGB图像提取的特征向量,![]() 为IR图像提取的特征向量。假定
为IR图像提取的特征向量。假定![]() 包含 n 个训练图像,对应的label为
包含 n 个训练图像,对应的label为![]() 。
。
(2)提出的方法:
① 框架:
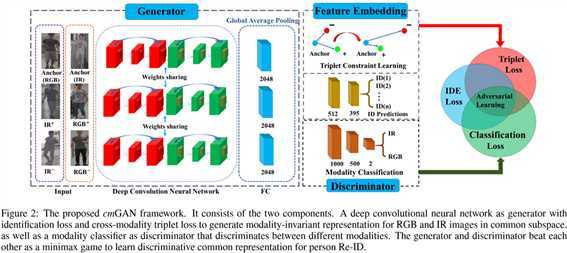
② 生成器:
上述的网络通过softmax和全局平均池化,输出每个ID的概率,类内特征投影损失为:
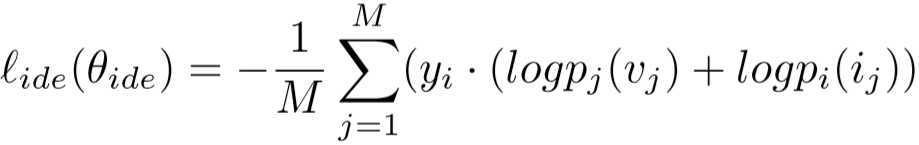
其中 p 表示该图片属于任意一个ID的概率,可以理解为:log部分是 M 个行人对应的两张不同模态的图片被判为不同ID的可能性,再同它本身的标签相乘,可能性和标签视为向量的相乘,得到了 M 个行人预测正确的可能性总和。但有一个不理解的地方:y的下标为什么是 i ?
令输入的不同模态特征为:![]() 或
或![]() ,则三元组损失为:
,则三元组损失为:
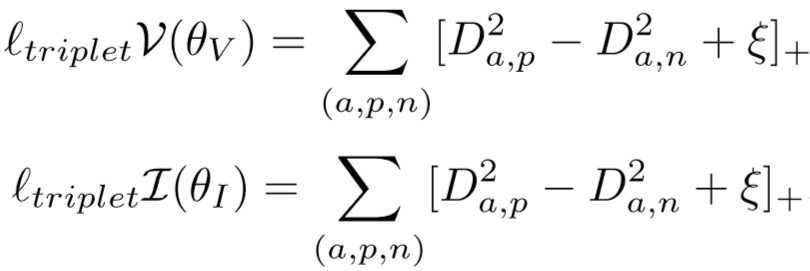
![]()
两个损失函数进行结合,得到生成器的目标函数:
![]()
③ 判别器:
用来判断特征向量是否属于同一个模态,判别损失为:
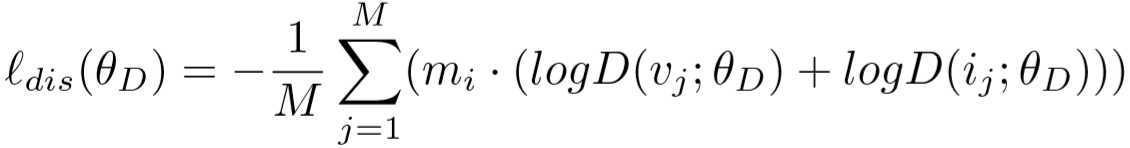
不理解 m 的下标为什么是 i ?而且RGB和IR的 m 不应该指定同一个?
(3)训练算法:
分成以下两步:
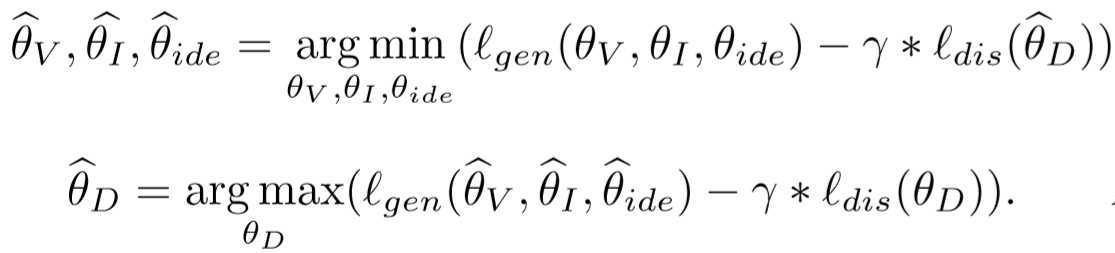
先训练生成器,使得生成器能够让不同模态的同ID行人更靠近;再训练判别器,使其能够很好的分辨输入的图片是RGB还是IR。
我有一个疑问:我的理解下,这两步的参数并不共享,虽然写在一个目标函数上,但在优化过程是单独的,我在更新![]() 的时候,对下一步更新
的时候,对下一步更新![]() 没有什么影响吧,对他们而言
没有什么影响吧,对他们而言![]() 可以看成常量,那这样怎么进行对抗训练呢?
可以看成常量,那这样怎么进行对抗训练呢?
算法流程:

Experiment
(1)实验设置:
① 数据集设置:SYSU RGB-IR RE-ID;
② 实验细节:采用ResNet-50作为基础网络;
③ 参数设置:batch size = 20,generative model training step K = 5,γ = 0.05,ξ = [0.7, 0.9, 1.2, 1.4, 1.5, 1.6](1.4最佳),α:β = 1:1,generator lr = 0.0001,discriminator lr= 0.001,epochs = 2000。
(2)实验结果:
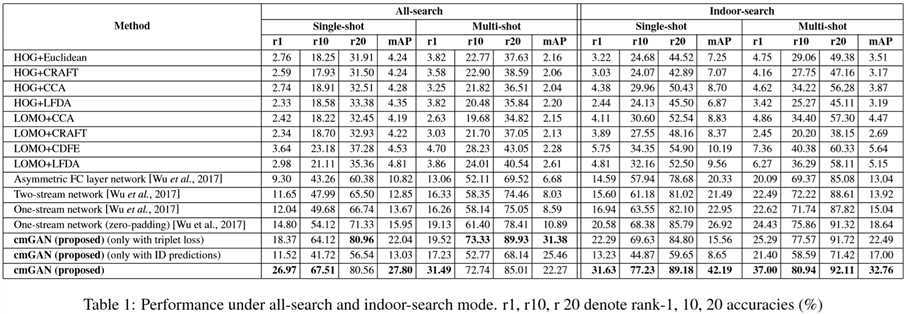
论文阅读笔记(二十八)【IJCAI2018】:Cross-Modality Person Re-Identi?cation with Generative Adversarial Training
原文:https://www.cnblogs.com/orangecyh/p/12517648.html