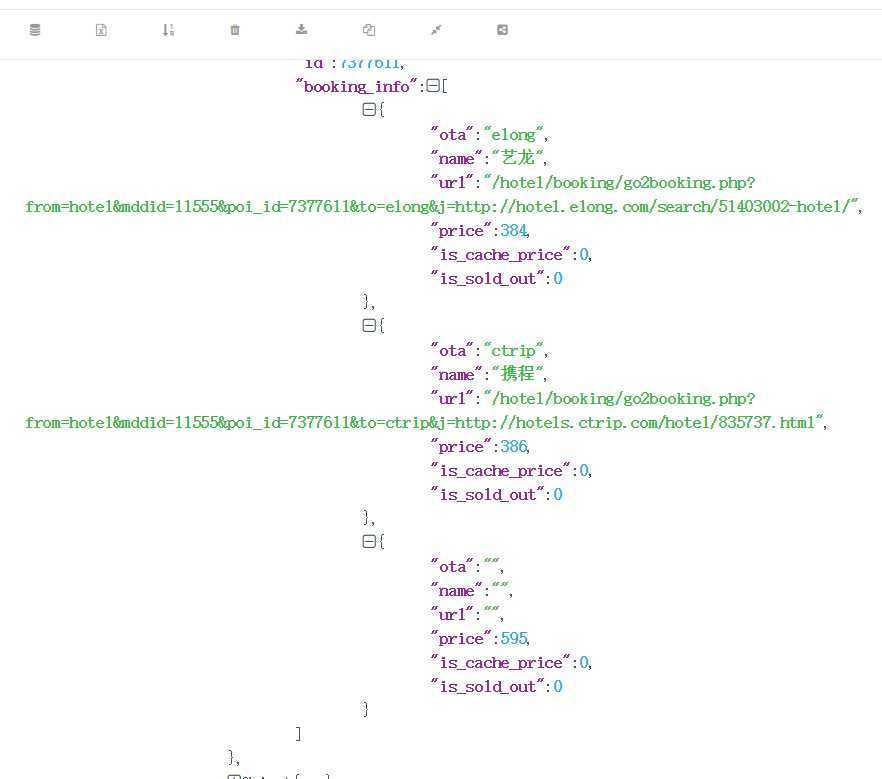
1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 import numpy as np 5 import json 6 headers = {‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘} #请求头的问题 7 url=‘http://www.mafengwo.cn/rest/hotel/booking/?page%5Bmode%5D=random_next&page%5Bnum%5D=15&page%5Bno%5D=1&filter%5Bpoi_ids%5D=7377611S17199S97620S97635S97609S9161215S97581S8346673S35108740S6959583S7859685S7377583S7115430S15846780S9161213&filter%5Bcheck_in%5D=2020-04-26&filter%5Bcheck_out%5D=2020-04-27‘ 8 response=requests.get(url,headers=headers) #获取url以及访问网站 9 10 result=response.text #使用response对象中的属性,获取响应的内容,类型:字符串 11 result_dict=json.loads(result) #使用json模块将str类型变为python中的字典类型 12 data_list=result_dict[‘data‘][‘list‘] #获取data数据 13 hotel_price=[] 14 for i in data_list: 15 price_list=i[‘booking_info‘] 16 for j in price_list: 17 price=j[‘price‘] 18 hotel_price.append(price) 19 #因为有三种不同的价格,所以这里全都给出 20 first_price=hotel_price[::3] 21 second_price=hotel_price[1::3] 22 third_price=hotel_price[2::3] 23 third_price.append(220) 24 25 26 r = requests.get(‘http://www.mafengwo.cn/search/q.php?q=泉州&t=hotels&seid=&mxid=&mid=&mname=&kt=1‘, headers = kv) 27 #print(r.text) 页面结构和内容 28 r.raise_for_status() 29 soup = BeautifulSoup(r.content, ‘html.parser‘) #对获得的内容进行处理 30 hotel_names = soup.find_all(‘h3‘) 31 name=[] 32 for hotel_name in hotel_names: #对获取的酒店信息进行处理 33 hotel_namel=hotel_name.text.strip() 34 name.append(hotel_namel) 35 #通过索引设置排名 36 index=[‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘,‘9‘,‘10‘,‘11‘,‘12‘,‘13‘,37 ‘14‘,‘15‘] 38 hotel={‘酒店名称‘:name,"艺龙价格":first_price,‘携程价格‘:second_price,39 "有鱼订房价格":third_price} 40 hotell=pd.DataFrame(hotel,index) #将数据整合 41 print(hotell)
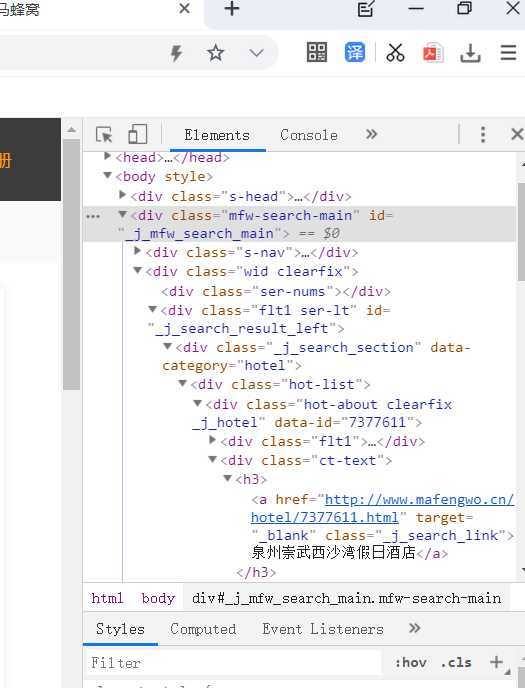
获取酒店的名称

原文:https://www.cnblogs.com/luoi/p/12520512.html