准备三台客户机(安装JDK8,关闭防火墙,静态ip,主机名称)
修改etc/hosts文件
192.168.138.102 hadoop102
192.168.138.103 hadoop103
192.168.138.104 hadoop104
scp可以实现服务器与服务器之间的数据拷贝;
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
scp -r 192.168.138.55:/opt/module/hadoop 192.168.138.66:/opt/module
scp -r 192.168.138.55:/opt/module/hadoop 192.168.138.77:/opt/module
rsync远程同步工具,主要用于备份和镜像。具有速度块,避免复制相同内容和支持符号链接的优点;
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所以文件都复制过去;
man rsync | more
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
#命令 命令参数 要拷贝的文件路径/名称 目的用户@主机:目的路径

rsync -rvl /opt/software/* 192.168.138.66:/opt/software/
rsync -rvl /opt/module 192.168.138.77:/opt/
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<104; host++)); do
echo --------------------- hadoop$host ----------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
chmod 777 xsync
./xsync xsync
hadoop55 hadoop66 hadoop77
HDFS NameNode DataNode SecondaryNameNode
DataNode DataNode
YARN NodeManager ResourceManager
NodeManager NodeManager
<configuration>
<!--NameNode的IP地址和端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data/temp</value>
</property>
</configuration>
<configuration>
<!--指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
</configuration>
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
# some Java parameters
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
</configuration>
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
<configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
./xsync /opt/module/hadoop/
bin/hdfs namenode -format
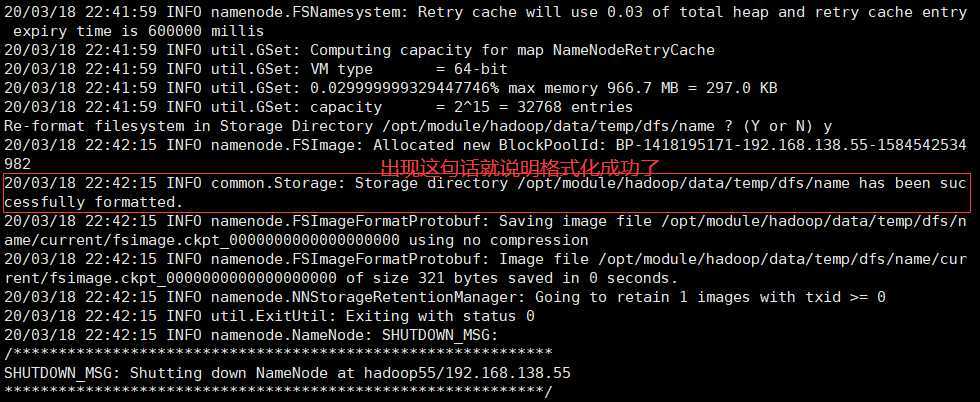
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
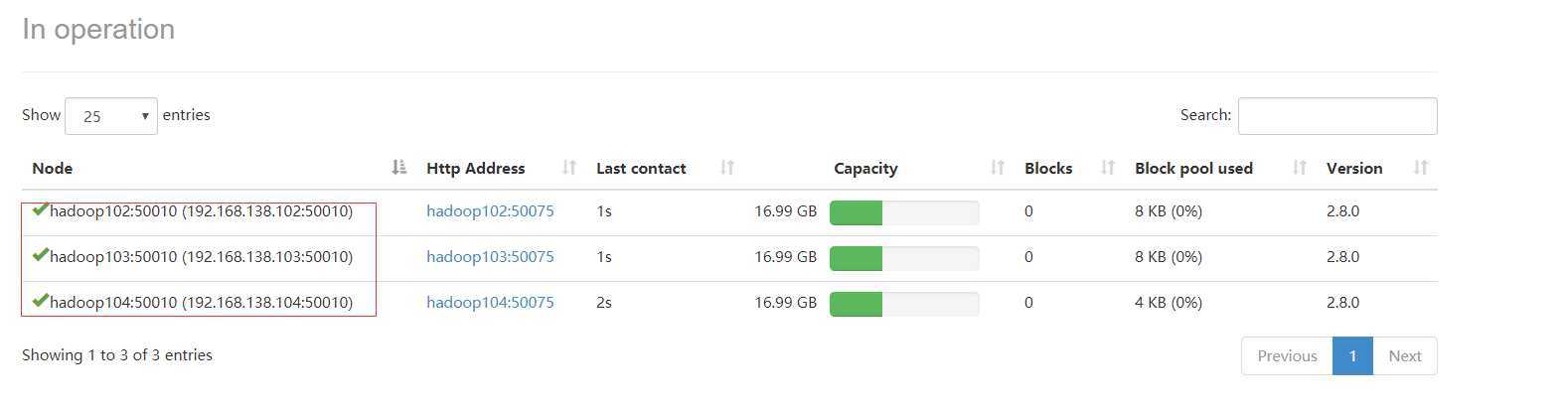
解决方案如下:
1.查看/etc/hosts是否配置了所有从节点的hostname到ip的映射关系;
2.在namenode的机器上修改hafs.site.xml文件,加入配置后,DataNode重新启动
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
SSH之所以能够保证安全,原因在于它采用了公钥加密,过程如下:
1.远程主机收到用户的登录请求,把自己的公钥发给用户;
2.用户使用这个公钥,将登录密码加密后,发送回来;
3.远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录;
假如用户名为java,登录远程主机名为Linux,命令如下:
$ssh java@linux
SSH默认端口为22,也就是说,你的登录请求会发进远程主机的22端口。使用p参数,可以修改这个端口,例如改为88端口,命令如下:
$ssh -p 88@linux
注意:如果出现错误提供:ssh:Could not resolve hostname linux:Name or service not known,则是因为Linux主机为添加本主机的Name Server中,故不能识别,需要在/etc/hosts里添加进该主机及对应IP即可:
linux 192.168.138.102
Master作为客户端,要实现无密码公钥认证,连接搭到服务器salve上时,需要在master上生成一个密钥对,包含一个公钥和一个私钥,而后将公钥复制到所以逇salve上。当master通过ssh连接salve是,salve就会生成一个随机数并用master的公钥对随机数进行加密,并发送给master。master收到加密数之后再用私钥解密,并将解密后数回传给slave确认解密数无误之后就允许master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。
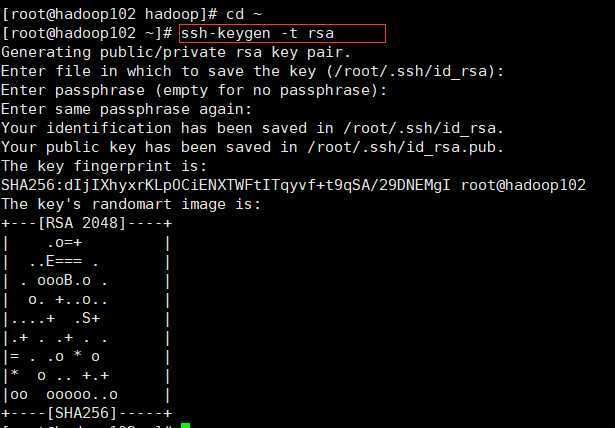
ssh-keygen -t rsa
运行后询问其保存路径时直接回车即可,采用默认路径;
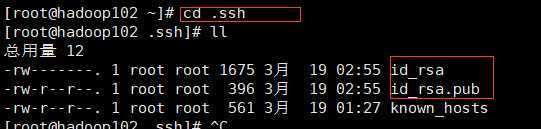
生成的密钥对:id_rsa(私钥),id_rsa.pub(公钥),默认存储在‘/用户名/.ssh’目录下;
cd .ssh
ssh-copy-id hadoop103
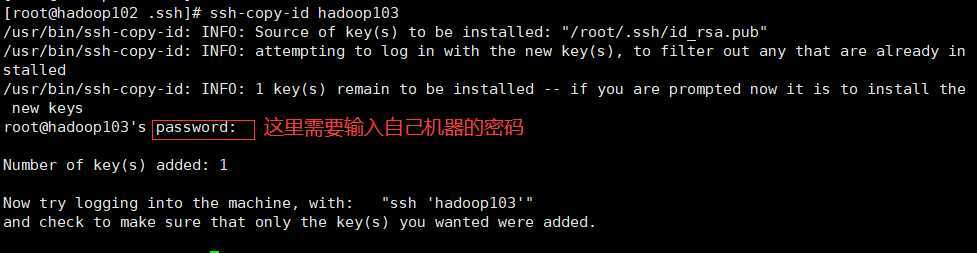
查看hadoop103是否传送成功

ssh hadoop103
![]()
(1)known_hosts :记录ssh访问过计算机的公钥(public key)
(2)id_rsa :生成的私钥
(3)id_rsa.pub :生成的公钥
(4)authorized_keys :存放授权过得无密登录服务器公钥
cd /opt/module/hadoop/etc/hadoop/
vim slaves
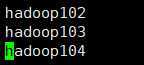
配置完成后,分发给其他节点
./xsync /opt/module/hadoop/etc/hadoop/
bin/hdfs namenode -format
start-dfs.sh

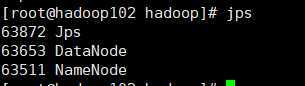
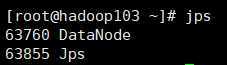
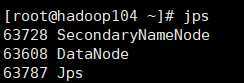
start-yarn.sh

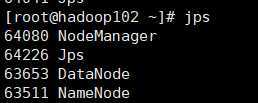
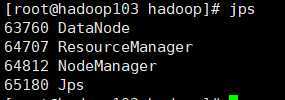
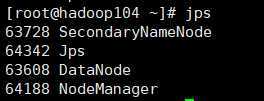
HDFS:http://192.168.138.102:50070

YARN:http://192.168.138.103:8088

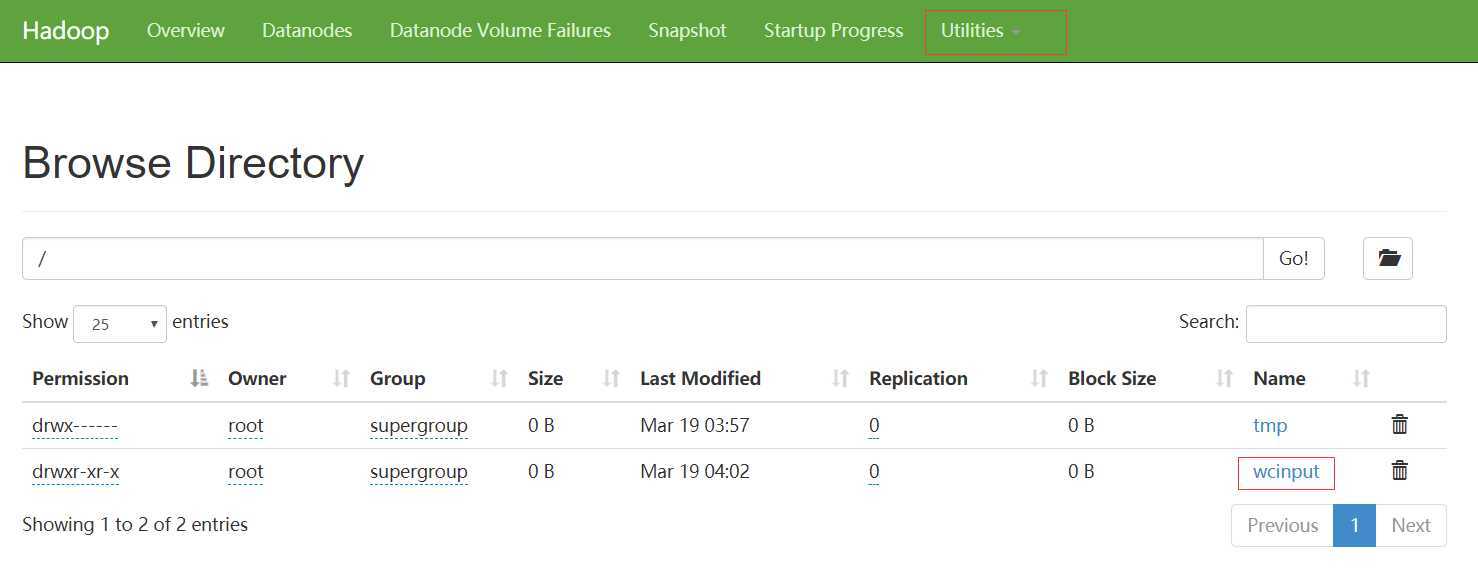
mkdir wcinput
cd wcinput
touch wc.input
vim wc.input
hadoop fs -put wcinput /
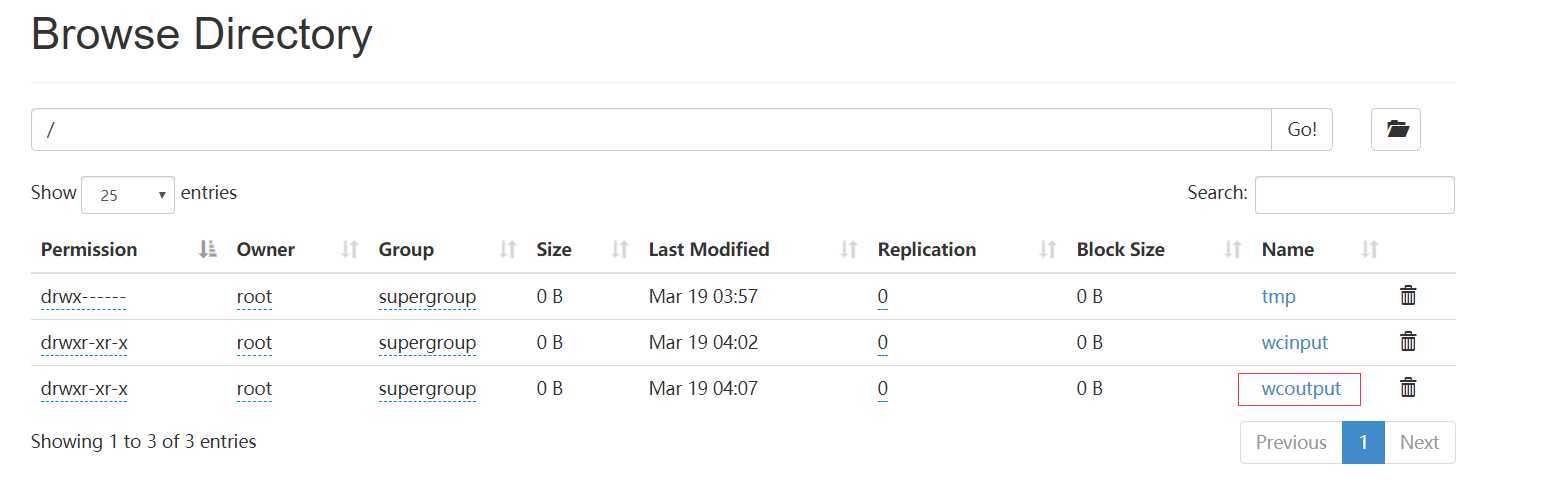
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /wcinput /wcoutput
hadoop fs -cat /wcoutput/*
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
yarn-daemon.sh start|stop resourcemanager|nodemanager
start-dfs.sh
stop-dfs.sh
start-yarn.sh
stop-yarn.sh
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
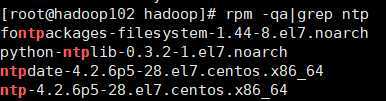
rpm -qa|grep ntp
service ntpd status

如果开启需要关闭,然后进行下面的操作;
vim /etc/ntp.conf
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap

server 127.127.1.0
fudge 127.127.1.0 stratum 10
vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
service ntpd start
crontab -e
编写内容如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102
date -s "2017-9-11 11:11:11"
date
原文:https://www.cnblogs.com/wnwn/p/12521746.html