Drop是一个智能的奖励平台,旨在通过奖励会员在他们喜爱的品牌购物时获得的Drop积分来提升会员的生活,同时帮助他们发现与他们生活方式产生共鸣的新品牌。实现这一体验的核心是Drop致力于在整个公司内推广以数据为基础的文化,Drop的数据用于多种形式,包括但不限于商业智能、测量实验和构建机器学习模型。
为了确保有效地利用数据,工程团队一直在寻找可以改善基础架构以适应当前和未来的需求的方法,与许多其他高成长型初创公司的经验类似,我们对数据的需求规模超过了基础架构的能力,因此需要将以商业智能为中心的数据基础架构演变为可以释放大数据需求和能力的基础架构。
Drop在成立之初就着力构建数据基础架构,以便利用自动报告和仪表板来观察关键业务的指标。我们的第一代数据基础架构使用以AWS Redshift数据仓库为中心的架构,使用Apache Airflow调度自定义批处理ETL作业,使用Looker构建自动化仪表板和报告。
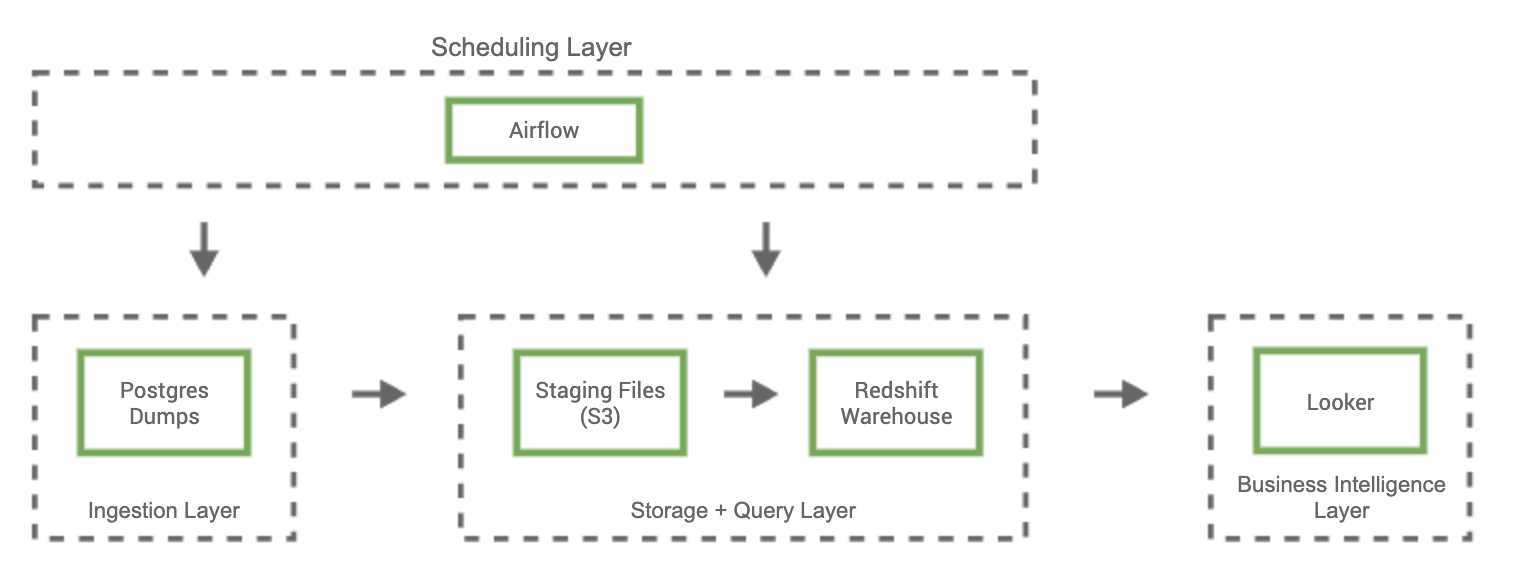
该架构实现了我们的早期目标,但是利用数据的需求已经超出了商业智能的范围。为向会员提供更个性化的体验,我们需要一个支持高级功能的数据平台,例如更深入的分析、全面的实验测量以及机器学习模型的开发,我们也意识到原来架构的技术限制可能会阻止我们解锁那些所需的功能,一些最突出的限制包括:
为解决这些不足并考虑到后续的扩展性,我们需要继续构建数据基础架构。数据湖是一个集中式存储库,能够存储任何规模的非结构化和结构化数据,构建数据湖将使我们能够解决第一代数据基础架构的局限性,同时允许我们保留原始架构的关键组件,这些组件仍然满足后续的长期数据基础架构计划。
当开始构建Drop的数据湖时,我们遵循以下指导原则:

调度层负责管理和执行数据湖中所有工作流程,调度程序会协调数据湖中所有数据的大部分移动,利用Airflow使我们能够通过Airflow有向无环图(DAG)构建所有工作流和基础架构,这也简化了我们的工程开发和部署流程,同时为我们的数据基础架构提供了版本控制,Apache Airflow项目还包含大量支持AWS的集成库和示例DAG,使我们能够快速集成和评估新技术。
当从多个不同的数据源(例如服务器日志,增长营销平台和业务运营服务)拉取数据时,数据主要是从RDS Postgres数据库,以批处理和流处理两种形式提取到数据湖。我们选择AWS Database Migration Services(DMS)来摄取这些表单,因为它与RDS Postgres进行了原生集成,并且能够以批和流形式将数据提取到S3中,DMS复制Postgres“预写日志(WAL)”的数据,以“变更数据捕获(CDC)”任务进入数据湖,并在S3上生成一分钟分区的Apache Parquet文件,此为流处理方式。批处理使用DMS的“全量迁移”任务以将Postgres库表的快照导入S3数据湖,批处理管道由调度层通过Airflow以自定义DAG的形式进行管理,这允许我们控制批快照到S3的调度,并在批运行结束时关闭未使用的DMS资源以降低服务成本。

处理层负责将数据从存储层的“原始(Raw)”部分转换为数据湖的“列式(Columnarized)”部分中的标准化列式和分区结构。我们使用Lambda架构来协调给定数据源的批和流数据,这种数据处理模型使我们能够将高质量的批量快照与一分钟延迟流文件相结合来生成给定数据集的最新列式版本。我们将AWS Glue及其Data Catalog(数据目录)用作数据湖的中央metastore管理服务,metastore包含每个数据集的元数据,例如在S3中的位置、结构定义和整体大小,也可以使用AWS Glue Crawlers捕获和更新该元数据,整个流程如下:
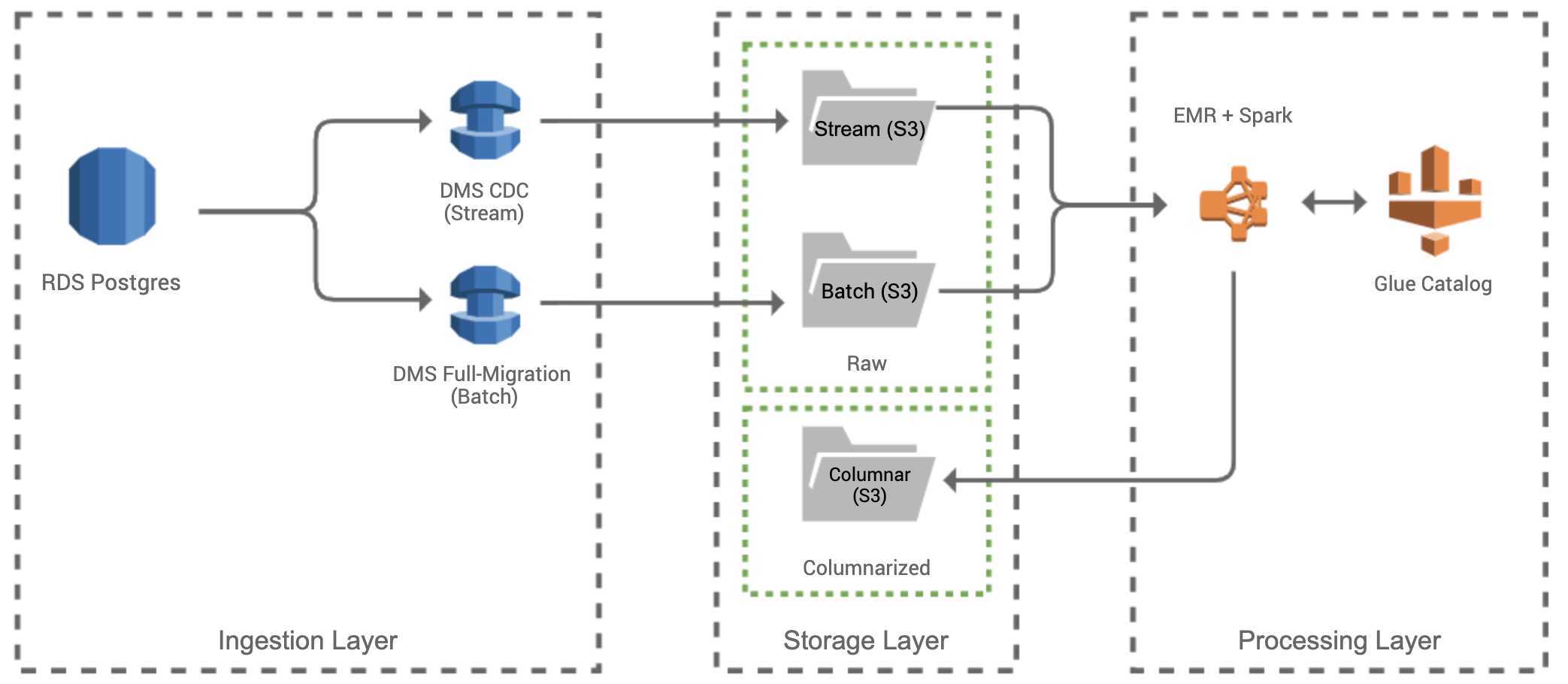
S3作为存储平台的原因有以下三个:易用性、高可靠性和相对低成本。数据存储在存储层中的“原始”和“列式”两部分都基于S3,而“数仓(Warehouse)”中的数据位于Redshift集群中。数据湖中的所有数据首先通过摄入层以各种格式进入“Raw”部分,为了使数据保存到“列式”部分中,数据会通过处理层转换为“列式”部分,并遵守分区标准。我们选择Apache Parquet作为标准列式文件格式,因为Apache Parquet广泛用于数据处理服务中,并且具有性能和存储优势。存储层的“数仓”部分由Redshift数据仓库组成,其数据来自“原始”和“列式”部分。还可以通过数据“热度”对存储层的各部分进行分类,类比于数据的访问频率,“原始”数据数据最冷,“列式”数据比“原始”数据更热,而“数仓”数据是最热的数据,因为它经常会被自动化仪表板和报告访问。S3的另一个优势是我们能够根据数据规模控制成本,对于较冷的数据,我们可以更变S3存储类型或者将数据迁移到AWS Glacier以降低成本。
技术团队和非技术团队都会使用数据湖,以便更好地为决策提供依据并增强整体产品体验,非技术团队通常通过商业智能平台Looker来访问数据,以自动化仪表板和报告的形式监控各项指标。
技术团队应用范围更广,从探索性分析中的即席查询到开发机器学习模型和管道。可以通过AWS Athena托管的Presto服务或通过Redshift数据仓库直接查询数据湖中的数据。AWS Athena还与AWS Glue的数据目录集成,这使Athena可以完全访问我们的中央metastore,这种原生集成使得Athena可以充当S3中存储数据的主要查询服务。我们还能够利用Redshift Spectrum查询S3数据,这在即席查询场景下特别有用,我们也希望使用S3的数据来丰富Redshift集群的数据。为了对机器学习模型进行更正式的探索性分析和开发,需要结合使用Spark和Glue目录来查询或直接与S3中的对象进行交互。
确保数据湖的消费者完全信任数据的准确性至关重要,我们建立了一套全面的检查和监控程序以提醒我们任何意外情况。我们通过Airflow DAG构建的绝大多数数据湖流程,并且能够使用Datadog监视Airflow作业失败,并通过PagerDuty将关键问题转发给工程师。为了建立数据质量检查,我们还构建了一系列Airflow DAG,以生成特定数据集的自定义数据验证指标,我们在给定数据集上运行的一组标准的验证检查和指标包括但不限于空检查、行计数检查和数据延迟指标,这些指标都会被推送到Datadog,这样便可以在其中监视异常并在必要时向参与者发出告警。
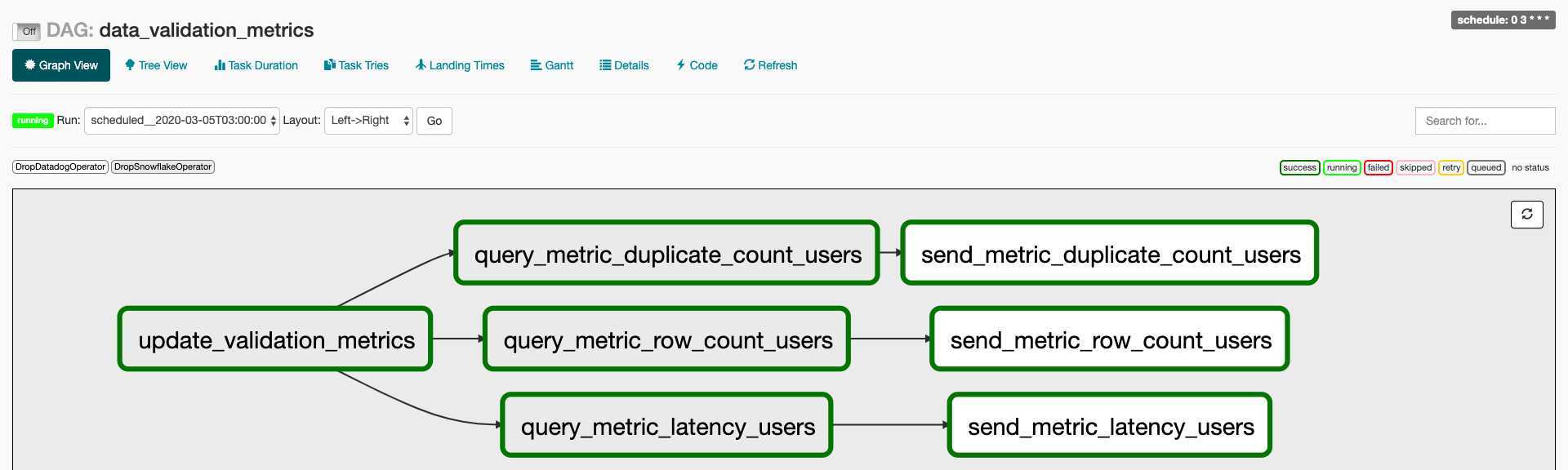
Drop的数据湖现在每天从Postgres数据库中提取十亿条记录,并处理TB级的作业,该数据湖已被众多团队采用,并为增强了数据分析能力以及开发和交付机器学习模型的能力。总体而言,该架构效果不错,并且我们相信数据基础架构的发展将使我们处于更好的位置,以适应当前和未来的需求。
我们的实施过程踩过不少坑,总结如下:
我们也在寻找改善数据基础架构的方法,并且已经开始制定下一步计划,包括:
原文:https://www.cnblogs.com/apachehudi/p/12528220.html