1.导入相应的库
2.打开页面:http://top.sogou.com/(搜狗热搜榜)
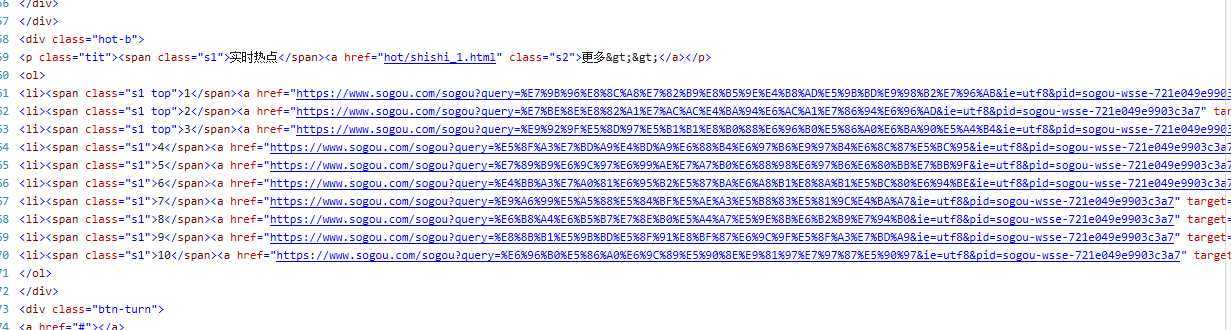
3.用F12查找页面代码,找到我们要的数据
4.class="hot-b",class="num"
5.利用代码得出我们想要的数据
#导入库 import requests import pandas as pd from bs4 import BeautifulSoup from pandas import DataFrame url="http://top.sogou.com/"#搜狗热搜榜 headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36‘}#伪装爬虫 r=requests.get(url)#请求网站 r.encoding=r.apparent_encoding#统一编码 html = r.text soup = BeautifulSoup(html,‘lxml‘)#使用工具 title=[] heat=[] for m in soup.find_all(class_="hot-b"): title.append(m.get_text().strip()) for n in soup.find_all(class_="num"): heat.append(n.get_text().strip()) print(data) a=pd.DataFrame(data,index=["标题","热度"]) print(a.T)

原文:https://www.cnblogs.com/jiang0606/p/12528178.html