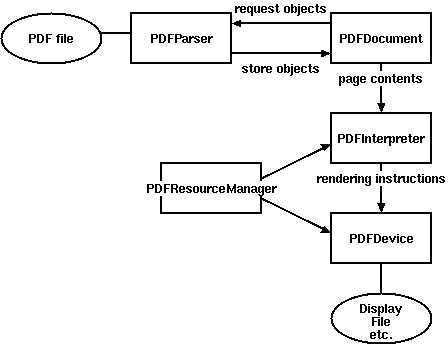
借助python第三方库pdfminer实现pdf转txt,原理如下图
from pdfminer.pdfparser import PDFParser from pdfminer.pdfdocument import PDFDocument from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.layout import LAParams from pdfminer.converter import PDFPageAggregator from pdfminer.pdfpage import PDFTextExtractionNotAllowed from pdfminer.pdfpage import PDFPage def pdf2txt(pdf,save_path): #创建一个pdf文档分析器 parser = PDFParser(pdf) #创建一个PDF文档 doc = PDFDocument(parser) if not doc.is_extractable: raise PDFTextExtractionNotAllowed else: #创建PDf资源管理器 resource = PDFResourceManager() #创建一个PDF参数分析器 laparams = LAParams() #创建聚合器,用于读取文档的对象 device = PDFPageAggregator(resource,laparams=laparams) #创建解释器,对文档编码,解释成Python能够识别的格式 interpreter = PDFPageInterpreter(resource,device) # 循环遍历列表,每次处理一页的内容 # doc.get_pages() 获取page列表 # 循环遍历列表,每次处理一个page的内容 for page in PDFPage.create_pages(doc): interpreter.process_page(page) # 接受该页面的LTPage对象 layout=device.get_result() for out in layout: #判断是否含有get_text()方法,获取我们想要的文字 if hasattr(out,"get_text"): print(out.get_text()) with open(‘%s‘ % (save_path),‘a‘) as f: f.write(out.get_text()+‘\n‘) #单个pdf转txt save_path = r‘C:\Users\17360\Desktop\test.txt‘ with open(r‘E:\PY基础\科研证明.pdf‘,‘rb‘) as f: pdf2txt(f, save_path)
有问题欢迎留言哦~
原文:https://www.cnblogs.com/lizitingxue/p/12531522.html