
不能分割,有些验证码有字母重合的情况。
整体识别:有四个目标值。每个位置有26种可能性(假设都是大写)输出:[None, 4*26]

处理数据
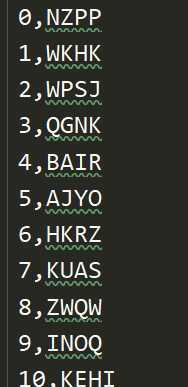
图片[20, 80, 3] 与标签文件一一对应。
不能用listdir直接列图片名,列出来的是乱序的。
思路:先读图片,再读标签文件,将标签文件的字母转换成数字,最后写入tfrecords
import tensorflow as tf import os os.environ[‘TF_CPP_MIN_LOG_LEVEL‘] = ‘2‘ FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string("tfrecords_dir", "./tfrecords/captcha.tfrecords", "验证码") tf.app.flags.DEFINE_string("captcha_dir", "./data/GenPics/", "验证码图片路径") tf.app.flags.DEFINE_string("letter", "ABCDEFGHIJKLMNOPQRSTUVWXYZ", "验证码字符的种类") def get_captcha_image(): """ 获取验证码图片数据 :return: image """ # 构造文件名 filename = [] for i in range(6000): string = str(i) + ".jpg" filename.append(string) # 构造路径+文件 file_list = [os.path.join(FLAGS.captcha_dir, file) for file in filename] # 构造文件队列 file_queue = tf.train.string_input_producer(file_list, shuffle=False) # 构造阅读器 reader = tf.WholeFileReader() # 读取图片数据内容 key, value = reader.read(file_queue) # 解码 image = tf.image.decode_jpeg(value) image.set_shape([20, 80, 3]) # 批处理 image_batch = tf.train.batch([image],batch_size=6000, num_threads=1, capacity=6000) return image_batch def get_captcha_label(): """ 读取验证码图片标签数据 :return: label """ # 不指定shuffle就会乱序 file_queue = tf.train.string_input_producer(["./data/GenPics/labels.csv"], shuffle=False) reader = tf.TextLineReader() key, value = reader.read(file_queue) # 解码 records = [[1], ["None"]] # 一列是int,一列是字符串 number, label = tf.decode_csv(value, record_defaults=records) # 批处理 只需要label label_batch = tf.train.batch([label], batch_size=6000, num_threads=1, capacity=6000) return label_batch def dealwithlabel(label_str): # 构建字符索引 {0:‘A‘, 1:‘B‘......} # 把letter转化成列表,然后用enumerate加上序列,然后转化成字典 num_letter = dict(enumerate(list(FLAGS.letter))) # 键值对反转 {‘A‘:0, ‘B‘:1......} # zip打包成元组,再把元组列表转化成字典 letter_num = dict(zip(num_letter.values(), num_letter.keys())) print(letter_num) # 构建标签的列表 label_array = [] # 对标签数据进行处理 for string in label_str: # [[b"NZBF"]...] num_list = [] # 修改编码,b‘BVCF‘到字符串,并且循环找到每张验证码的字符对应的数字标记 for letter in string.decode(‘utf-8‘): # 每一个字母,在字典中找出对应的数字 num_list.append(letter_num[letter]) # 存到标签列表中 [[13,25,17,2],[14,6,18,18]] label_array.append(num_list) print(label_array) # 把列表转换成tensor类型,二维[[13,25,17,2],[14,6,18,18]] label = tf.constant(label_array) return label def write_to_tfrecords(image_batch, label_batch): """ 将图片内容和标签写入到tfrecords文件当中 :param image_batch:特征值 :param label_batch:标签值 :return: None """ # 转换类型 label_batch = tf.cast(label_batch, tf.uint8) # 建立tfrecords存储器 writer = tf.python_io.TFRecordWriter(FLAGS.tfrecords_dir) # 循环将每一个图片上的数据构造example协议块 for i in range(6000): # 取出第i个图片数据,转换相应类型,图片的特征值要转换成字符串形式 image_string = image_batch[i].eval().tostring() # 取出第i个标签值,多个目标值不能用int存,所以也要转成string label_string = label_batch[i].eval().tostring() # 构造协议块 example = tf.train.Example(features=tf.train.Features(feature={ "image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_string])), "label": tf.train.Feature(bytes_list=tf.train.BytesList(value=[label_string])) })) writer.write(example.SerializeToString()) # 关闭文件 writer.close() return None if __name__ == ‘__main__‘: # 获取验证码文件当中的图片 image_batch = get_captcha_image() # 获取验证码文件当中的标签数据 label = get_captcha_label() print(image_batch, label) with tf.Session() as sess: coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) label_str = sess.run(label) # b‘NZPP‘ b‘WKHK‘ print(label_str) # 处理字符串标签到数字张量 label_batch = dealwithlabel(label_str) # 将图片数据和内容写入到tfrecords文件当中 write_to_tfrecords(image_batch, label_batch) coord.request_stop() coord.join(threads)
识别验证码
1、从tfrecords读取 每张图片有image, label:[100, 20, 80, 3] [100, 4]([[23,16,18,23],[4,17,9,10]])
2、建立模型,直接读取数据输入模型当中(全连接层)
x = [100, 20*80*3] w=[20*80*3, 100] y_predict=[100, 4*26] bias=[4*26]
3、建立损失:softmax,交叉熵损失
目标值要转成one-hot编码 [[0,0,0,1,0,...],[0,0,1,0,0,0,...],[0,0,0,...,1],[0,0,0,0,0,0,1,...]]
tf.one_hot(y_true, depth=26, axis=2, on_value=1.0)
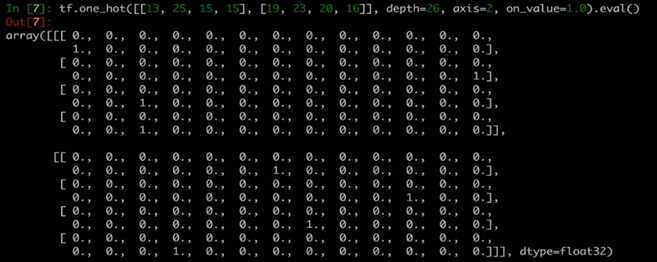
[100, 4] ---> [100, 4, 26] ----> [100, 4*26] 然后与预测值进行交叉熵损失计算
1*log(0.23)+ 1*log() + 1*log() + 1*log() = -损失值
4、梯度下降优化
计算准确率:每个样本要比较四次tf.argmax()位置是否相同,有一个不同就记为0
tf.argmax(预测值,2)
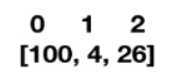
二、
原文:https://www.cnblogs.com/ysysyzz/p/12521477.html