1.打开网站:http://top.sogou.com/game/quanbu_1.html(搜狗热门游戏榜单):
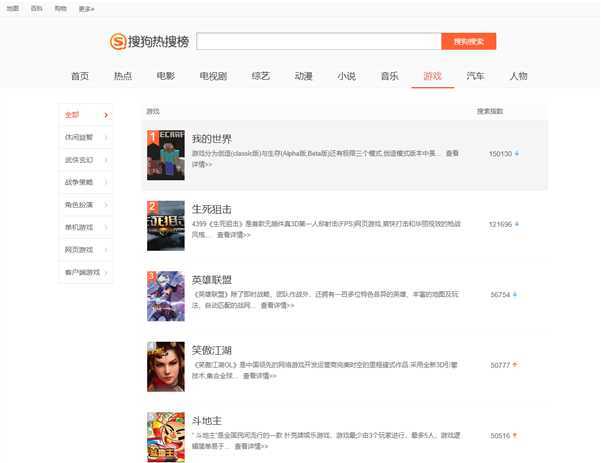
2.打开网页源代码,爬取需要内容:
3.导入相应数据库,利用代码获取信息。
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = ‘http://top.sogou.com/game/quanbu_1.html‘
headers = {‘User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362‘}#伪装爬虫
r=requests.get(url)
r.encoding=r.apparent_encoding
t=r.text
soup=BeautifulSoup(t,‘lxml‘)
title=[]
index=[]
for m in soup.find_all(class_="pub-list renwu"):
title.append(m.get_text().strip())
for n in soup.find_all(class_="num"):
heat.append(n.get_text().strip())
data=[title,index]
print(data)
s=pd.DataFrame(data,index=["标题","搜索指数"])
print(s.T)
4.获得数据

原文:https://www.cnblogs.com/somde/p/12540041.html