??最近在学习爬虫来爬取网站内容,本篇就是使用Python的requests库来爬取百度贴吧中小说吧里的一篇小说《黑道编年史》,并将其保存到本地文件中。百度贴吧的内容都是以“楼层发言”的形式呈现的,其中,只有楼主的发言的内容才是有用的小说内容,其余的都是无用的废话,好在百度提供了“只看楼主”的选项,可以只呈现楼主发言。我们很自安然想到使用requests库爬取网页内容,然后把楼主的发言保存到本地。
??开整!
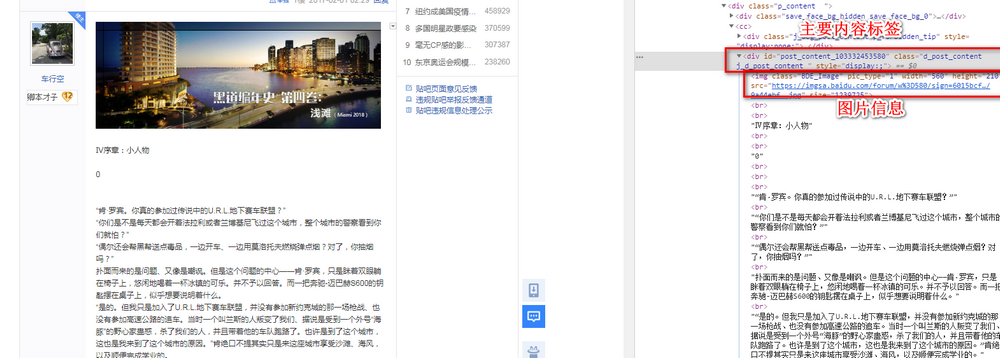
??我们先观察网页内容,搜索框中“https://tieba.baidu.com/p/4961759818?see_lz=1&pn=1”,#see_lz=1#意思就是‘只看楼主’,然后,“pn=1”就是page_number为第一页,由此类推,第二页即为pn=2,这里我们很容易想到构建一个列表来存储每一页的url(本案例只有两页,可以手输,但是涉及到很多页的时候手输就不现实了),那么一共有多少页面呢,从下面的截图中可以看到显示总页数的位置以及相应的html中的标签,由此,每一页的url我们已经获取到。

??然后就每一页的楼主的发言信息。检查元素楼主每层的信息,可以发现,楼主的内容都储存在一个<div>标签里面,属性为"d_post_content j_d_post_content ",根据这些信息我们使用“美丽汤”库很容易就可以获取到楼主的发言信息。但是这里有一个问题:<div>标签里面不只有正文部分,还有一些图片信息,并且图片的内容的数量是不一定的,在这里我网上搜了一个很简单很方便的一个小方法,[s.extract() for s in soup(‘img‘)]这一小段代码可以实现删除某个标签内的特定子标签。
??然后剩下的就是往本地文件里写入的一些代码了,网上找的。下面就是我最终的代码,比较粗糙,诸位看官请赐教:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import random
import sys
class get_novel_tieba(object):
#定义类本身,包括小说的网址,每页网址,requests库中的header
def __init__(self):
self.url = "https://tieba.baidu.com/p/4961759818?see_lz=1"
self.url_page = []
self.headers = [{'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36'},
{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'},
{'User-Agent':'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'},
{'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'},
{'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)'}]
self.title = ""
self.content = []
#定义函数,根据小说网址爬取每一页的的url
def get_pageurl(self):
req = requests.get(url=self.url, headers=self.headers[random.randint(0,4)])
soup = BeautifulSoup(req.text)
#文章题目
title = soup.find("h3")
self.title = title.text
#每页的url
toalpage = soup.find("span", class_="red", style = '')
total_page_number= int(str(toalpage.text))
for i in range(total_page_number):
#设置只看楼主,检查元素可以看到每页的url为原网址+”see_lz=1&pn=”+页码
self.url_page.append("https://tieba.baidu.com/p/4961759818?see_lz=1&pn="+str(i+1))
#定义函数,根据每个页面的url爬取每页内容
def get_content(self, url):
req = requests.get(url=url, headers=self.headers[random.randint(0,4)])
soup = BeautifulSoup(req.text)
#除掉图片标签项
[s.extract() for s in soup('img')]
text = soup.find_all('div',class_='d_post_content j_d_post_content ')
#得到的结果是当前页中每层楼中楼主的消息,然后遍历
for i in range(len(text)):
#每一层楼中也是每一段的列表,然后Tag类型转换为字符串
for sentence in text[i]:
sentence = str(sentence).replace('<br/>', '') #标签标识
self.content.append(sentence)
#定义写进文件函数
def writer(self, path):
with open(path,"w",encoding ='utf-8') as f:
f.writelines("%s\n" % ss for ss in self.content)
#主函数
if __name__ == "__main__":
gn = get_novel_tieba()
gn.get_pageurl() # 获取文章题目,及每页url
print("开始下载。。。")
for i in range(len(gn.url_page)):
gn.get_content(gn.url_page[i]) # 获取文章内容
gn.writer("%s.txt" % gn.title)
sys.stdout.write("已下载%d页,共%d页。\n" % (i+1, len(gn.url_page)))
sys.stdout.flush()
print("下载完成。")看看结果,小说都被完整的爬取下来了,当然不是很美观,空格太多,看着不是很舒服,另外段前再有缩进就更好了,这些,代码应该都是 能实现的:

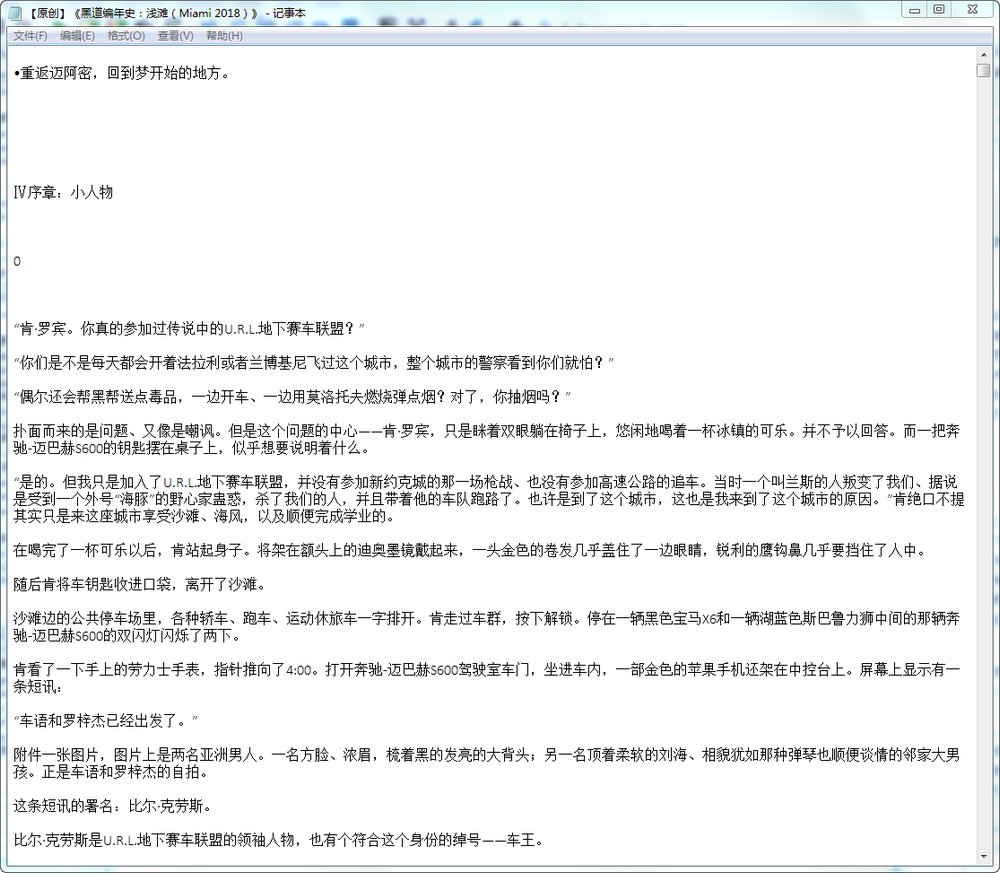
为了使这个段代码更有适用性,我想了下应该还是好几个可以提升的地方的:

在本篇中,楼主并没有灌水,但是在其他的小说吧中,相当一部分楼主为了博关注,灌了水,如何准确的筛选灌水和正文部分,也是一个难点。我想了一个可能不太十分准确的方法,根据字数,正文一般比较多,而灌水往往字数比较少。(当然也有例外)
代码优化空间很大,需要学习的地方很多。我原本以为爬虫很简单,随便看几个案例就学会了,现在看来这远远不够,还要系统的学习下,requests库,BeautifulSoup库,urllib库内容还是很丰富的。
我还找到另外一个博友爬取小说的一个教程《Python实战项目网络爬虫 之 爬取小说吧小说正文》,不过他没有用BeautifulSoup库,用的正则表达式,可以相互借鉴下。
原文:https://www.cnblogs.com/shuai3290/p/12543704.html