分类变量类似于枚举,拥有特定数量的值类型。
比如:红白蓝以颜色为分类的元素,大中小以形状为分类的元素。
而这类值基本是给出一个big或者red等英文字符串做为数据,这时候的话,我们就得去进行一些操作,把它们弄成可以去处理的映射值或是直接给删掉。
首先来预处理

import pandas as pd from sklearn.model_selection import train_test_split # Read the data X = pd.read_csv(‘../input/train.csv‘, index_col=‘Id‘) X_test = pd.read_csv(‘../input/test.csv‘, index_col=‘Id‘) # Remove rows with missing target, separate target from predictors X.dropna(axis=0, subset=[‘SalePrice‘], inplace=True)#Because our dependent variable is SalePrice,we need to drop some missing targets y = X.SalePrice#Select dependent variable X.drop([‘SalePrice‘], axis=1, inplace=True) # To keep things simple, we‘ll drop columns with missing values cols_with_missing = [col for col in X.columns if X[col].isnull().any()] X.drop(cols_with_missing, axis=1, inplace=True) X_test.drop(cols_with_missing, axis=1, inplace=True) #Now we have the dataframe without missing values # Break off validation set from training data X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
1) 删除分类变量
drop_X_train = X_train.select_dtypes(exclude=[‘object‘]) drop_X_valid = X_valid.select_dtypes(exclude=[‘object‘]) #exclude=[‘object‘] means categorical data
然后可以check一波它们的mean_absolute_error值
2) 标签编码
即构建映射值。
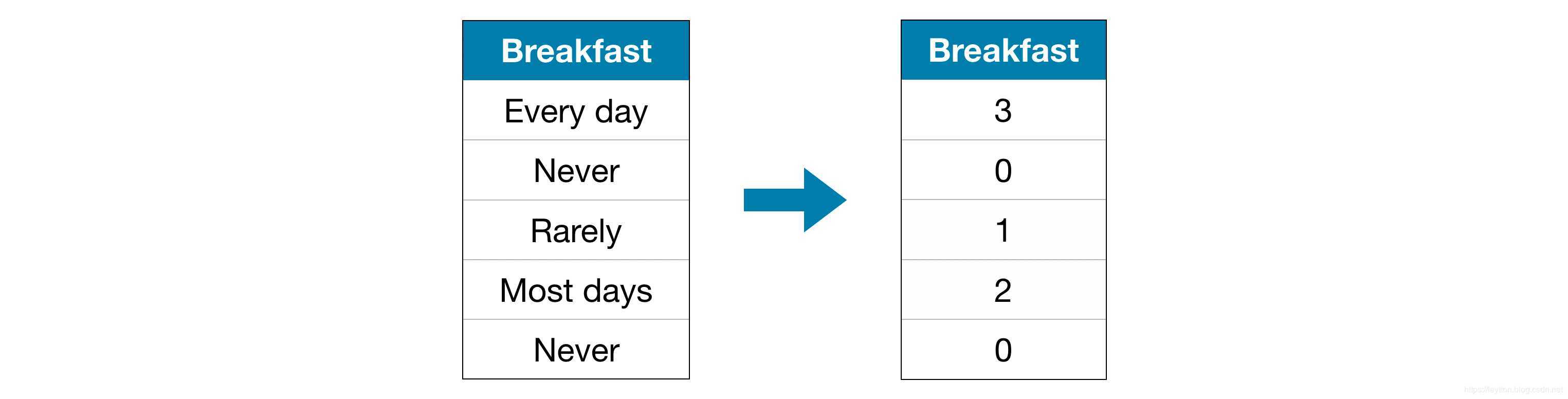
①但是这里尤其要注意了,我们一开始是分了train和valid两个样本,如果直接简单暴力的去把train里面的分类变量都直接标签的话,就会编译错误,因为你说不准valid样本里面会出现一些没有在train上面出现过的分类变量。
②在本例中,这个假设是有意义的,因为对类别有个唯一的排名。 并不是所有的分类变量在值中都有一个明确的顺序,但是我们将那些有顺序的变量称为有序变量。对于基于树的模型(如决策树和随机森林),有序变量的标签编码可能效果不错。
# All categorical columns object_cols = [col for col in X_train.columns if X_train[col].dtype == "object"] # Columns that can be safely label encoded good_label_cols = [col for col in object_cols if set(X_train[col]) == set(X_valid[col])] #See that we must ensure X_train dataset have the same label encoded as X_valid # Problematic columns that will be dropped from the dataset bad_label_cols = list(set(object_cols)-set(good_label_cols))
from sklearn.preprocessing import LabelEncoder # Drop categorical columns that will not be encoded label_X_train = X_train.drop(bad_label_cols, axis=1) label_X_valid = X_valid.drop(bad_label_cols, axis=1) # Apply label encoder label_encoder=LabelEncoder() for col in good_label_cols: label_X_train[col]=label_encoder.fit_transform(label_X_train[col]) label_X_valid[col]=label_encoder.transform(label_X_valid[col])
3) One-Hot 编码
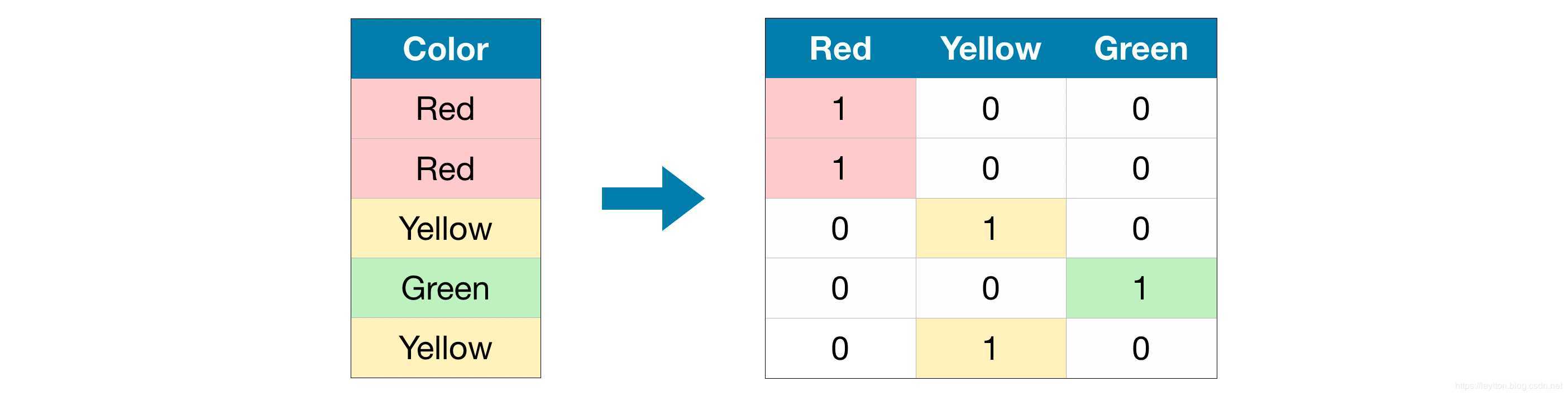
①可以看到我们要添加许多列在数据上,有多少类别我们就添加多少列,所以如果类别很多,就意味着我们的列表要拓展得很大,因此,我们通常只对一个基数相对较低的列进行热编码。然后,可以从数据集中删除高基数列,也可以使用标签编码。一般情况下,选类别为10做为删除标准
②与标签编码不同,one-hot编码不假定类别的顺序。因此,如果在分类数据中没有明确的顺序(例如,“红色”既不比“黄色”多也不比“黄色”少),这种方法可能会特别有效。我们把没有内在排序的分类变量称为名义变量。
# Columns that will be one-hot encoded low_cardinality_cols = [col for col in object_cols if X_train[col].nunique() < 10] # Columns that will be dropped from the dataset high_cardinality_cols = list(set(object_cols)-set(low_cardinality_cols))
from sklearn.preprocessing import OneHotEncoder # Apply one-hot encoder to each column with categorical data OH_encoder = OneHotEncoder(handle_unknown=‘ignore‘, sparse=False) OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[low_cardinality_cols])) OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[low_cardinality_cols])) # One-hot encoding removed index; put it back OH_cols_train.index = X_train.index OH_cols_valid.index = X_valid.index # Remove categorical columns (will replace with one-hot encoding) num_X_train = X_train.drop(object_cols, axis=1) num_X_valid = X_valid.drop(object_cols, axis=1) # Add one-hot encoded columns to numerical features OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1) OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
原文:https://www.cnblogs.com/Y-Knightqin/p/12556156.html
