并发编程就是同时执行多个任务
多任务就是计算机同时进行多个任务
首先下面的程序就是一个串行的唱歌跳舞,也就是先sing完在dance,并不是同时执行的
# code01_模拟唱歌跳舞.py
"""
time.sleep(secs)
在给定的秒数内挂起调用线程的执行。
参数可以是浮点数以指示更精确的睡眠时间。
"""
from time import sleep
def sing():
for i in range(3):
print("正在唱歌.... %d" % i)
sleep(1) # 输出一次休息一秒
def dance():
for i in range(3):
print("正在跳舞.... %d" % i)
sleep(1) # 输出一次休息一秒
if __name__ == "__main__":
sing()
dance()
"""
输出结果: (串行的,不是并行的)
正在唱歌.... 0
正在唱歌.... 1
正在唱歌.... 2
正在跳舞.... 0
正在跳舞.... 1
正在跳舞.... 2
"""
1. 真正多任务处理只能发生在多核CPU上(并行)
(1) 现在的任务数量是远多于CPU的核心数量的,所以操作系统会自动把很多任务轮流调度到每个核心上执行.
2. 单核CPU处理多任务的方式(并发)
(1) 操作系统让各个任务交替执行,每次让CPU执行0.01秒
(2) 由于CPU的速度太快,所以我们感觉就像在同时进行多任务一样
multiprocessing
subprocess
1. 代码编写完没有运行就称为程序,正在运行的代码就是进程.
2. 在Python3中,对多进程支持的是 multiprocessing模块和subprocess模块.
3. multiprocessing模块为在子进程中运行任务,通讯和共享数据,以及执行各种形式的同步提供支持
进程创建-Process
multiprocessing.Process()
1. Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情。
2. 借助这个包,可以轻松完成从单进程到并发执行的转换。
3. multiprocessing支持子进程、通信和共享数据。
4. Process([group [, target [, name [, args [, kwargs]]]]])
(1) group必须为None,目前未实现,是为了以后扩展功能保留的预留参数
(2) target表示子进程的功能函数
(3) name为别名
(4) args表示调用对象的位置参数元组
(5) kwargs表示调用对象的字典
# code02_创建子进程并执行.py
"""
multiprocessing是一个和threading模块类似,提供API,生成进程的模块。
在multiprocessing中,通过创建Process对象,然后调用其 start() 方法来加载进程.
"""
from multiprocessing import Process
from time import sleep
def sing():
for i in range(3):
print("正在唱歌.... %d" % i)
sleep(1) # 输出一次休息一秒
if __name__ == "__main__":
# 这个main函数就是主进程
print("主进程执行")
# 使用Process创建一个子进程 => 使用target来接收一个要执行的函数
p1 = Process(target=sing())
# 然后调用Process.start() 来加载子进程
p1.start()
# code03_创建子进程并传递参数.py
"""
如果是要创建子进程的函数带有参数
就需要用到 args kwargs
"""
from time import sleep
from multiprocessing import Process
def run_proc(name, age, **kwargs):
print("子进程开始执行")
for i in range(5):
print("子进程运行中,参数 name:{},age:{}".format(name, age))
print("字典参数: {}".format(kwargs))
sleep(0.5)
if __name__ == "__main__":
print("主程序开始运行")
# 如果创建的子进程的函数有参数的话 => 使用 args kwargs 来传递
p1 = Process(target=run_proc,args=("张三",23),kwargs=dict(job="coder",hobby="basketball"))
p1.start()
Process的实例方法
注意: Window系统使用multiprocessing模块时,必须采用 if name == "main" 的方式运行程序

# code05_join使用方法02.py
# 调用join方法: 主进程等会带调用join的子进程结束(其他子进程不会等)
from multiprocessing import Process
from time import sleep
import os
def sing():
for i in range(3):
print("正在唱歌.... %d 进程号: %s" % (i, os.getpid()))
sleep(1) # 输出一次休息一秒
def dance():
for i in range(3):
print("正在跳舞.... %d 进程号: %s" % (i, os.getpid()))
sleep(1) # 输出一次休息一秒
if __name__ == "__main__":
# 好像演示的 p.start() p.join()
print("主程序正在运行 进程号: {}".format(os.getpid()))
p1 = Process(target=sing)
p1.start()
p2 = Process(target=dance)
p2.start()
# 这里演示了加入timeout参数的情况
p1.join(0.1) # 先让这个进程1S
p2.join(0.1)
print("主程序结束 进程号: {}".format(os.getpid()))

Process实例属性
Process有两个实用属性
namepid
1. Process.name =>进程的名称
2. Process.pid => 进程的整数进程ID
# code06_Process两个属性的使用.py
from multiprocessing import Process
import time
import os
def my_process(n):
print("===子进程{}开始===".format(n))
print("这是子进程 父进程:{} 本进程:{}".format(os.getppid(), os.getpid()))
print("===子进程{}结束===".format(n))
time.sleep(2)
if __name__ == "__main__":
print("+++主进程开始+++")
print("这是主进程 父进程:{} 本进程:{}".format(os.getppid(), os.getpid()))
p1 = Process(target=my_process, args=(1,)) # 把要执行的函数给target,初始化一个进程
print("进程是否还存活:{}".format(p1.is_alive()))
p1.start() # 开启进程
print("进程是否还存活:{}".format(p1.is_alive()))
p1.join() # 让主进程等待p1运行结束
print("进程是否还存活:{}".format(p1.is_alive()))
print("进程的属性 => name:{} pid:{}".format(p1.name, p1.pid))
print("=================")
p2 = Process(target=my_process, args=(2,)) # 把要执行的函数给target,初始化一个进程
print("进程是否还存活:{}".format(p2.is_alive()))
p2.start() # 开启进程
print("进程是否还存活:{}".format(p2.is_alive()))
p2.join() # 让主进程等待p1运行结束
print("进程是否还存活:{}".format(p2.is_alive()))
print("进程的属性 => name:{} pid:{}".format(p2.name, p2.pid))
print("+++主进程结束+++")
进程创建-Process子类
主要是继承
Process重写run()
理解好传给target的函数和重写的run()
1. 创建进程的方式还可以使用类的方式.
2. 可以自定义一个类,继承Process类,每次实例化这个类,就等同于实例化一个进程对象
3. 继承Process的类,重写run()方法创建进程
# code07_使用继承方式创建进程
"""
创建进程的方式还可以使用类的方式,可以自定义一个类,继承Process类,
每次实例化这个类的时候,就等同于实例化一个进程对象
继承Process的类,重写run()方法创建进程
"""
import time
from multiprocessing import Process
import os
class ClockProcess(Process):
"""
理解一下 => 其实传入的target的函数就是来子类中重写run()
"""
def __init__(self, interval):
Process.__init__(self) # 父类构造方法
self.interval = interval
# 重写run()方法
def run(self):
print("子进程开始执行时间: {}".format(time.ctime()))
print("父进程:{} 本进程:{}".format(os.getppid(), os.getpid()))
time.sleep(self.interval)
print("子进程结束执行时间: {}".format(time.ctime()))
if __name__ == "__main__":
# 创建进程
p = ClockProcess(2)
p.start()
p.join()
print(p.pid, p.name, p.is_alive())
进程池
from multiprocessing import Pool
进程池在内部会维护一个进程序列
1. 当操作对象数目不大时,可以直接利用multiprocessing中的Process动态创建多个进程.
(1) 十几个还好,但是如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐
(2) 如果要创建数量很多的进程 => 进程池
2. Pool可以提供指定数量的进程,供用户调用
(1) 当有新的请求提交到pool中时,如果池子没有满,那么就会创建一个新的进程来执行该请求
(2) 但如果池中的进程数已经达到规定最大值,那么该请求就会等待,知道池中有进程结束,才会创建新的进程
3. Pool的语法
Pool(processes=None, initializer=None, initargs=(),maxtasksperchild=None, context=None)
(1) processes: 表示进程的数量. 若processes参数设为None,则会使用os.cpu_count()返回的数量.
(2) maxtasksperchild: 进程退出之前可以完成的任务数量,完成之后使用新的进程替换原进程,以释放闲置资源
(3) context: 用于设置工作进程启动时的上下文
(4) initargs: 是要传递给initializer的参数元祖。
(5) initializer: 默认为None
4. Pool类的常见方法
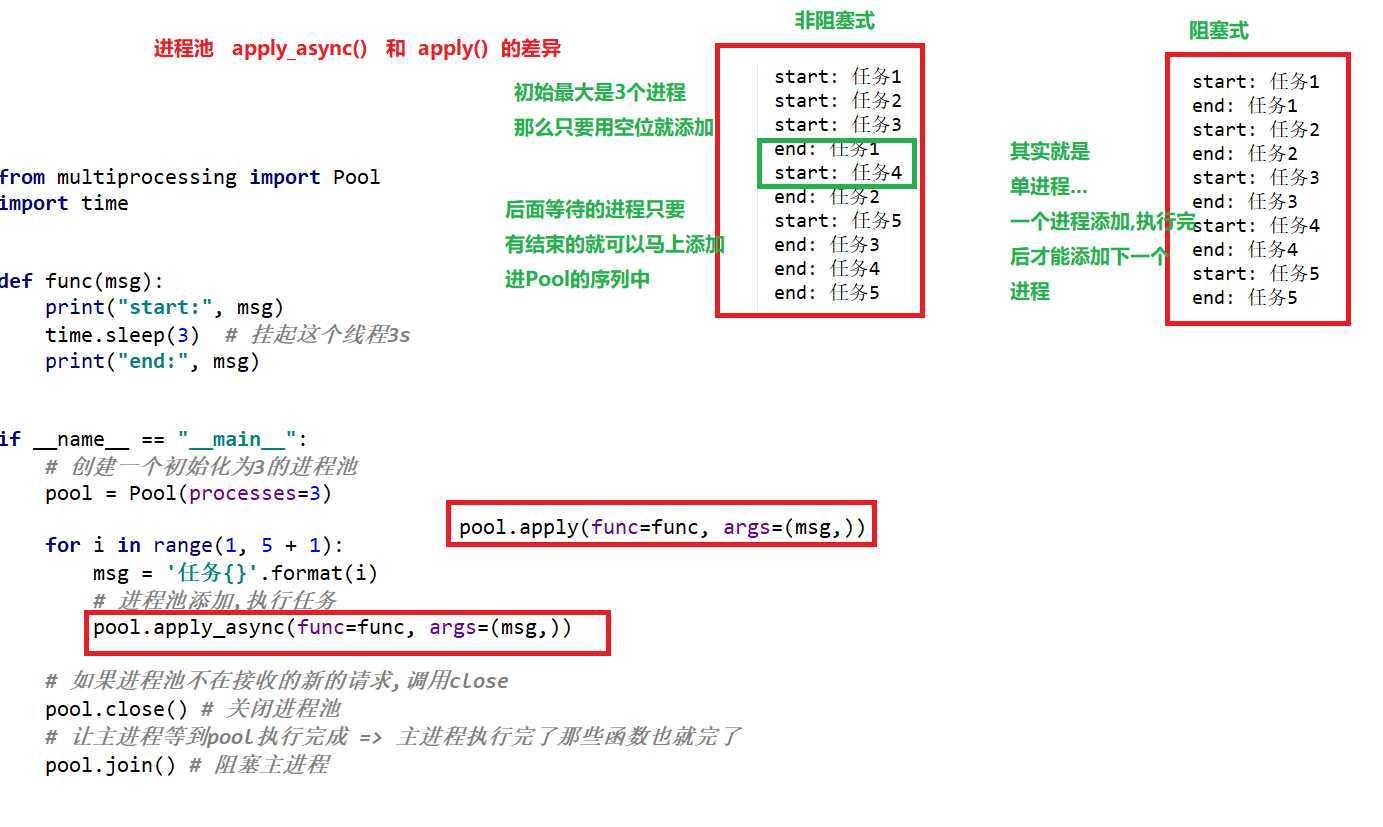
(1) apply_async() 非阻塞地给进程池添加任务
(2) apply() 阻塞地给进程池添加任务
(3) close() 关闭进程池,阻止更多的任务提交到进程,待所有任务执行完成后进程退出
(4) terminate() 结束进程,不再处理未完成的任务
(5) 等待进程的退出,必须在close()和terminate()之后使用
进程池非阻塞式添加任务
Pool.apply_async()
非阻塞式的添加任务
apply_async(self, func, args=(), kwds={}, callback=None,error_callback=None)
(1) func: 表示要执行的函数
(2) args,kwds: 表示要给func函数的参数
(3) callback: 表示回调函数
(4) error_callback: 表示程序执行失败后会调用的回调函数
# code08_进程池非阻塞状态的使用
"""
Pool(processes=None, initializer=None, initargs=(),maxtasksperchild=None, context=None)
(1) processes: 表示进程的数量. 若processes参数设为None,则会使用os.cpu_count()返回的数量.
(2) maxtasksperchild: 进程退出之前可以完成的任务数量,完成之后使用新的进程替换原进程,以释放闲置资源
(3) context: 用于设置工作进程启动时的上下文
(4) initargs: 是要传递给initializer的参数元祖。
(5) initializer: 默认为None
"""
‘‘‘
非阻塞式的添加任务
apply_async(self, func, args=(), kwds={}, callback=None,error_callback=None)
(1) func: 表示要执行的函数
(2) args,kwds: 表示要给func函数的参数
(3) callback: 表示回调函数
(4) error_callback: 表示程序执行失败后会调用的回调函数
‘‘‘
from multiprocessing import Pool
import time
def func(msg):
print("start:", msg)
time.sleep(3) # 挂起这个线程3s
print("end:", msg)
if __name__ == "__main__":
# 创建一个初始化为3的进程池
pool = Pool(processes=3)
for i in range(1, 5 + 1):
msg = ‘任务{}‘.format(i)
# 进程池添加,执行任务
pool.apply_async(func=func, args=(msg,))
# 如果进程池不在接收的新的请求,调用close
pool.close() # 关闭进程池
# 让主进程等到pool执行完成 => 主进程执行完了那些函数也就完了
pool.join() # 阻塞主进程
进程池阻塞式添加任务
Pool.apply()
用的比较少,因为是单进程
# code09_进程池阻塞状态的使用
"""
Pool(processes=None, initializer=None, initargs=(),maxtasksperchild=None, context=None)
(1) processes: 表示进程的数量. 若processes参数设为None,则会使用os.cpu_count()返回的数量.
(2) maxtasksperchild: 进程退出之前可以完成的任务数量,完成之后使用新的进程替换原进程,以释放闲置资源
(3) context: 用于设置工作进程启动时的上下文
(4) initargs: 是要传递给initializer的参数元祖。
(5) initializer: 默认为None
"""
‘‘‘
阻塞式的添加任务
apply(self, func, args=(), kwds={})
(1) func: 表示要执行的函数
(2) args,kwds: 表示要给func函数的参数
‘‘‘
from multiprocessing import Pool
import time
def func(msg):
print("start:", msg)
time.sleep(3)
print("end:", msg)
if __name__ == "__main__":
pool = Pool(processes=3)
for i in range(1, 5 + 1):
msg = "任务{}".format(i)
# 阻塞地添加,执行进程
pool.apply(func=func, args=(msg,))
pool.close() # 关闭进程池
pool.join() # 阻塞主进程
进程间通信
全局变量在多个进程之间不共享,进程之间的数据是独立的
每个进程中所拥有的数据(包括全局变量)都是独有的,无法与其他进程共享.
# code10_多个进程之间数据不共享
from multiprocessing import Process
num = 10 # 全局变量
def work1():
# 要修改全局变量要先使用global声明
global num
num += 5
print("子进程1运行后: num的值:", num)
def work2():
# 要修改全局变量要先使用global声明
global num
num += 10
print("子进程2运行后: num的值:", num)
if __name__ == "__main__":
print("主程序开始运行")
# 创建子进程
p1 = Process(target=work1)
p2 = Process(target=work2)
# 启动子进程(同时启动,再join()就相当于是异步了)
p1.start()
p2.start()
p1.join()
p2.join()
print("主程序结束运行")
print("主进程运行后: num的值:", num)

进程间通信Queue
from multiprocessing import Queue=> 适用于Process
from multiprocessing import Pool,Manage=> 适用于Pool
1. Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递.
2. Queue.put()用于插入数据到队列中,put()还有两个可选参数: blocked和timeout
(1) 如果block参数是布尔值,表示是否阻塞队列
(2) timeout参数表示时长,默认为None
(3) 如果blocked为True(默认值),并且timeout为正值(没给定就一直等待),该方法会阻塞timeout指定的时间,直到队列有剩余的空间.如果超时,会排除Queue.full异常.
(4) 如果blocked为False,但该队列已满,会立即排除Queue.full异常.
4. Queue.get()可以从队列中读取并删除一个元素.同样,get方法有两个可选参数: blocked和timeout
(1) 如果blocked为True(默认值),并且tiemout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常.
(2) 如果blocked为False,一种情况是如果Queue有一个值可用,就立刻返回该值;如果队列为空,直接抛出Queue.Empty异常.
5. 如果使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue()来完成进程间的通信,而不是multiprocessing.Queue()
(1) 否则会抛出如下异常 => RuntimeError: Queue objects should only be shared between processes through inheritance
# code11_多进程之间的通信.py
from multiprocessing import Process, Queue
import time
# 定义写入的方法
def write(q):
a = [x for x in "abcdef"]
for x in a:
print("开始写入的值:{}".format(x))
q.put(x) # 默认是要阻塞队列
time.sleep(1)
def read(q):
while not q.empty():
print("读取到的值:{}".format(q.get()))
time.sleep(1)
if __name__ == "__main__":
# 创建进程之间的队列(这个队列是在主进程的)
q = Queue() # 没有指定长度默认就是无限长
# 创建两个进程,一个读,一个写
# 注意: 现在简单演示就一个进程一个进程来执行
pw = Process(target=write, args=(q,))
pw.start()
pw.join()
pr = Process(target=read, args=(q,))
pr.start()
pr.join()
# code12_进程池多进程之间的通信.py
from multiprocessing import Manager, Pool
import time
def write(q):
a = [x for x in "abcdef"]
for x in a:
print("开始写入的值:{}".format(x))
q.put(x)
time.sleep(1)
def read(q):
while not q.empty():
print("读取到的值:{}".format(q.get()))
time.sleep(1)
if __name__ == "__main__":
# 类里面的类
q = Manager().Queue()
# 创建进程池
pool = Pool(processes=3)
# 使用阻塞方式创建进程,先写入在读取
pool.apply(func=write, args=(q,))
pool.apply(func=read,args=(q,))
pool.close()
pool.join()
程序启动时,系统创建一个进程的同时会同时创建一个线程(这就是主进程和主线程)
1. 线程也是实现多任务的一种方式.
2. 一个进程中,也经常需要同时做多件事,就需要同时运行多个"子任务",这些任务就是线程.
(1) 比如打开浏览器(浏览器这个程序就是一个进程),但是开一个窗口,两个窗口,这些在一个进程下的子任务有同时进行的就是线程
(2) 百度网盘可以同时下载多个任务也是也多线程,可以同时下载和上传也是多线程
3. 一个进程可以拥有多个并行(注意是并行不是并发),其中每一个线程,共享当前进程的资源
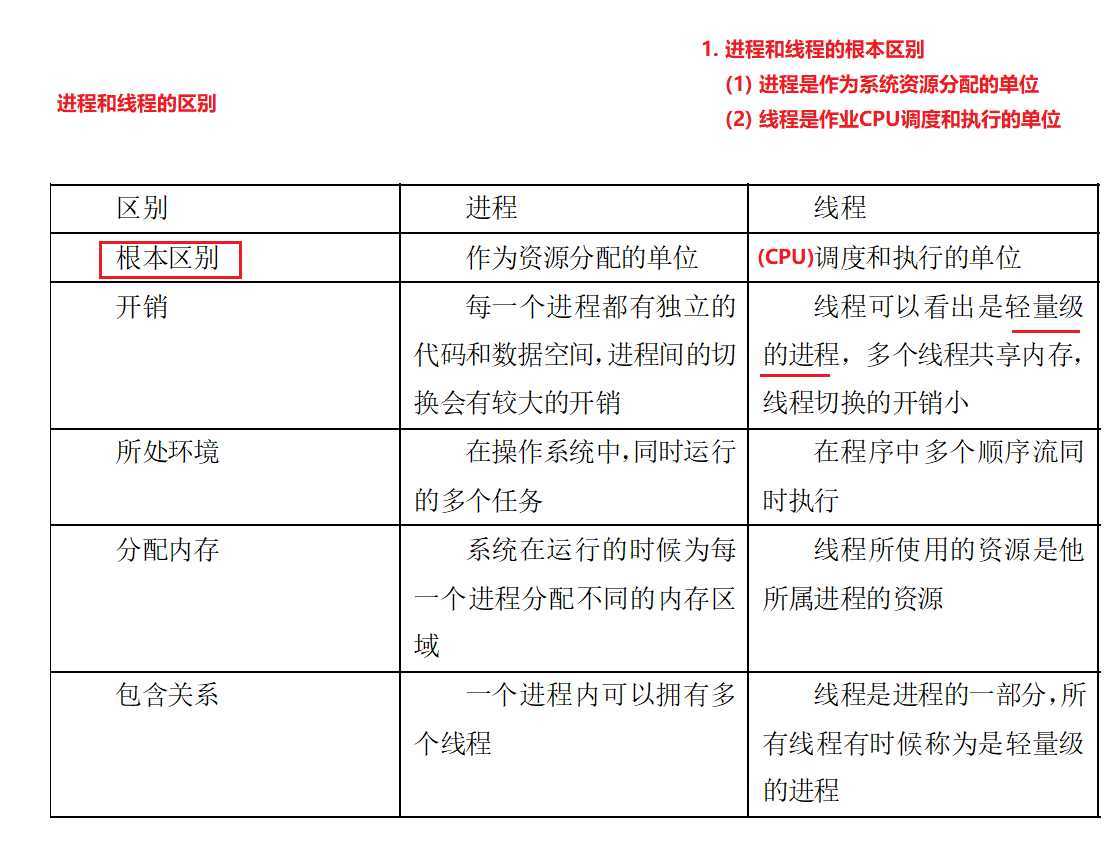
4. 进程和线程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护,而进程正相反。
1. 在Python程序中,可以通过“_thread”和threading(推荐使用)这两个模块来处理线程。
2. 在Python3中,thread模块已经废弃。可以使用threading模块代替。
3. 所以,在Python3中不能再使用thread模块,但是为了兼容Python3以前的程序,在Python3中将thread模块重命名为“_thread”。
_thread模块
1. 当使用thread模块来处理线程时,可以调用里面的函数start_new_thread()来生成一个新的线程
2. 语法格式如下: _thread.start_new_thread ( function, args[, kwargs] )
(1) function: 线程函数
(2) args,kwargs: 要传递过去的参数
import _thread # 这是重命名的模块(为了兼容thread)
import time
def fun1(delay):
print("start: {}".format("fun1"))
time.sleep(delay)
print("end: {}".format("fun1"))
def fun2(delay):
print("start: {}".format("fun2"))
time.sleep(delay)
print("end: {}".format("fun2"))
if __name__ == "__main__":
print("开始运行")
# 创建线程
_thread.start_new_thread(fun1, (4,))
_thread.start_new_thread(fun2, (2,))
# 主线程要休眠一段时间 => 不然主线程结束没法运行子线程
time.sleep(7)
threating模块
1. 在Python3程序中,对多线程支持最好的是threading模块,使用这个模块,可以灵活地创建多线程程序,并且可以在多线程之间进行同步和通信。
2. 在Python3程序中,可以通过如下两种方式来创建线程:
(1) 通过threading.Thread直接在线程中运行函数
(2) 通过继承类threading.Thread来创建线程
3. 在Python中使用threading.Thread的基本语法格式如下所示: Thread(group=None, target=None, name=None, args=(), kwargs={})
(1) name参数表示线程的名称,默认由 "Threat-N"形式组成
(2) 其他参数与创建Process对象一致,不再赘述
4. 一样有属性 name,方法 start() run() join()
# code14_Threat创建多线程.py
from threading import Thread
import time
def fun1(delay, thread_name):
print("start: {}".format(thread_name))
time.sleep(delay)
print("end: {}".format(thread_name))
def fun2(delay, thread_name):
print("start: {}".format(thread_name))
time.sleep(delay)
print("end: {}".format(thread_name))
if __name__ == "__main__":
print("程序开始")
# 创建线程
t1 = Thread(target=fun1, args=(2, "Thread-1"))
t2 = Thread(target=fun2, args=(4, "Thread-2"))
# 启动线程
t1.start()
t2.start()
# 阻塞主线程
t1.join()
t2.join()
print("程序结束")
# code15_继承Thread创建多线程.py
from threading import Thread
import time
def fun1(delay, thread_name):
print("start: {}".format(thread_name))
time.sleep(delay)
print("end: {}".format(thread_name))
def fun2(delay, thread_name):
print("start: {}".format(thread_name))
time.sleep(delay)
print("end: {}".format(thread_name))
# 继承Thread类,重新run()方法
class MyThread(Thread):
def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None):
super().__init__(group, target, name, args, kwargs, daemon=daemon)
# 这里不修改run()方法....
def run(self):
super().run()
if __name__ == "__main__":
print("程序开始")
t1 = MyThread(target=fun1, args=(2, "Thread-1"))
t2 = MyThread(target=fun2, args=(4, "Thread-2"))
# 启动线程
t1.start()
t2.start()
# 阻塞主线程
t1.join()
t2.join()
print("程序结束")
同处在一个进程的线程间共享数据
# code16_多个线程之间数据共享.py
from threading import Thread
num = 10 # 全局变量
def work1():
# 要修改全局变量要先使用global声明
global num
num += 5
print("子进程1运行后: num的值:", num)
def work2():
# 要修改全局变量要先使用global声明
global num
num += 10
print("子进程2运行后: num的值:", num)
if __name__ == "__main__":
print("主线程开始运行")
# 创建子进程
t1 = Thread(target=work1)
t2 = Thread(target=work2)
# 启动子进程(同时启动,再join()就相当于是异步了)
t1.start()
t2.start()
t1.join()
t2.join()
print("主线程结束运行")
print("主线程运行后: num的值:", num)

# code17_多线程共享数据的问题.py
# 这里以典型的买票作为例子
# 总票数一定,多个售票窗口(多线程)
# 如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
from threading import Thread, currentThread
from multiprocessing import current_process
total_ticket = 20
def sale_ticket():
global total_ticket
while total_ticket > 0:
total_ticket -= 1
print("{}卖出一张票,当前还剩 {} 张票".format(currentThread().name, total_ticket))
if __name__ == "__main__":
# 只是测试 => 之前都不知道都当前进程这个方法
# print(current_process().name)
# 创建多个线程 => (模拟多个售票窗口)
t1 = Thread(target=sale_ticket,name="售票窗口01")
t2 = Thread(target=sale_ticket,name="售票窗口02")
t3 = Thread(target=sale_ticket,name="售票窗口03")
t4 = Thread(target=sale_ticket,name="售票窗口04")
t5 = Thread(target=sale_ticket,name="售票窗口05")
t6 = Thread(target=sale_ticket,name="售票窗口06")
# 启动线程
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
# 阻塞主线程
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
t6.join()
from threating import Lock
互斥锁经典例子 => 很多人等待的公厕(有人,没人两种状态)
1. 当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
2. 线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
3. 互斥锁为资源引入一个状态:锁定/非锁定
4. 某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。
5. 互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
6. Lock可以实现简单的线程同步
(1) acquire() => 上锁
(2) release() => 解锁
# code18_互斥锁.py
# 这里以典型的买票作为例子
# 总票数一定,多个售票窗口(多线程)
# 如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
from threading import Thread, currentThread, Lock
import time
total_ticket = 10000
def sale_ticket():
global total_ticket
while total_ticket > 0:
mutex_lock.acquire() # 对资源上锁
if total_ticket > 0:
total_ticket -= 1
print("{}卖出一张票,当前还剩 {} 张票".format(currentThread().name, total_ticket))
mutex_lock.release() # 对资源解锁
if __name__ == "__main__":
# 锁是在主线程中创建的
mutex_lock = Lock() # 创建互斥锁
# 创建多个线程 => (模拟多个售票窗口)
t1 = Thread(target=sale_ticket, name="售票窗口01")
t2 = Thread(target=sale_ticket, name="售票窗口02")
t3 = Thread(target=sale_ticket, name="售票窗口03")
t4 = Thread(target=sale_ticket, name="售票窗口04")
t5 = Thread(target=sale_ticket, name="售票窗口05")
t6 = Thread(target=sale_ticket, name="售票窗口06")
# 启动线程
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
# 阻塞主线程
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
t6.join()
1. 在线程共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
2. 死锁的情况
(1) 上锁和解锁次数不匹配
(2) 两个线程互相使用对方的互斥锁
线程和进程都具有独立运行,状态不可预测,执行属性随机的特点
线程/进程同步 => 就是让这些线程/进程按照我们预想的顺序去执行
1. 同步就是协同步调,按预定的先后次序进行运行。例如:开会。“同”字指协同、协助、互相配合。
2. 进程、线程同步,可以理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行,B运行后将结果给A,A继续运行。
1. 生产者是生产数据的线程,消费者是消费数据的线程 => 二者的处理数据速度往往不相等
(1)如果生产速度很快,消费速度慢,那么生产者就必须等待消费者消耗完毕才能继续生产
(2)如果消费速度很快,生产速度慢,那么消费者就必须等生产者生产出来才能继续消费
2. 解决办法就是 => 队列缓存
(1) 生产者生产完东西直接存储在队列中,不必等待消费者处理
(2) 消费者消费东西直接从队列中取,不必等待生产者生产
3. 策略的制定
(1) 要有一个策略来规定 => 队列中元素多少时,生产者应该生产多少,消费者应该消费多少
原文:https://www.cnblogs.com/Rowry/p/12538487.html