书籍背景:Josiah L.Carlson著作,用Python语言进行交互,redis版本为2.6
我将书籍讲述的内容分为两个部分:1、Redis本身的功能与作用;2、以代码实现的高级功能
Redis是一种基于内存,键值存储的非关系型数据库,常用5种数据结构。
STRING(字符串),LIST(列表),SET(集合),HASH(散列),ZSET(有序集合)--地理位置和基数(不常用)
| 结构类型 | 结构存储的值 | 结构的读写能力 |
| STRING | 可以是字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作:对整数和浮点数执行自增或自减 |
| LIST | 一个链表,链表上的每个节点都包含了一个字符串 | 从链表的两端推入或弹出元素;根据偏移量对链表进行修剪;读取单个或者多个元素;根据值查找或者移除元素 |
| SET | 包含字符串的无序收集器,每个字符独一无二、不相同 | 添加、获取、移除单个元素;检查一个元素是否存在集合中;计算交集、并集、差集 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对;获取所有键值对 |
| ZSET(有序集合) | 字符串成员与浮点数分值之间的有序映射,元素的排列顺序由分值的大小决定 | 添加、获取、删除单个元素;根据分值范围或者成员来获取元素 |
以下为5种数据结构的存储形式图
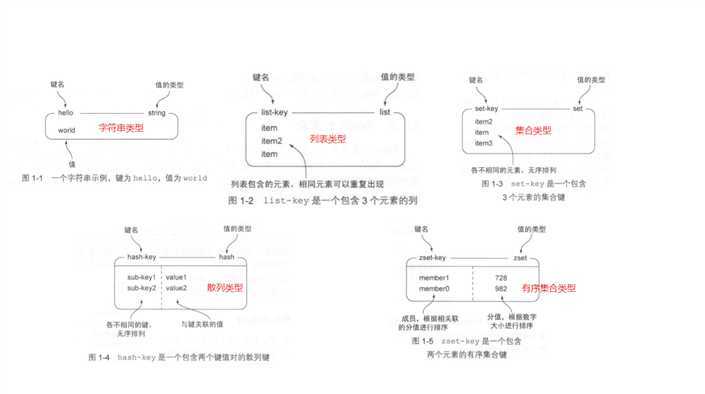
有点特别的是:HASH类型的存储key-value,value内容类似pojo的实体类。ZSET类型的value包含一个score
| 命令 | 用例和描述 |
| INCR | INCR key-name------自增1 |
| DECR | DECR key-name-----自减1 |
| INCRBY | INCRBY key-name amount----加上整数amount |
----如果值可以被解释成数字则可操作,如果无法解释成数字则会返回一个错误
| 命令 | 用例和描述 |
| APPEND | APPEND key-name value------追加到末尾 |
| GETRANGE | GETRANGE key-name start end-----得到范围字符串,包括start,end位置的值 |
----如果读者使用2.6及以上版本,最好使用GETRANGE,不要SUBSTR
| 命令 | 用例和描述 |
| R(L)PUSH | R(L)PUSH key-name value [value ...]------可推入到右(左)端多个值 |
| R(L)POP | R(L)POP key-name-----移除并返回最右(左)的元素 |
| LINDEX | LINDEX key-name offset------得到offset位置的值 |
| LRANGE | LRANGE key-name start end-----返回范围内的元素,包括start和end |
| LTRIM | LTRIM key-name start end----截取列表,保留start和end |
| BR(L)POP | BR(L)POP key-name [key-name ...] timeout 从第一个非空列表中弹出最右(左)端的元素,或在timeout之内阻塞并等待可弹出的元素出现 |
| BRPOPLPUSH | BRPOPLPUSH source-key dest-key timeout 从source-key列表弹出最右端的元素,推入到dest-key的最左端,并返回这个元素,如果没有则等待timeout秒,直到出现 |
-----BR(L)POP,BRPOPLPUSH为阻塞弹出命令
| 命令 | 用例和描述 |
| SADD | SADD key-name item [item ...]------添加一至多个元素,并返回被添加的并不存在于集合的数量 |
| SREM | SREM key-name item [item ...]-----移除一至多个元素,被移除的数量 |
| SISMEMBER | SISMEMBER key-name item------检查是否在集合中 |
| SPOP | SPOP key-name -----随机移除一个元素,并返回被移除的元素 |
| SMOVE | SMOVE source-key dest-key item----从source-key移除,添加到dest-key,如果被成功移除则返回1,否则返回0 |
| 命令 | 用例和描述 |
| SDIFF | SDIFF key-name [key-name ...]------返回存在于第一个集合,但不存在与其他集合的元素(差集) |
| SDIFFSTORE | SDIFFSTORE dest-key key-name [key-name ...]----- 将差集存到dest-key中 |
| SINTER(STORE) | SINTER(STORE) (dest-key) key-name [key-name ...]------返回交集(存到dest-key中) |
| SUNION(STORE) | SUNION(STORE) (dest-key) key-name [key-name ...] -----返回并集(存到dest-key中) |
| 命令 | 用例和描述 |
| HMGET | HMGET key-name key [key ...]------从散列获取一个或多个键值 |
| HMSET | HMSET key-name key value [key value...]----- 设置一个或多个 |
| HDEL | HDEL key-name key [key ...]------删除一个或多个 |
| HLEN | HLEN key-name -----返回包含的键值对数量 |
----------HMGET,HMSET方法减少命令的调用次数以及客户端与Redis之间的通信往返次数-----提升性能
| 命令 | 用例和描述 |
| HEXISTS | HEXISTS key-name key ------是否key存在散列中 |
| HKEYS | HKEYS key-name -------获取散列包含的所有键 |
| HVALS | HVALS key-name ------获取所有值 |
| HGETALL | HGETALL key-name -----获取所有键值对 |
| HINCRBY | HINCRBY key-name key increment-----将键key的值加上increment |
------如果散列包含的值很大,可以HKEYS得到所有键,再HGET一个一个取出值,避免一次获取大体积的值导致服务器阻塞
| 命令 | 用例和描述 |
| ZADD | ZADD key-name score member [score member ...]------添加 |
| ZREM | ZREM key-name member [member ...]-------移除,返回被移除的数量 |
| ZCOUNT | ZCOUNT key-name min max------返回分值位于min,max之间的数量 |
| ZRANK | ZRANK key-name member -----返回member在集合里面的排名 |
| ZSCORE | ZSCORE key-name member -----返回member的分值 |
| ZRANGE | ZRANGE key-name start stop [WITHSCORES]------返回排名在start stop之间的成员,如果给定了可选的WITHSCORE则一并返回分值 |
| 命令 | 用例和描述 |
| ZREVRANK | ZREVRANK key-name member ------返回member的排名,按照从大到小排列 |
| ZREVRANGE | ZREVRANGE key-name start stop [WITHSCORES]-------返回范围内的成员,从大到小排列 |
| ZRANGEBYSCORE | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]------返回分值位于min,max之间的成员 |
| ZREVRANGEBYSCORE | ZREVRANGEBYSCORE key-name max min [WITHSCORES] [LIMIT offset count] -----返回分值在min,max之间的所有成员,并按照分值从大到小返回 |
| ZREMRANGEBYRANK | ZREMRANGEBYRANK key-name start stop-----移除排名在start,stop之间的所有成员 |
| ZREMRANGEBYSCORE | ZREMRANGEBYSCORE key-name min max------移除分值在min,max之间的所有成员 |
| ZINTERSTORE | ZINTERSTORE dest-key key-count key [key ...] [WEIGHTS weight [weight...]] [AGGREGATE SUM|MIN|MAX] -----交集运算 |
| ZUNIONSTORE | ZUNIONSTORE dest-key key-count key [key ...] [WEIGHTS weight [weight...]] [AGGREGATE SUM|MIN|MAX] -----并集运算 |
| 命令 | 用例和描述 |
| PERSIST | PERSIST key-name ------移除键的过期时间 |
| TTL | TTL key-name -------查看距离键过期还有多少秒 |
| EXPIRE | EXPORE key-name seconds------seconds秒后过期 |
| EXPIREAT | EXPIREAT key-name timestamp -----设置过期时间为给定的UNIX时间戳 |
| PTTL | PTTL key-name -----查看距离过期还有多少毫秒,2.6版本以上可用 |
注意:对于LIST,SET,HASH,ZSET四种类型,只能为整个键设置过期,不能为key对应的value中的单个元素设置
| 命令 | 用例和描述 |
| (UN)SUBSCRIBE | (UN)SUBSCRIBE channel [channel ...] ------(退订)订阅一个或多个频道,退订时如果没有给定任何频道,就退订所有 |
| PUBLISH | PUBLISH channel message-------发送消息 |
| P(UN)SUBSCIRBE | P(UN)SUBSCIRBE pattern [pattern ...]------(退订)订阅给定的模式,如果没有给定模式则退订所有模式 |
存在的问题:
系统的稳定性:
(2.6版本前)订阅了某个频道,但读取速度不够,不断积压的消息会使得Redis输出缓冲区的体积变得越来越大,会导致Redis的速度变慢,甚至崩溃。
(2.6版本后)不会出现旧版的问题,会自动断开不符合client-output-buffer-limit pubsub配置选项要求的客户端
client-output-buffer-limit 设置服务器在处理订阅操作时为每个客户端分配的最大输出缓冲区大小
传输的可靠性:如果在执行订阅操作的过程中断线,那客户端会丢失断线期间发送的所有消息
解决:用消息拉取的方式
--------让一个客户端在不被其他客户端打断的情况下执行多个命令,事务里面的命令会一个个执行,直到执行完
命令:
好处:减少Redis与客户端之间的通信往返次数;提升执行多个命令时的性能
流水线:事务的命令其实是由流水线(pipeline)实现的,可以选择非事务型流水线(将多个命令放入一个队列,发送一次)
配置参数
弊端:如果系统崩溃,会丢失最后一次和下一次之间的数据
配置参数
弊端:AOF文件的体积越来越大,还原的时间就越来越长
解决:BGREWRITEAOF命令
需要配置的参数:
auto-aof-rewrite-min-size 64mb
auto-aof-rewrite-percentage 100
----当aof文件大于64mb,并且aof文件的体积比上一次重写之后大了至少一倍的时候,Redis将执行BGREWRITEAOF命令
伴随的弊端:还原的时间更长了
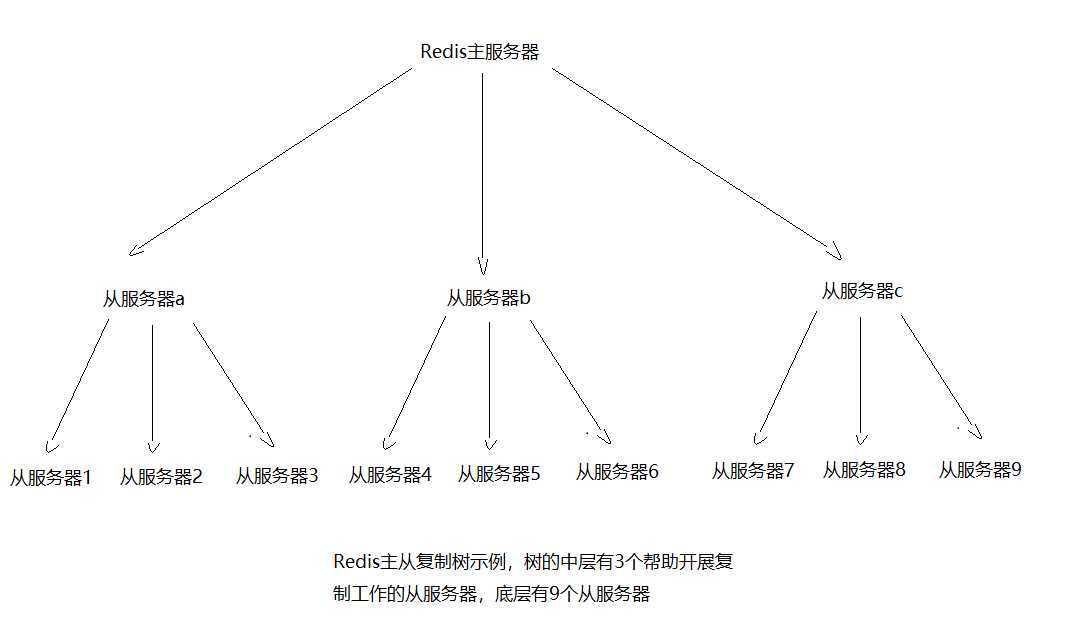
-------添加从服务器,扩展读性能
SLAVEOF no one----终止复制操作
SLAVEOF host port----开始复制一个新的主服务器
| 步骤 | 主服务器操作 | 从服务器操作 |
| 1 | (等待命令进入) | 连接(或者重连接)主服务器,发送SYNC命令 |
| 2 | 开始执行BGSAVE,并使用缓冲区记录BGSAVE之后执行的所有写命令 | 根据配置选项来决定是继续使用现有的数据(如果有的话)来处理客户端的命令请求,还是向发送请求的客户端返回错误 |
| 3 | BGSAVE执行完毕,向从服务器发送快照文件,并在发送期间继续使用缓冲区记录被执行的写命令 | 丢弃所有的旧数据(如果有的话),开始载入主服务器发来的快照文件 |
| 4 | 快照文件发送完毕,开始向从服务器发送存储在缓冲区里面的写命令 | 完成对快照文件的解释操作,像往常一样开始接受命令请求 |
| 5 | 缓冲区存储的写命令发送完毕,从现在开始,每执行一个写命令,或向从服务器发送相同的写命令 | 执行主服务器发来的所有存储在缓冲区里面的写命令;并从现在开始,接受并执行主服务器传来的每个写命令 |
1、从服务器在进行同步时,会清空自己的所有数据;2、Redis不支持主主复制
如果从服务器过多,采取主从链,如图所示
命令:SETNX,SETEX(带有超时限制特性的锁)
--------悲观锁,即获取锁的线程获得后,得等到当前线程释放后才能被其他线程得到,类似mysql的锁和java的synchronized
------可以让用户限制一项资源最多能够同时被多少个进程访问,通常用于限定能够同时使用的资源数量
讲解在第二部分(计数信号量)
可以通过 短结构,分片 来降低内存占用
通用:减少键的长度
好处:
使用短结构来降低内存-----可用于列表,集合,散列,有序集合
短结构并不是一种结构,而是一种称呼
----以序列化的方式存储数据(用于列表,散列,有序集合)
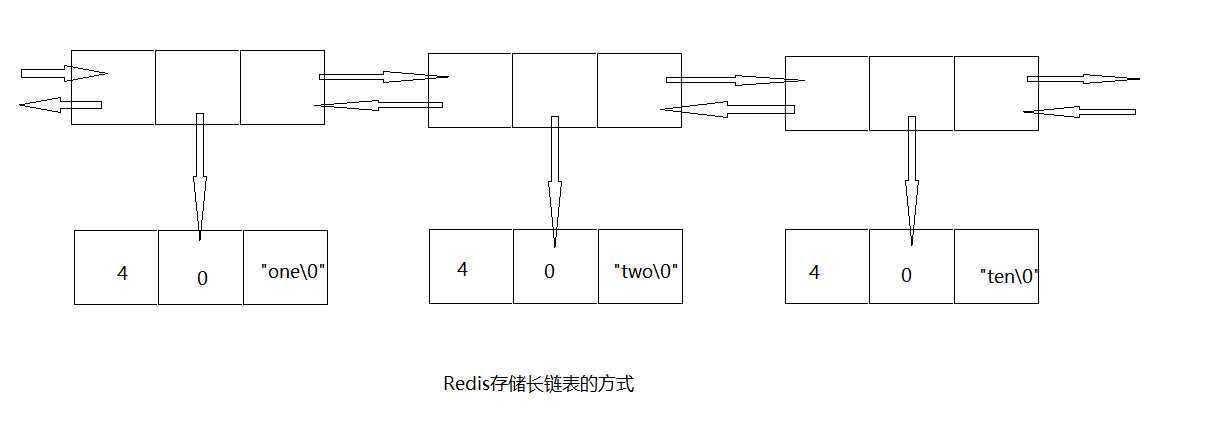
不用压缩列表时,存储结构通常使用双向链表表示,如图所示(省略了一些细节):
 ,
,
每个值由一个节点表示
包含3个指针,指向前后,和自身数据
自身数据包含字符串长度,字符串剩余可用字节数,以及字符串本身
图中展示了3个3字符长的字符串,每个都需要空间存储3个指针,2个整数,字符串本身以及一个额外的字节
每个节点由两个长度值和一个字符串组成
第一个长度值记录前一个节点的长度,第二个记录当前长度,位于最后的就是字符串
以例子中的"one","two","ten"这3个3字节长的字符串来说,每个长度都可以用1字节来存储。所以每个字节只会有2字节的额外开销
效果:
在32位的平台上,双向链表的开销为21个字节,从21个字节降低到2个字节
配置选项(列表结构使用压缩列表的限制条件)
list-max-ziplist-entries 512-----在被编码为压缩列表的情况下,允许包含的最大元素
list-max-ziplist value 64----说明压缩列表每个字节的最大体积是多少字节
当配置的选项被突破,则会从压缩列表转换为其他结构; 当未来该列表满足配置条件后,也不会转为压缩列表
命令
debug_object key-name
serializedlength(返回的内容之一)------占用了多少内存结构
弊端: 体积变大后,解码编码费时
解决(作者提供的最佳配置): 长度在1024个字节;每个元素的体积不超过64个字节
形式:有序整数数组
条件
弊端:体积变大后,插入或删除会对数据进行移动,费时
---------将Lua脚本发送给Redis,加载完后通过加载完传回的SHA1值调用,同时传入脚本用到的key和参数
载入脚本:SCRIPT LOAD命令
--------载入的脚本可以随时调用
清除脚本: SCRIPT FLUSH命令
调用命令:
EVALSHA;EVAL(执行脚本,还会把执行后的脚本缓存到服务器中)
调用方式:
加载完后会给传给客户端一个对应的SHA1值,发送SHA1值进行调用(EVALSHA)时,需要传入多个键(脚本可能会读取或写入的所有键),和多个参数(参数为客户端传入的)
Lua脚本的参数下标从1开始
如果脚本访问的全部键不在同一个服务器里,会返回错误;尽量都有返回值,来判断脚本是否执行完毕
以下是以代码实现的高级功能
服务端将需要发送的消息推入到有序列表中,客户端循环查询该有序列表,有未读消息就读取
本质上就是基于某些简单的规则,将数据划分为更小的部分,然后根据数据所需的部分来决定将数据发送到哪个位置上。也就是不将值X存储到键Y中,而是存到键Y:<shardid>里面
对有序集合进行分片的意义不大,因为ZRANGE,ZRANGEBYSCORE这类命令的分片版本需要对有序集合的所有分片进行操作才能计算出命令的最终结果
程序为每个尝试获取信号量的进程生成一个唯一标识符,存入到有序集合中,成员对应得分值为当前进程获取信号量时的Unix时间戳。接着进程会检查自己的标识符在有序集合中的排名,如果排名低于可获取的信号量总数(排名从0开始计算),则成功获取。反之,则未取得。
弊端:如果各个系统的系统时间不完全相同,则会出现问题。
解决:公平信号量
创建一个计数器以及一个有序集合。其中计数器持续自增,对计数器执行自增操作的客户能够获得信号量。将计数器生成的值用作分值,存储到“信号量拥有者”有序集合里,最后检查客户端生成的标识符在有序集合中的排名来判断客户端是否取得了信号量。

本书还介绍了 打包存储二进制位和字节 来降低内存占用,用Lua脚本实现公平锁等,我这里不再介绍,感兴趣的读者可以去阅读,确实是一本好书。
这是我的第一个关于书籍总结的博客,想尽量做到字数最少来介绍书籍讲了什么,大家如果有什么建议也可以发我,不管是页面的排版还是我写的内容。如果大家不喜欢也请不要喷我,我只是一个卑微的搬砖工。
原文:https://www.cnblogs.com/rach/p/12458060.html