这是一篇软工课程博客
【TODO 表格 PLACEHOLDER】
在上一篇博客中我简单介绍了OCR Form Tools及其本地部署,这篇博客则将进一步评测整个软件。
本工具的数据存储基于Azure存储服务,下文使用的均为开发老师提供的测试仓库,内含5份训练用表单pdf文件。同时本地有一份相同格式的表单pdf文件,作为测试数据用。
运行后看到初始界面。
可以看到整体界面设计走的是微软在10年后一贯的扁平风,dark theme的配色让人一下子联想起其王牌产品vs和vsc。点击New Project尝试新建一个表单识别项目:
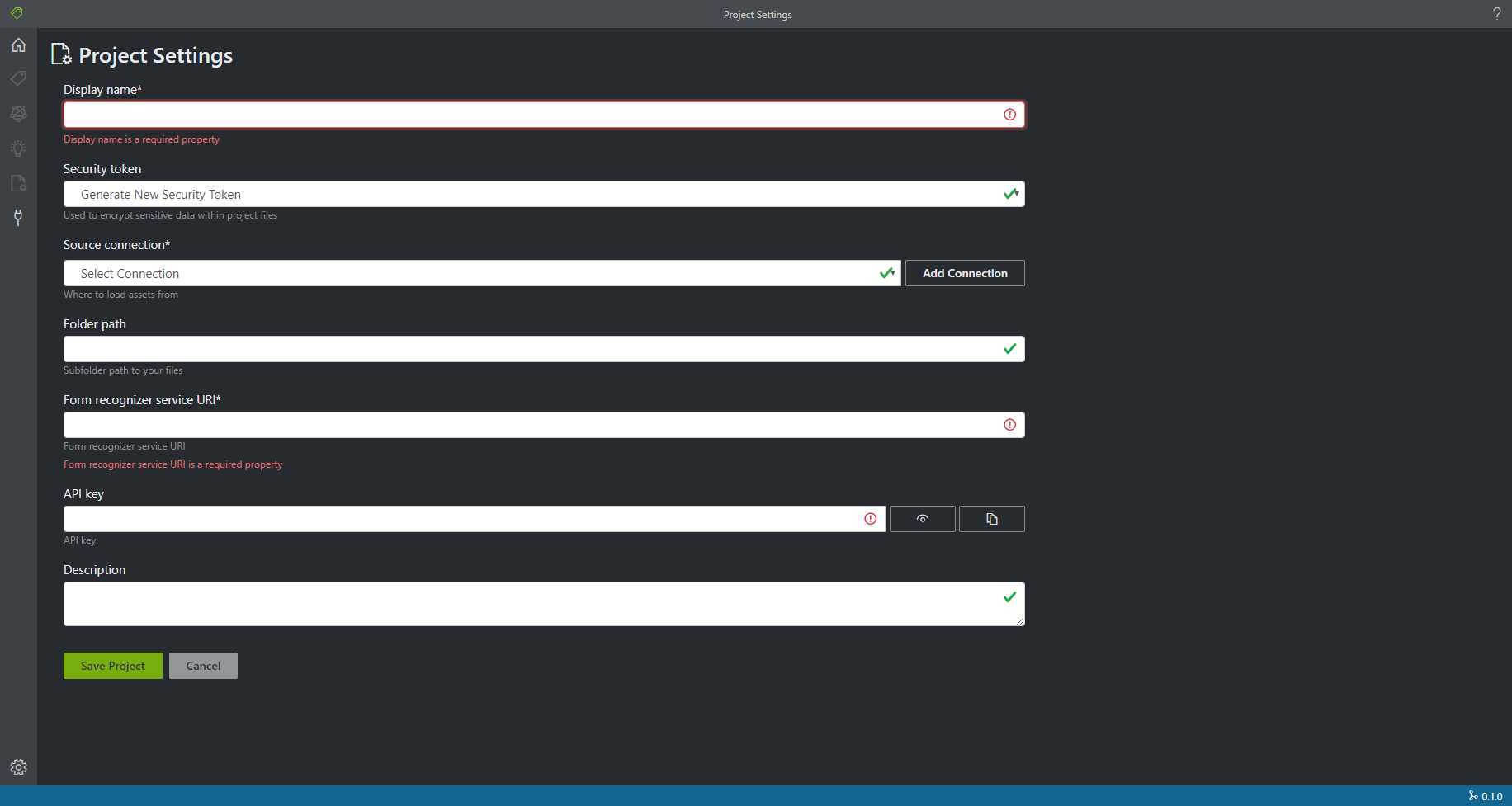
这个表单的各种verify都是齐全的,placeholder和键入提示也非常清晰。
注意到这里需要添加一个新的Connection才能与Azure存储服务建立关联。界面中很贴心地提供了“Add Connection”按钮,也可以直接点击界面左侧的小插销图标进入Connection管理页面并完成添加。
完毕后回到刚才的新建项目表单。继续完成其余的信息填写并创建新的表单识别项目

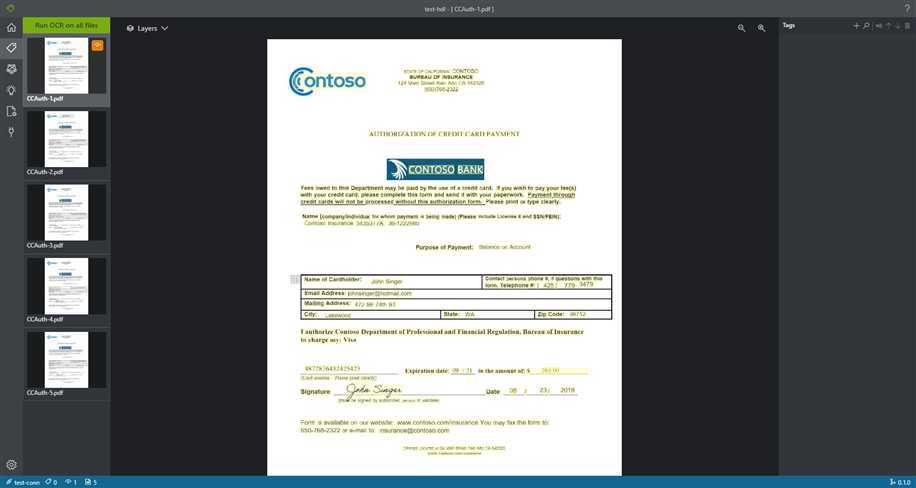
进入编辑器,看到待标注的pdf预览页面。
为了训练识别模型,我们需要把待标注的表单中,我们感兴趣的信息(如姓名、地址、电邮)标注出来,作为不同的特征以备模型使用。为了区分这些信息,我们要将其标上不同的tag
首先添加名为Name的tag并将它的类型设为string
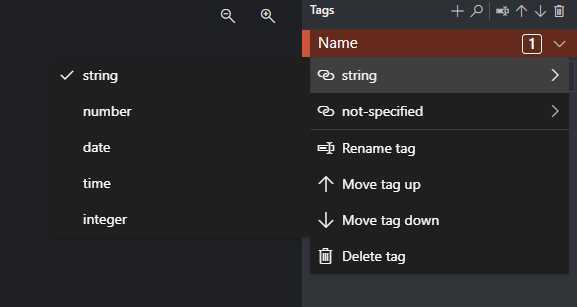
点选pdf文档中的名字字段John Singer,看到选框变色后按下提示的标注键“1”,看到名字被红框框选并出现在右侧Name tag下,标注成功。

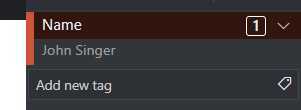
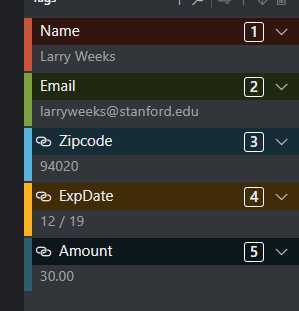
依次添加Email、Zipcode、ExpDate、Amount几个tag,并为其指定string、integer、date、number类型,来测试不同类型tags的标注;在全部五份pdf上完成上述tags的标注
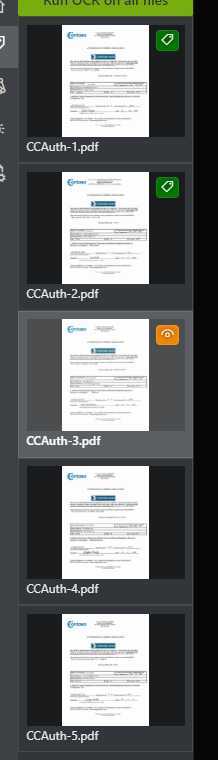
可以看到已标注的文件会有一个小图标标记。
标注用的pdf阅读器支持滚轮缩放与拖拽移动,由于做了ocr预处理所以文本点选十分便利,按提示键入数字标注,键入delete删除,键鼠配合下可以迅速完成标注。五份文件的五种tags标注我在十分钟内全部完成,效率相当高。
标注完成后点击左侧train按钮进入训练页面
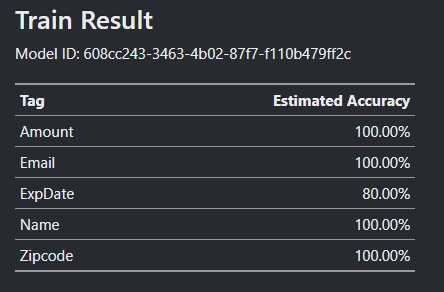
点击右侧的train训练一个新模型,完成后返回了模型信息和各tag的预测准确率
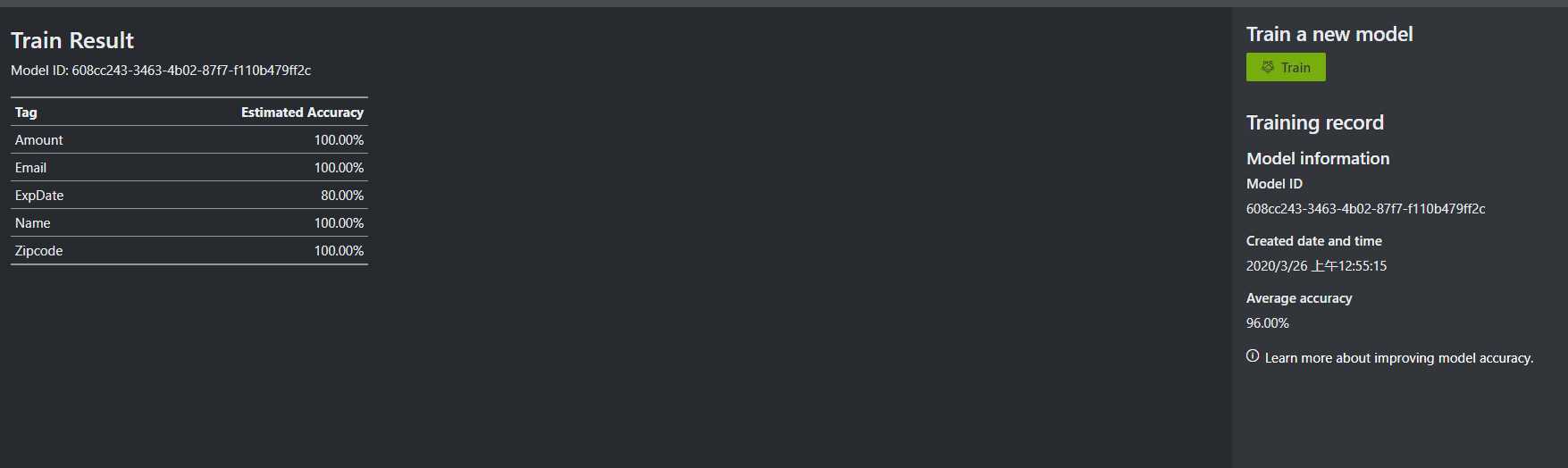
训练得到模型后点选左侧predict页面,尝试使用刚刚训练的模型预测一份新的pdf。Browse选择文件后在左侧预览,然后点击predict开始预测
完成后返回结果和置信度
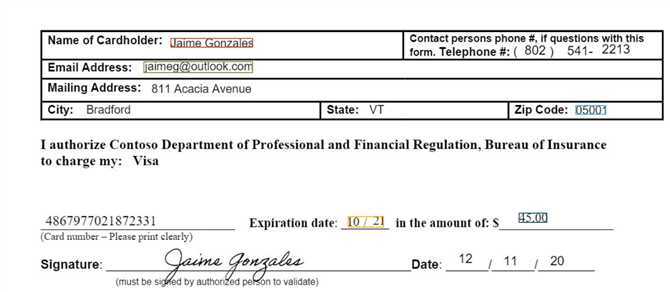
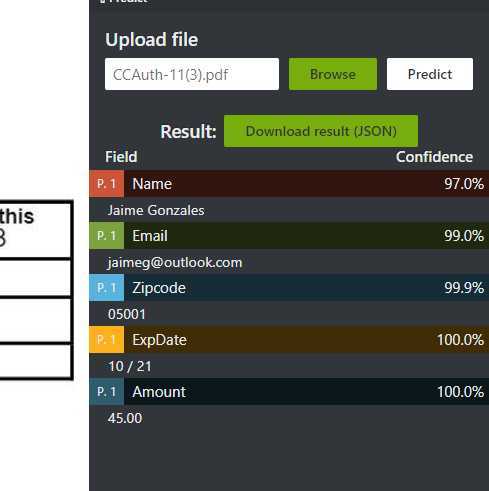
可以看到各个tags都被正确框选了。由于这个pdf并没有出现在训练集里,因此说明模型训练很成功。注意到还可以下载json格式的预测结果(原文太长,这里截取其中一段):
"fields":{"Email":{"type":"string","valueString":"jaimeg@outlook.com","text":"jaimeg@outlook.com","page":1,"boundingBox":[2.045,6.0200000000000005,3.345,6.0200000000000005,3.345,6.15,2.045,6.15],"confidence":0.99,"elements":["#/analyzeResult/readResults/0/lines/25/words/0"],"fieldName":"Email","displayOrder":1},"Zipcode":{"type":"integer","valueInteger":5001,"text":"05001","page":1,"boundingBox":[7.2250000000000005,6.55,7.58,6.55,7.58,6.655,7.2250000000000005,6.655],"confidence":0.999,"elements":["#/analyzeResult/readResults/0/lines/33/words/0"],"fieldName":"Zipcode","displayOrder":2},"Amount":{"type":"number","text":"45.00","page":1,"boundingBox":[6.54,7.84,6.875,7.84,6.875,7.95,6.54,7.95],"confidence":1,"elements":["#/analyzeResult/readResults/0/lines/42/words/0"],"fieldName":"Amount","displayOrder":4},"ExpDate":{"type":"date","text":"10 / 21","page":1,"boundingBox":[4.49,7.88,4.92,7.88,4.92,8.01,4.49,8.01],"confidence":1,"elements":["#/analyzeResult/readResults/0/lines/38/words/0","#/analyzeResult/readResults/0/lines/39/words/0","#/analyzeResult/readResults/0/lines/40/words/0"],"fieldName":"ExpDate","displayOrder":3},"Name":{"type":"string","valueString":"Jaime Gonzales","text":"Jaime Gonzales","page":1,"boundingBox":[2.365,5.74,3.35,5.74,3.35,5.845,2.365,5.845],"confidence":0.97,"elements":["#/analyzeResult/readResults/0/lines/15/words/0","#/analyzeResult/readResults/0/lines/15/words/1"],"fieldName":"Name","displayOrder":0}}}],"errors":[]}}
自此这个项目的主体功能被我们串通了:首先将pdf训练集上传到azure storage blob,连接并创建项目后借助该工具对其进行标注,然后训练模型,即可得到一个识别该格式表单的模型。此后,将需要识别的新表单输入训练好的模型,即可导出格式化后的表单数据。
总的来说我很喜欢这个工具,我认为它可以大幅改进目前表单处理需要大量人力的境况。具体来说,我认为优点有:
虽然整个工具体验过程很顺滑,但个人认为依旧存在一些小问题:
由于课程作业要求寻找软件Bug,我在不同运行环境与浏览器下对软件进行了黑箱测试,发现如下问题:
首先在Docker Toolbox虚拟环境下以docker运行时,连接远程仓库会失败。报错信息难以被用户理解,因此这应该是开发者意料之外的未处理异常:
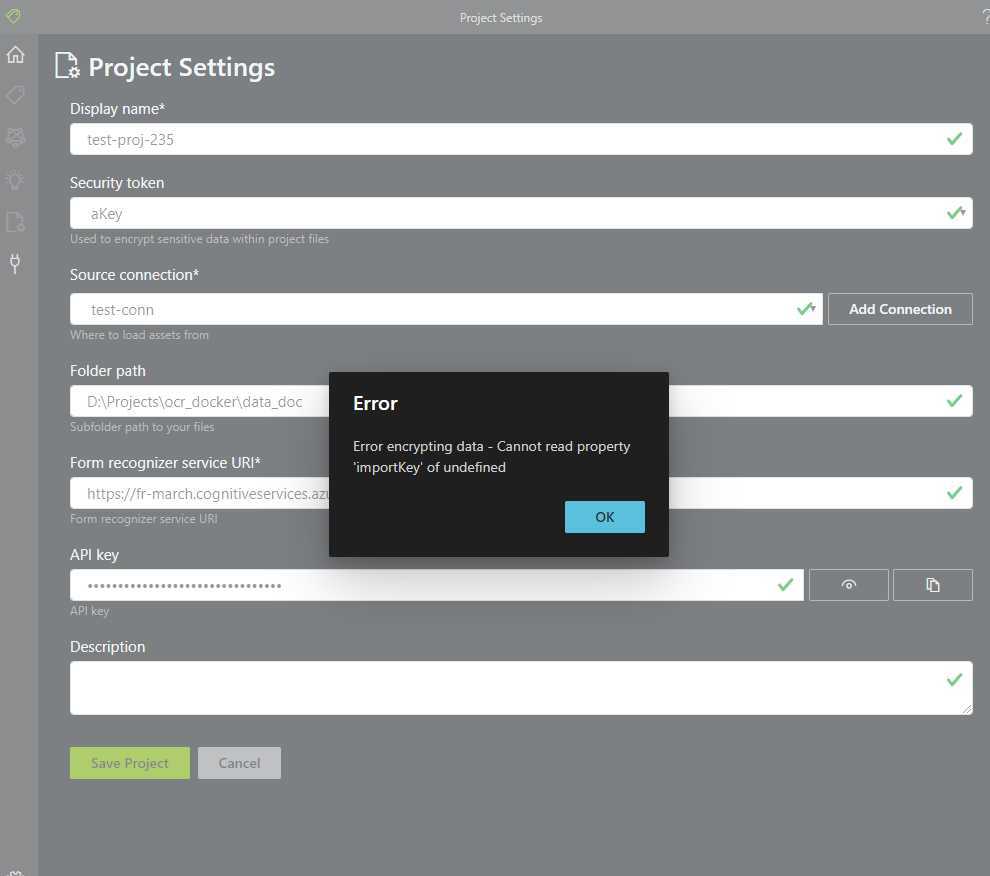
由于官方提供的docker镜像已为release版构建,没有提供足够的调试信息,同时考虑windows下模拟Docker Toolbox的网络环境进行复现较为复杂,因此这里没有进一步尝试定位错误原因,仅作出错误报告。
另一个问题有关标注。在标注测试文件中的小数数据时,会发生一次点击后单条数据被重复标注的情况:
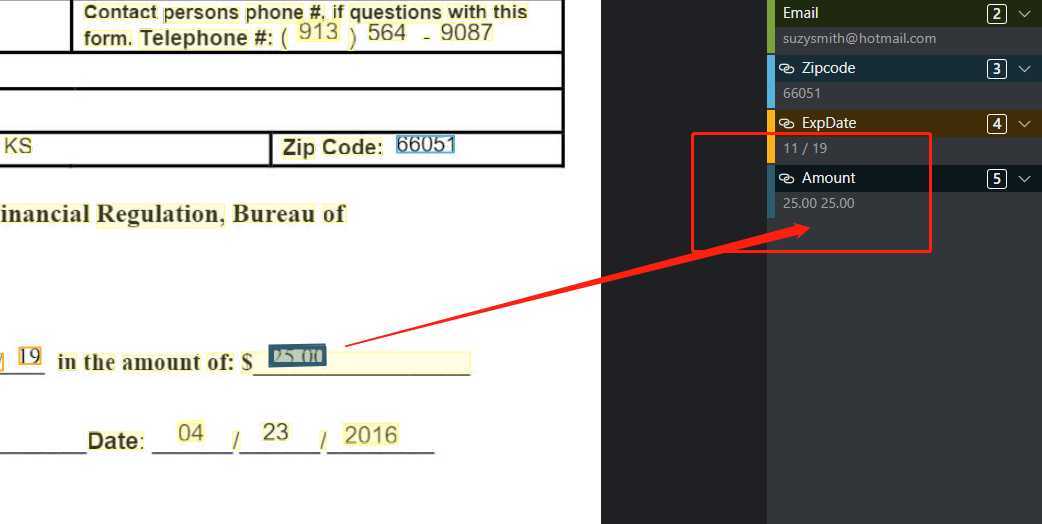
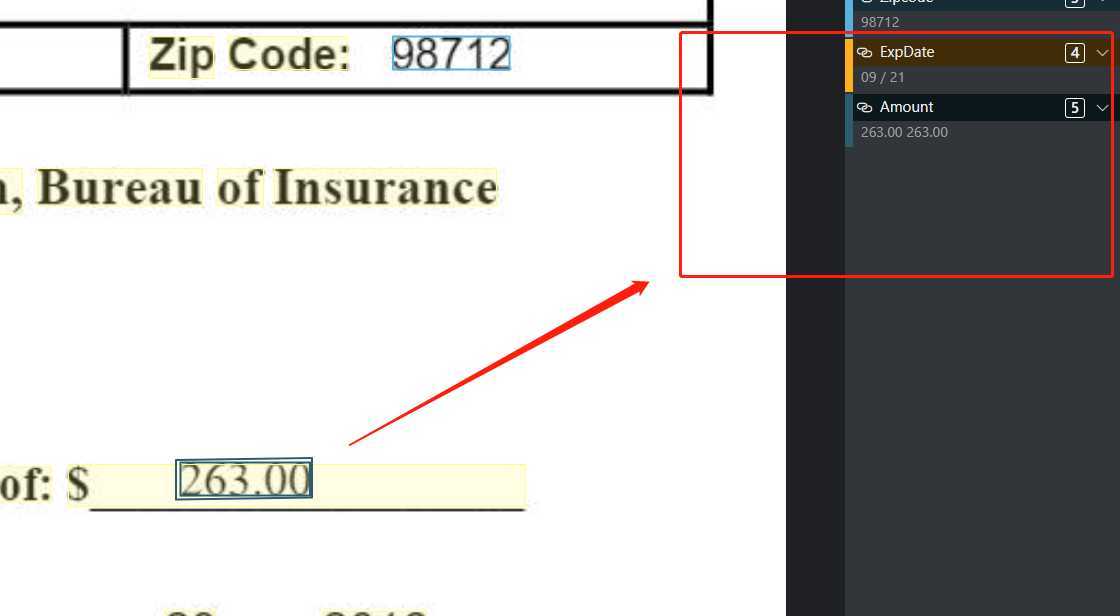
上图分别为点选测试文件CCAuth-1.pdf和CCAuth-2.pdf中amount字段并标注的结果,可以发现小数都被错误地选择了两次。分析原因可能是因为pdf文档中处理小数元素分了父子两级,而两级都被ocr单独识别为一个词块,而两者的碰撞框重合了,因此发生复选。针对这个问题,或许可以考虑,当所选两个词块的范围出现重合或包含时,进行一些判断与处理。
需要指出,这些都不是多么严重的问题——前者是在极端运行环境下才会出现的偶发错误,相对软件的目标群体及使用场景而言完全在可接受范围内;后者则是标注时的一些小概率出现的功能缺陷,也没有显著降低使用体验。
实际上,必须承认这款工具的软件质量是很高的。我在Chrome、Firefox、Edge等多款主流浏览器上进行了大量黑箱测试,均没有发现明显的功能或显示错误。
在完整运行一遍后,我对这个项目的功能已经有了大致认识。我的理解是,这是一个为后端表单识别算法设计的表单标注工具,提供了非常高效易用的格式化表单文件标注功能,借助其可以快速构建训练集;同时其也简化了后续工作,可以立即训练、使用给定训练集上训练的识别模型。
我认为这个工具解决的痛点有:
我理解目前这个项目暂定的用户群体是:
同时我认为这个工具有潜力解决的痛点为:
因此,我认为这个项目未来的潜在用户是:
为了迎合潜在用户,我认为这个工具还需要完成的功能包括:
原文:https://www.cnblogs.com/MisTariano/p/12571423.html