HTTP for Humans,说明使用更简洁方便。
pip install requests
import requests
resp = requests.get("https://www.sohu.com/")
print(resp.content.decode(‘utf-8‘))
如果想要添加headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用params参数。
实例代码:
import requests
params = {
‘q‘: ‘Python‘
}
headers = {
‘user-agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36‘
}
# params接受一个字典或者字符串查询参数,字典类型自动转换为url编码
response = requests.get(‘https://www.so.com/s‘, params = params, headers = headers)
# 查看完整的url地址
print(response.url)
# 查看响应内容,response.text返回的是Unicode格式的数据
print(response.text)
# 查看响应内容,response.content返回的字节流数据
print(response.content.decode(‘utf-8‘))
# 查看响应头的字符编码
print(response.encoding)
# 查看响应码
print(response.status_code)
response.text和response.content的区别
response.text
类型:str
解码类型: 根据HTTP头部对响应的编码作出有根据的推测,推测的文本编码
如何修改编码方式:response.encoding="GBK"
response.content
类型:bytes
解码类型: 没有指定
如何修改编码方式:response.content.deocde("utf-8")
推荐使用response.content.deocde()的方式获取响应的html页面
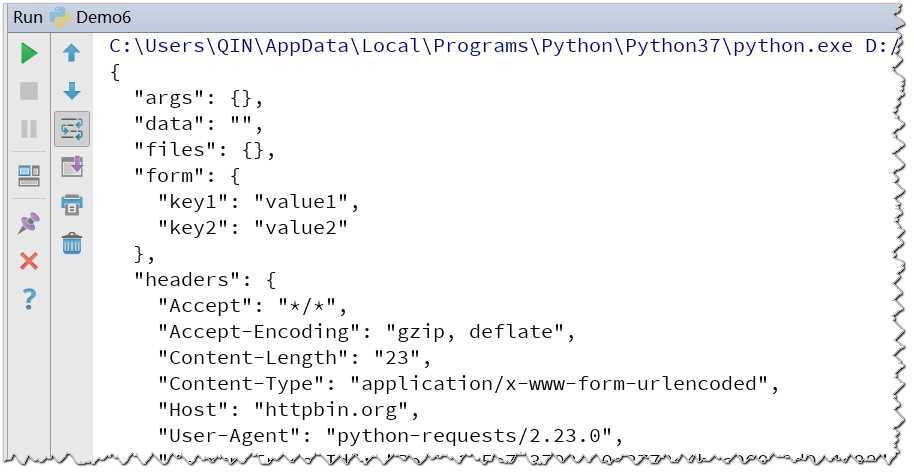
import requests
url = ‘http://httpbin.org/post‘
d = {‘key1‘: ‘value1‘, ‘key2‘: ‘value2‘}
r = requests.post(url, data=d)
print(r.text)
输出结果:
原文:https://www.cnblogs.com/OliverQin/p/12574093.html