Google Chubby是一个分布式锁服务,GFS和Big Table等大型系统都使用它来解决分布式协作、元数据存储和Master选举等一系列与分布式锁服务有关的问题。
Chubby的底层一致性实现是以Paxos算法为基础的。
Google Chubby论文The Chubby lock service for loosely-coupled distributed systems。
什么是分布式锁?
分布式锁,是控制分布式系统之间同步访问共享资源的一种方式。
在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
锁-----> /ls/xxxxxx/mylock(文件)
举例:互斥锁
获取锁,创建文件,文件中记录谁持有了锁
释放锁,删除文件
应用场景
1)Master选举
Google文件系统(Google File System, GFS)中使用chubby锁服务实现GFS Master服务器的选举。
在BigTable(对应Hbase)中,同样使用chubby进行Master的选举。
2)元数据存储
在GFS和Bigtable中,使用chubby进行系统运行时元数据的存储。
设计目标
1)提供完整、独立的分布式锁服务,而不仅仅是一个一致性协议的客户端
好处:对应用程序的侵入性低,应用程序无需修改已有程序结构即可使用。
2)提供粗粒度的锁服务
粗粒度锁:客户端获得锁之后会进行长时间持有(数小时或数天)。
当锁服务短暂失效(如服务器宕机),chubby需要保持所有锁的持有状态,以避免持有锁的客户端出现问题
细粒度锁:短暂获取锁后释放。
锁服务一旦失效,就释放所有锁,因为锁持有时间短,放弃锁的代价相对较小。
3)在提供锁服务的同时提供对小文件的读写功能
举例:Master选举
当一个客户端成功获取到一个chubby文件锁而成为Master之后,就可以向文件中写入Master信息,其他客户端就可以通过读取这个文件得知当前的Master信息
4)高可用、高可靠
高可用
多台机器组成一个chubby集群。基于Paxos算法的实现,对于5台机器组成的chubby集群来说,存在3台正常运行的机器,整个集群就能对外提供服务。
高可靠
通过事件通知机制,chubby能够支撑成千上百个客户端同同一个文件进行监视和读取
5)提供事件通知机制
chubby客户端需要实时感知Master变化情况,当客户端规模不断增大的情况下,如采用客户端主动轮询的方式对服务器性能和网络带宽压力较大。
chubby需要能够通过事件通知的方式将服务端的数据变化(如文件变更)通知给所有订阅的客户端。
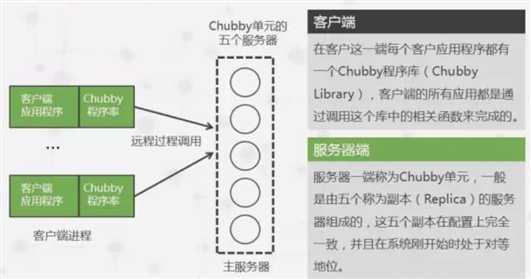
整个系统结构由客户端和服务端组成,客户端和服务端通过RPC调用进行通信。
客户端通过Chubby library的接口调用,在服务端上创建文件来获得相应的锁的功能。
由于整个Chubby系统比较复杂,以下将整个系统分为了三个部分:
服务端的一致性部分(如果保证集群中的各个服务器的数据的一致性)
服务端文件系统部分
客户端和服务端的通信部分
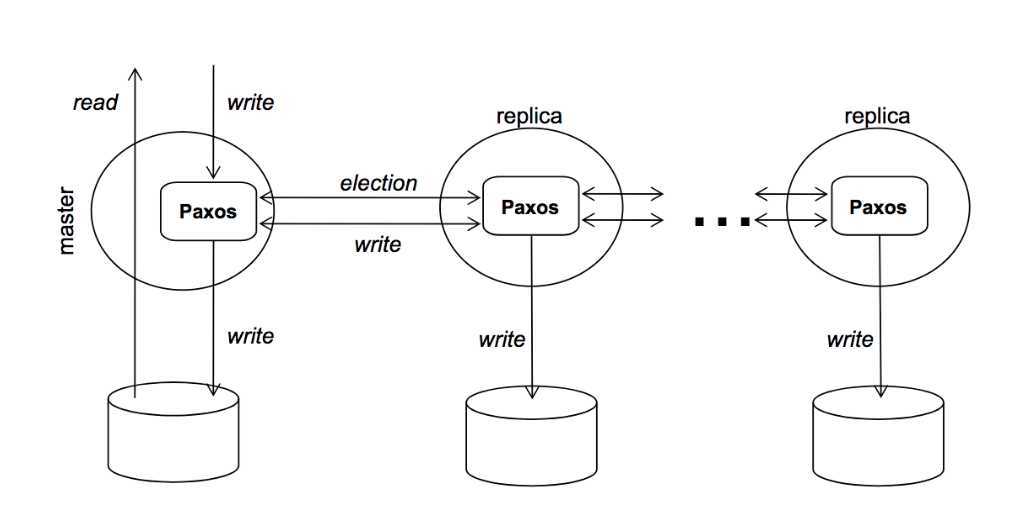
一个Chubby集群通常由5台服务器组成。这些服务器通过Paxos协议,通过投票的方式选举Master,获得过半选票的服务器成为Master。
如果Master服务器故障,剩下的服务器进行新一轮的Master选举,产生新的Master服务器。
Chubby客户端如何定位Master服务器的?
Chubby客户端从记录有Chubby服务器机器列表的DNS获取Chubby服务器列表。
逐个询问是否是Master。询问过程中,非Master的服务器会将Master的服务器地址反馈给客户端
定位到Master服务器后,客户端会将所有的请求发到Master服务器上。
集群中每个服务器都维护者数据库的副本,但是运行过程中,只有Master服务器才能对数据库进行写操作,其他服务器使用Paxos协议从Master服务器上同步数据库数据的更新。
(1)对于写请求
Master通过一致性协议将请求广播给集群中的其他副本服务器。在过半的服务器接收了写请求后,响应给客户端正确的应答。
(2)对于读请求
直接由Master单独处理。
或通过客户端的缓存处理(关于客户端缓存的内容在后面)。
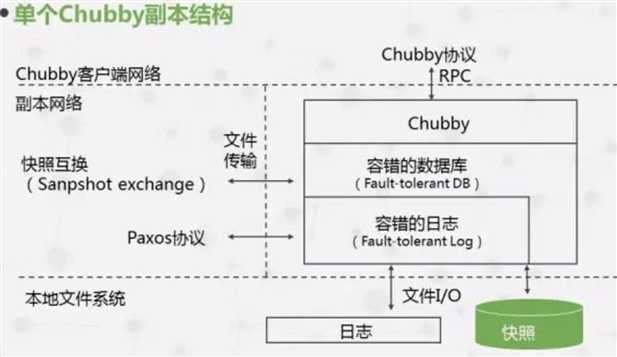
服务端的基本架构分为3层。
最底层是容错日志系统,通过Paxos算法保证集群中所有机器上的日志完全一致,并具备容错性
日志层之上是Key-Value类型的容错数据库,通过下层的日志保证一致性和容错性
存储层之上是chubby对外提供的分布式锁服务和小文件存储服务
提供了与Unix文件系统类似的访问接口。可以看做是文件和目录组成的树。
/ls/foo/wombat/pouch
其中,ls是所有chubby节点共有的前缀,代表着锁服务,Lock Service的缩写。
foo是chubby集群的名字,从DNS可以查到一个或多个服务器组成该Chubby集群;wombat/pouch则是真正包含业务含义的名字。
节点类型
1)持久节点
需要显式地调用API接收进行删除。
2)临时节点
和客户端会话绑定,会在对应的客户端会话失效后自动删除
为了避免大量客户端轮询服务器带来的压力,Chubby提供了事件通知机制。
客户端可以向服务器注册事件通知,当触发这些事件的时候,服务端会向客户端发送对应事件通知。消息通知是通过异步发送的。
常见的Chubby事件如下:
1)文件内容变更
举例:Master选举。
当一个客户端成功获取到一个chubby文件锁而成为Master之后,就可以向文件中写入Master信息。
其他客户端会得到通知,然后就可以通过读取这个文件得知当前的Master信息
2)节点删除
节点被删除时,产生节点删除事件。常用于临时节点,可利用此特性判断该临时节点对应的客户端会话是否有效。
3)子节点新增、删除
4)Master服务器转移
当发生Master转移时,会以事件的形式通知客户端。
为了减少客户端的读请求对服务端的压力,除事件通知机制外,客户端还实现了缓存
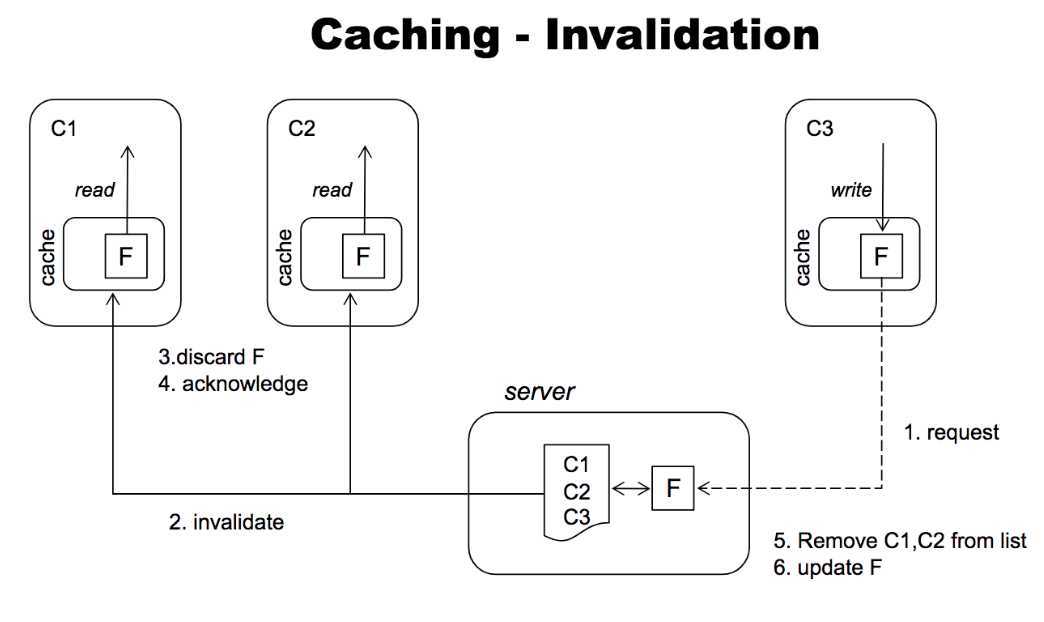
实现缓存能够提供系统整体性能,但带来了一个问题:如何保证缓存的一致性
如何保证缓存的一致性?
Master会维护每个客户端的数据缓存情况。
当文件内容或元数据被修改时,服务端首先会阻塞该修改操作,然后Master会向所有缓存了该数据的客户端发送过期信号,以使其缓存失效,
Master在收到所有相关客户端对该过期信号应答后,在继续进行之前的修改操作。
什么是keepalive?
客户端和服务端通过建立TCP链接进行网络通信,这一连接称为会话,会话存在一个超时时间,在超时时间内,客户端和服务端通过心跳检测保持会话活性,这一过程称为KeepAlive
keepalive请求
Mater接收到客户端的keepalive请求时,首先将请求阻塞住,等到该客户端的当前会话租期即将过期时,为其续租该客户端的会话租期,再向客户端响应这个keepalive请求,同时将最新的会话租期超时时间反馈给客户端。客户端收到来自Master的续租响应后,会立即发起一个新keepalive请求,再由Master进行阻塞。
因此,在正常运行过程中,每一个客户端总是有一个keepalive请求阻塞在Master服务器上。
Master还通过keepalive响应传递事件通知和缓存过期通知,当事件触发时,keepalive响应会提前返回。
会话续租时间默认是12秒,Master会根据自身运行情况,自行调节该周期的长短。
如果Master处于高负载运行状态,Master会适当延长会话租期的长度,减少客户端keepalive请求的发送频率。
客户端也需要维持一个和Master端近似相同的会话租期。
为什么是近似相同?因为客户端必须考虑两个方面的因素:
1)keepalive响应在网络传输中要花费一定的时间
2)Master和客户端存在时间不一致现象。
客户端在运行过程中,按照本地的会话租期超时时间,检测到会话租期已经过期但是尚未接收到Master的keepalive响应,这时,它无法确定Master是否已经终止了当前会话。
客户端此时处于“危险状态”。此时,客户端会将本地缓存标记为不可用。
同时,客户端会等待一个称为“宽限期”(grace period)的时间周期,默认为45秒。
如果在宽限期到期前,客户端和服务器之间成功进行了keepalive,客户端将再次开启缓存,否则,客户端认为当前会话过期,中止此次会话。
Master服务器上运行着会话租期服务器,用于管理所有会话的生命周期。
如果运行过程中出现了故障,计时器会停止,直到新的Master选举产生后,计时器才会继续计时。
即从旧的Master崩溃到新的Master选举产生所花费的时间将不计入会话超时的计算中,等价于延长了客户端的会话租期。
如果新Master短时间内选举成功,客户端将在本地会话租期过期前与其创建连接。
如果新Master的存在花费了较长时间,会导致客户端清空本地缓存,并进入宽限期进行等待。
(宽限期在Master切换过程中的作用)由于宽限期的存在,使得会话能很好地在服务端Master转换过程中得到维持。
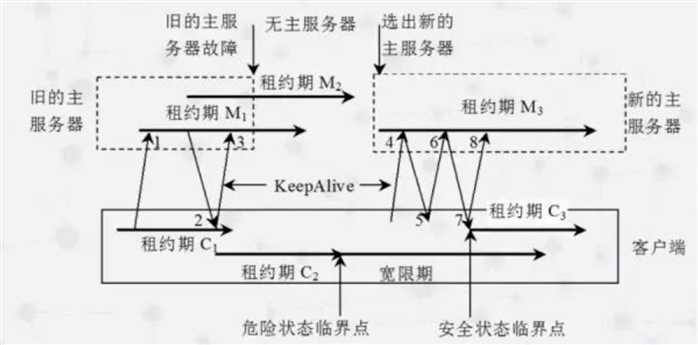
从左到右代表时间轴变化。
横向粗箭头代表会话租期,M为Master的,C为客户端的
斜向上的剪头代表客户端向Master发出的KeepAlive请求
斜向下的剪头代表Master返回个客户端的响应。
|
Master |
客户端 |
|---|---|
|
老Master上维持着会话租期lease M1 |
|
|
客户端上维持着会话租期lease C1。 客户端向老Master发送【keepalive请求1】,并被Master一直阻塞 |
|
|
老Master向客户端响应了【keepalive响应2】,同时开始了新的会话租期lease M2 |
|
|
客户端收到了keepalive响应后,立即发送了新的【keepalive请求3】,同时开始了新的会话租期lease C2 |
|
|
随后,老Master发生了故障,无法响应客户端的keepalive请求3 |
|
|
在这段过程中,客户端检查到会话租期lease C2已经过期,会清空内存,进入宽限期(grace period)。 在这段时间内,客户端无法确定Master上的会话周期是否已经过期,它不会销毁会话,而是将所有应用程序对它的API调用都阻塞住,以避免产生数据不一致。 并在权限期开始时,向上层应用程序发送一个”jeopardy(危险)“事件。 |
|
|
选举除了新的Master,并开始了会话周期lease M3 |
|
|
当客户端向新Master发送keepalive请求4后 |
|
|
Master检测到客户端Master任期号(Master epoch number)已经过期,会在keeplive5响应中拒绝这个客户端请求,并将最新的Master周期号发送给客户端 |
|
|
客户端再次发送Keepalive请求6给新Master,最终,客户端和服务端之间的会话恢复正常 |
|
从上可以看出,在Master转换的这段时间内,只要客户端的宽限期足够长,客户端应用程序就可以在没有任何察觉的情况下,实现Chubby故障恢复。
如果宽限期设置的较短,客户端就会废弃当前会话,并将异常情况通知给上层应用程序。
【1】https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/chubby-osdi06.pdf Chubby论文
【2】https://blog.51cto.com/zorro/1433558 Google Chubby论文中文翻译
【3】https://blog.csdn.net/historyasamirror/article/details/3870168 Google利器之Chubby
【4】http://www.cstor.cn/textdetail_12715.html
【5】https://slidesplayer.com/slide/15101234/
【6】https://slideplayer.com/slide/4463785/
【7】分享《zookeeper几种使用方式和原理》http://www.icoco.tech/%E5%88%86%E4%BA%AB%E3%80%8Azookeeper%E5%87%A0%E7%A7%8D%E4%BD%BF%E7%94%A8%E6%96%B9%E5%BC%8F%E5%92%8C%E5%8E%9F%E7%90%86%E3%80%8B/
《从Paxos到Zookeeper》第3章 Paxos的工程实践
原文:https://www.cnblogs.com/yeyang/p/12577837.html