关于利用GAN做行人ReID的文章:
[NIPS-2018] FD-GAN: Pose-guided Feature Distilling GAN for Robust Person Re-identification。
[CVPR2019] Joint Discriminative and Generative Learning for Person Re-identification.
两篇paper代码均以开源,本文简要分析后者,在GAN生成行人数据做的比较好,提升非常明显。文中提到之前利用GAN做reid都是分离式的,即先利用GAN生成数据,然后训练所有的数据。而文中提出一个统一框架将生成模型合并到特征学习模型中,端到端训练在线利用生成的数据训练。所提出的生成器模型将每个行人图分解成appearance部分和structure部分。判别器和生成器共享appearance部分。通过转换appearance和structure部分,可以是生成器生成高质量交叉id的图像,然后输入到appearance编码器取提升判别器。
下图是appearance和structure组合:

appearance和structure主要负责编码的内容:
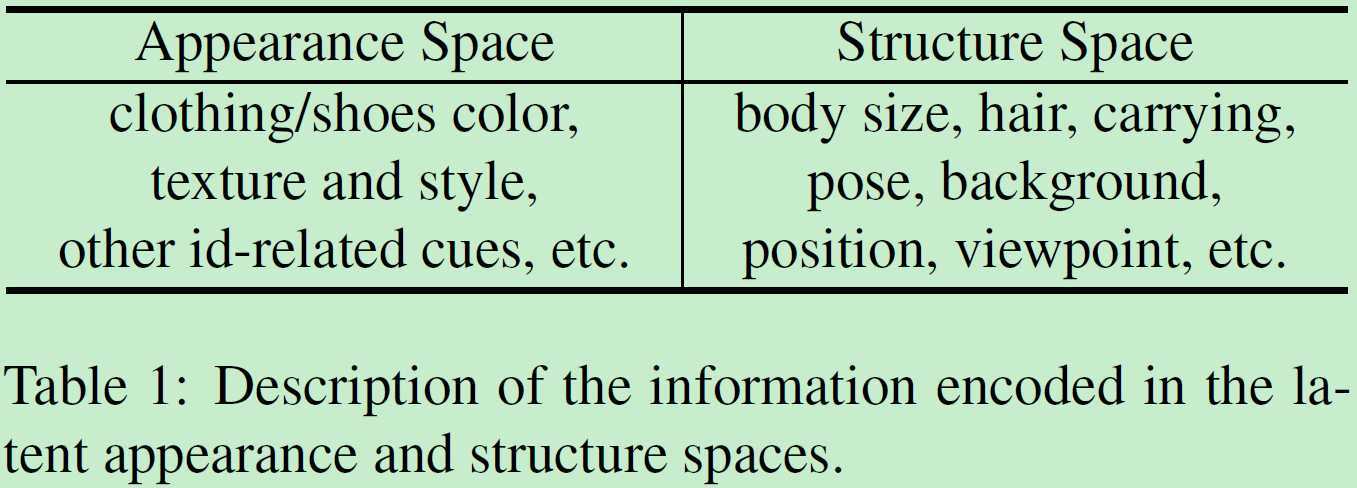
即appearance负责外表和其他和id身份有关的信息,structure负责几何位置信息。所有模块是联合训练,在线生成的图片在线利用。是首个端到端嵌入判别器和生成器在同一框架的reid结构。整体结构如图:
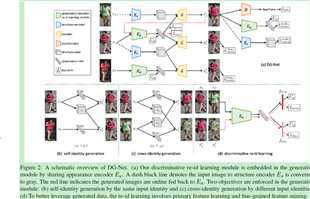
文中生成器负责图像生成,判别器用于reid学习。生成器包括两种图像映射:同一id映射和跨id映射。判别器包括特征学习和细粒度学习特征挖掘。一个个人觉得比较重要的点:由于在生成一张图时需要一个appearance编码和一个structure编码,所以有可能会在学习过程中网络只利用structure的信息而忽略了appearance的信息,所以为了避免这种平凡解,在利用structure时,将图像转换为灰度图,这样迫使网络必须也从appearance中学习。
损失极其多。第一个loss是同等映射。就是由图A生成图A,即要保证生成器的重构能力。第二个loss是交叉重构。即对于同一id的不同图片进行重构,这个loss鼓励appearance编码器将同一id的appearance拉近。来减少特征类内方差。同时第三个loss是分类损失,保证所有同一appearance的不同图像属于同一类。前三个loss针对同一id,接下类三个loss都是针对跨id。第四个loss约束相同appearance的两个不同id的appearance相近。第五个loss约束相同structure的两个不同id的structure相近。由于appearance决定了id,所以第六个loss也是分类损失·,所有生成的appearance相同的图像都应属于一类。第七个loss为对抗损失,就是生成器和判别器的损失。
Joint Discriminative and Generative Learning for Person Re-identification
原文:https://www.cnblogs.com/king-lps/p/12583712.html