
python3中有bytes和string类型: bytes主要是给在计算机看的,string主要是给人看的 中间有个桥梁就是编码规则,现在大趋势是utf8 bytes对象是二进制,很容易转换成16进制,例如\x64 string就是我们看到的内容,例如’abc’ string经过编码encode,转化成二进制对象,给计算机识别, 也就是bytes类型 bytes经过反编码decode,转化成string,但是注意反编码的编码规则是有范围,\xc8就不是utf8识别的范围
>>> ‘€20‘.encode(‘utf-8‘) b‘\xe2\x82\xac20‘ # bytes对象,二进制 >>> b‘\xe2\x82\xac20‘.decode(‘utf-8‘) ‘€20‘ >>>‘hello‘.encode(‘utf-8‘) b‘hello‘ >>>b‘hello‘.decode(‘utf-8‘) ‘hello‘
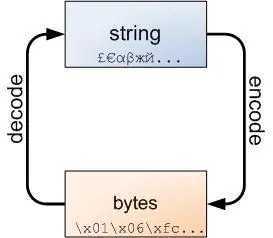
字符串(string)由字符组成,字符也是抽象的实体且与任何二进制表示无关。
当操纵字符串的时候,很多细节是不用了解的。我们可以分割、切片和拼接字符串,在字符串内部进行搜索。但并不在乎内部是如何表示的,也不用在意底层一个字符要花费多少byte。
只有在需要将string编码(encode)成byte的时候,比如:通过网络传输数据;或者需要将byte解码(decode)成string的时候,我们才会关注string和byte的区别。
s = ‘你是谁‘ # 编码 # 得出的 a 的结果就是对应的字节 a = bytes(s,‘utf-8‘) print(a) # 该命令将字符串转换为字节形式 b = s.encode(‘utf-8‘) print(b) # 下面是解码 # 将字节包转换成字符串 c = b‘\xe4\xbd\xa0\xe6\x98\xaf\xe8\xb0\x81‘ print(c.decode())
如果对python测试开发相关技术感兴趣的伙伴,欢迎加入测试开发学习交流QQ群:696400122,不积跬步,无以至千里。
原文:https://www.cnblogs.com/liudinglong/p/12588019.html