数据库表的索引从数据存储方式上可以分为聚簇索引和非聚簇索引(又叫二级索引)两种。Innodb的聚簇索引在同一个B-Tree中保存了索引列和具体的数据,在聚簇索引中,实际的数据保存在叶子页中,中间的节点页保存指向下一层页面的指针。“聚簇”的意思是数据行被按照一定顺序一个个紧密地排列在一起存储。一个表只能有一个聚簇索引,因为在一个表中数据的存放方式只有一种。
一般来说,将通过主键作为聚簇索引的索引列,也就是通过主键聚集数据。下图展示了Innodb中聚簇索引的结构(图片来自《高性能MySQL(第三版)》):
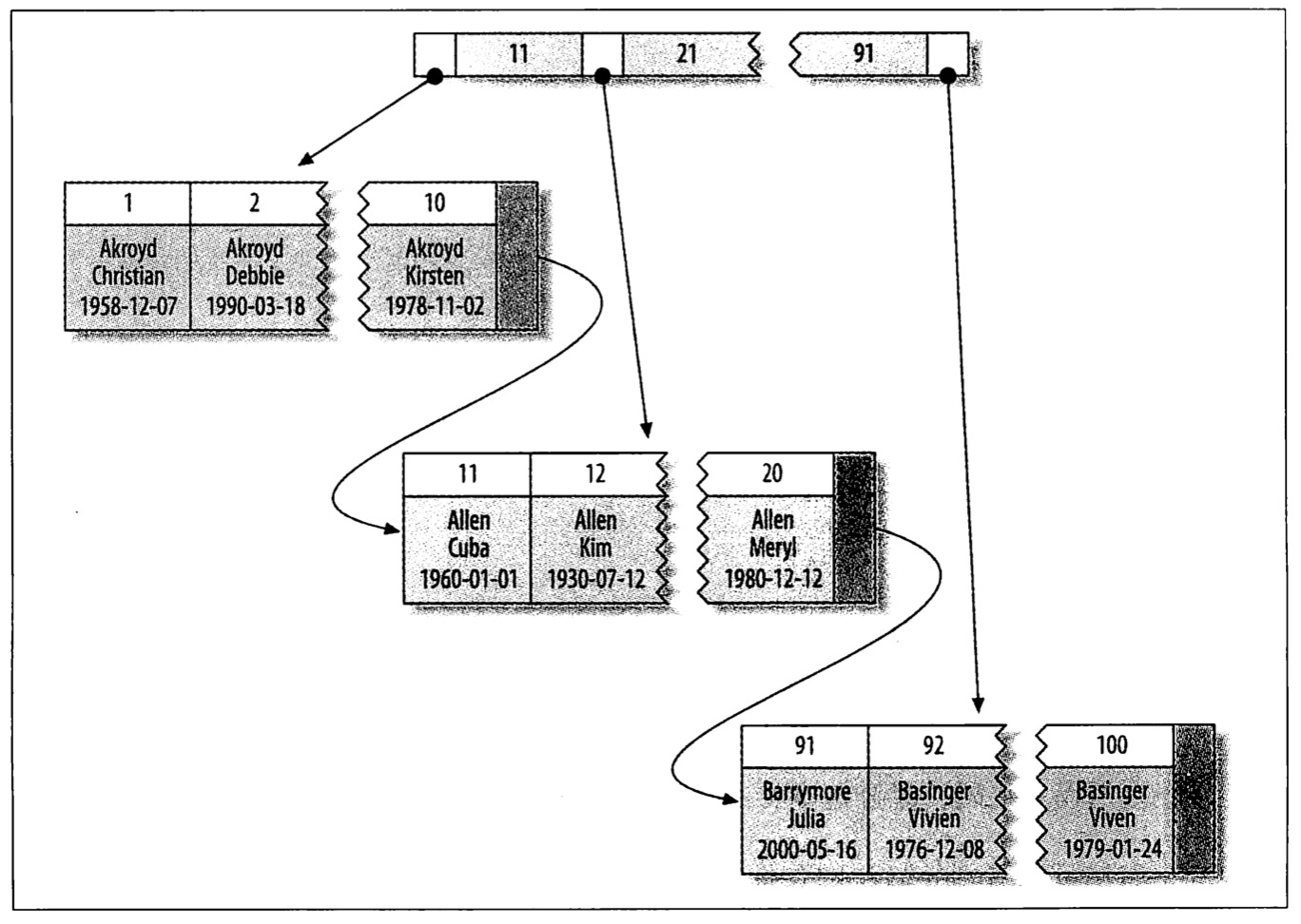
聚簇索引的结构
这里要特别注意页的概念,一个页可以理解为一块具有一定大小的连续的存储区域。相同页内的数据行在物理上是相邻的,因此逻辑上键值相邻的页在物理上可能相隔很远。
在中间的某个节点页中,主键<11的叶子页和11<主键<21的叶子页分别被两个指针所指向,且主键<11的叶子页也有一个指针指向了11<主键<21的叶子页,其余页之间的关系也是一样。
OPTIMIZE TABLE命令重新组织一下表。非聚簇索引,又叫二级索引。二级索引的叶子节点中保存的不是指向行的物理指针,而是行的主键值。当通过二级索引查找行,存储引擎需要在二级索引中找到相应的叶子节点,获得行的主键值,然后使用主键去聚簇索引中查找数据行,这需要两次B-Tree查找。
下面是Innodb聚簇索引和非聚簇索引的示意图(图片来自《高性能MySQL(第三版)》:
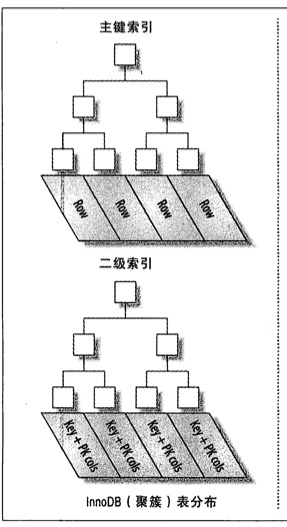
Innodb聚簇索引和非聚簇索引
原文:https://www.cnblogs.com/zhuyeshen/p/12588818.html