关系抽取的模型示意图,如图所示:
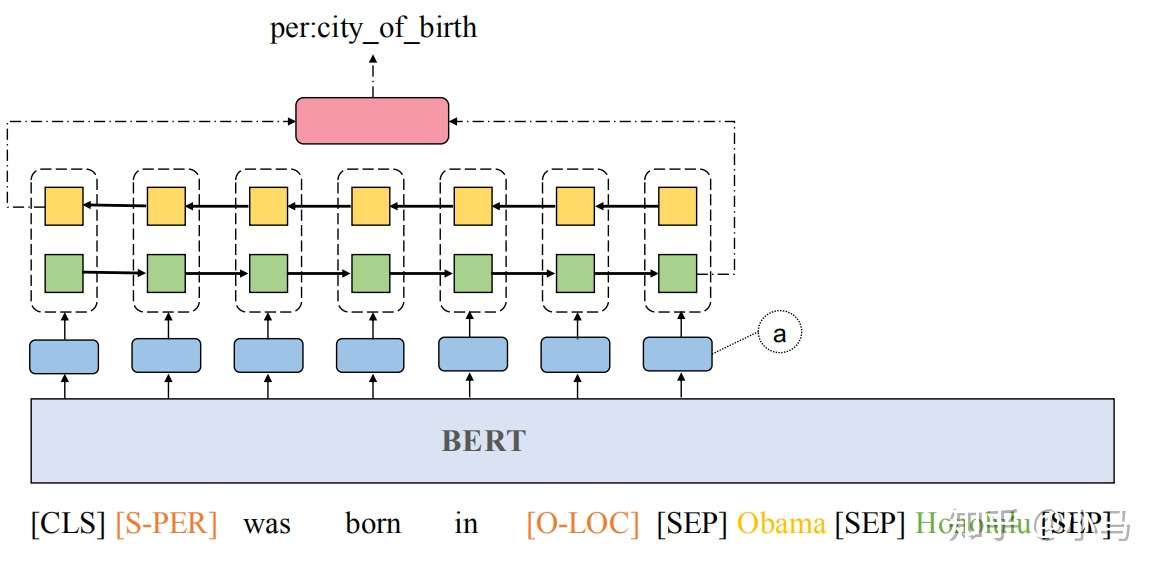
输入句子的构成为: [[CLS] sentence [SEP] subject [SEP] object [SEP]]
为了防止过拟合,对句子中的主语实体和宾语实体使用特殊的token进行mask,比如说[S-PER]表示代表人的主语实体。将经过Mask后的句子经WordPiece分词器分词后,输入给Bert的编码器
使用表示[[CLS] sentence [SEP]]之间词汇经Bert得到的向量表示,这里的
并不一定是句子的长度,因为分词器可能会把单词分成几个子单词
使用表示主语实体的向量
使用表示宾语实体的向量
定义相对于主语实体的位置序列为:
式中,和
分别为主语实体的开始和结束位置,
表示了和主语实体的相关位置
同样地,定于宾语实体的位置序列为
将位置序列转换为位置向量,和Bert的表示向量进行拼接,如图中(a)所示
然后将向量序列输入给一个Bi-LSTM,获取每个方向上的最后一个隐含层状态
输入给一个单隐含层的神经网络进行关系预测
语义角色标注的模型示意图,如图所示:
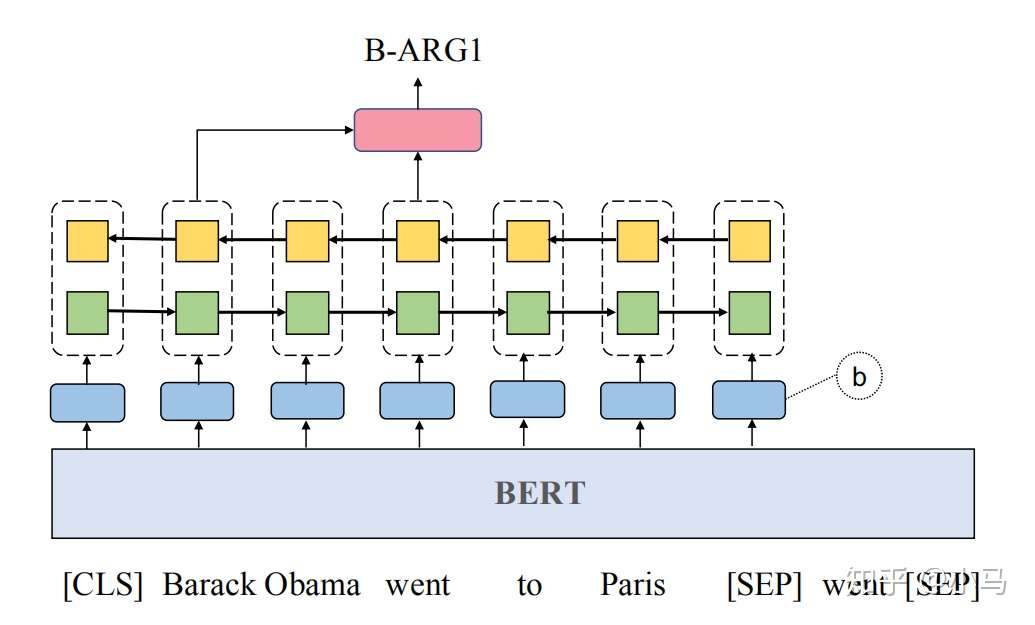
将这个任务当做序列标注进行处理,句子经WordPiece分词器分词后,任何单词的第一个token标注为O,其余的token标注为X。经Bert后的向量表示为,和谓词指示器嵌入进行拼接,后经单隐含层的神经网络进行分类预测
模型结构如上图所示,输入序列为 [[CLS] sentence [SEP] predicate [SEP]],经Bert后得到表示向量和指示器嵌入进行拼接,经过单层的Bi-LSTM后得到序列各个单词的隐含层表示为,对于预测词的表示向量
,和每一个token的表示向量
继续拼接,输入给单隐含层的神经网络进行分类预测
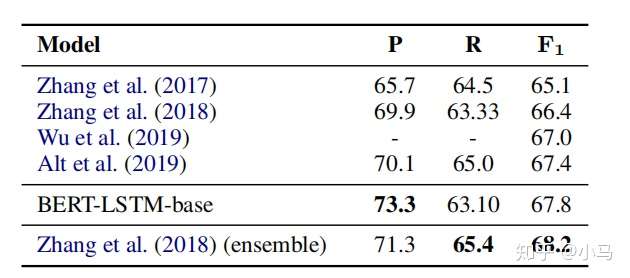
关系抽取模型在TACRED数据集上和不同模型的指标对比如图所示:
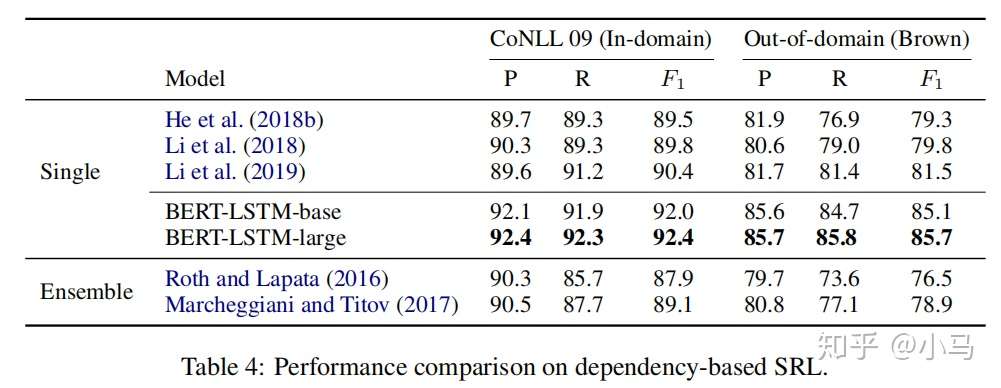
语义角色标注模型在CoNLL 2009和out-of-domain数据集上和不同模型的指标对比如图所示:
原文:https://www.cnblogs.com/chenyusheng0803/p/12592775.html