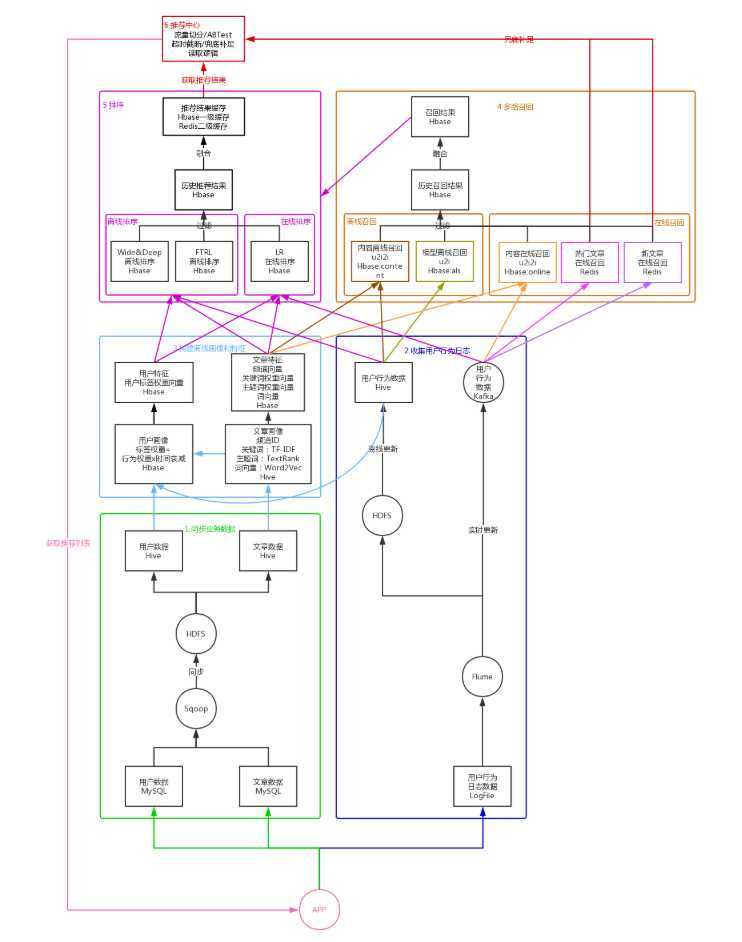
架构图
要点
1. 推荐流程设计
解决信息过载问题
召回
- 协同过滤召回
- 内容相似召回
- 热门召回
- 新物品召回
- 等等
排序
- LR
- GBDT/XGB/LGB
- DNN
- Wide&Deep
调整
2. 同步业务数据
为避免推荐系统的数据读写、计算对业务系统的影响,推荐系统的数据库和业务系统的数据库通常是分离的。
graph LR
用户数据&物品数据-Mysql-->HDFS-Hive
crontab 定时更新
3. 收集用户行为数据
业务系统-->日志数据-->Flume监听-->Kafka用于离线计算
-->HDFS-Hive用于在线计算
4. 构建离线文章画像
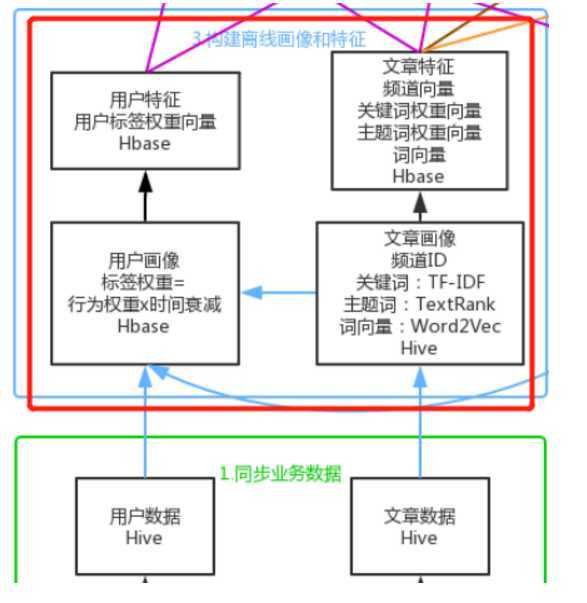
5. 计算文章相似度
5.1 构建文章画像
- TF-IDF 获取文章关键词
- Word2Vector 分领域计算文章词向量
- TextRank 获取文章主题词
- 利用关键词、主题词、词向量构建文章画像
5.2. 计算文章相似度
- BisectingKMeans 二分K均值算法的层次聚类
- 局部敏感哈希 LSH
- 计算文章间相似度并保存HBase
- 定时更新
6. 构建离线用户画像
6.1. Hive用户行为数据处理
6.2. 根据用户产生行为的文章的主题词按照不同的权重及时间衰减计算用户画像,存储Hbase。
6.3. 定时更新
7. 构建离线文章特征和用户特征
7.1. 根据关键词及其权重、主题词、文章频道、文章向量等文章画像构造特征
7.2. 根据用户信息表中信息及6中构建的用户画像构建用户特征
7.3. 定时更新
8. 基于模型的离线召回:ALS
8.1. 利用交替最小二乘法(ALS)将用户-物品矩阵做矩阵分解,分别得出用户矩阵和物品矩阵。
8.2. 根据用户矩阵和物品矩阵,可计算指定用户对所有物品的感兴得分。
8.3. 根据8.2中的兴趣得分进行排序获得召回集,将召回结果存储于Hbase。
8.4. 定时更新
9. 基于内容的离线及在线召回
9.1. 离线召回
- 根据用户历史行为中点击过得文章,再结合文章相似度推荐相似文章。
9.2. 在线召回
- Kafka 获取用户即时行为数据,根据用户当前阅读的文章推荐相似文章。
10. 基于热门文章和新文章的在线召回
- 根据点击次数统计热门文章,根据发布时间统计新文章
- 当推荐文章不足时,可用热门文章与新文章补充。数据量较小时,可Redis存储。
- 结合Kafka的用户当前行为,为用户推荐其感兴趣的热门文章和在线文章
11. 基于 LR 模型的离线排序
11.1. 离线模型的评估
推荐系统CTR模型评估
- 评分准确率:均方根误差RMSE,评估预测评分的效果。
- 排序能力:AUC,即ROC曲线下方的面积。
- 分类准确率:Precision,在top k 推荐列表中,用户真实点击的物品所占比例。
推荐系统广度评估指标
- 覆盖率:被有效推荐的用户占全网用户的比例
- 失效率:被无效推荐的用户占全网用户的比例
- 更新率:当期推荐列表与上期推荐列表相比,不同的物品所占的比例
推荐系统健康评估指标
- 个性化:衡量推荐的个性化程度,是否大部分用户只消费了小部分物品。可计算所有用户推荐列表的平均相似度。
11.2. LR模型
- 以用户特征、文章特征,用户行为数据中的点击数据为标签构造数据集,按不同场景划分数据集。比如,在第T天,T-6到T-3天为训练集,第T-2天为验证集,第T-1天为测试集,以AUC作为评估指标,模型日更。
12. 基于 FTRL 的在线排序
13. 基于 Wide&Deep Model 的在线排序
模型结构
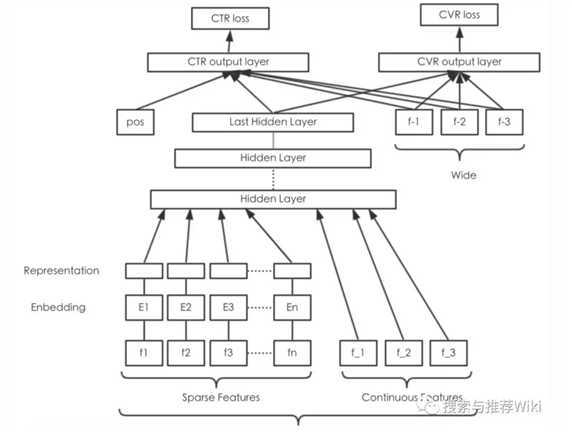
Wide
- 以类别特征和离散化的数值特征为输入
- 使用FTRL+L1进行训练
Deep
- 输入包括数值特征和Embedding后的类别特征,将得到的稠密特征输入Deep模型中。
- 使用Adagrad进行训练
14. 推荐中心
14.1. 推荐接口设计
- 推荐请求接口
- 行为埋点接口
- 接口需要支持灵活的 ABtest
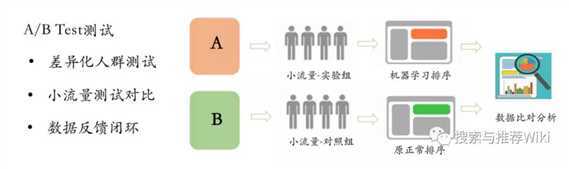
14.2. ABtest 流量切分
- 可将用户ID进行分桶,不同的桶对应不同的策略。也可以按照随机策略对每个请求按照指定分布使用随机的推荐策略,前提是保存时每个请求添加“策略名称”这个key以示区分。
- 通常 ATtest 过程
14.3. 推荐中心逻辑
- 接收业务系统发送的推荐请求
- 进行 ABtest 分流,为用户分配推荐策略
- 根据分配的算法调用召回服务和排序服务,读取推荐结果
- 根据业务进行调整,过滤、补足、合并信息等。
- 封装埋点参数,返回推荐结果。
参考
1、系列文章地址
《文章推荐系统》系列文章笔记
原文:https://www.cnblogs.com/Fosen/p/12609404.html