? Spark Streaming 是对Spark-core API 的一个扩展,它能够实现对实时数据流的流式处理,并具有很好的可扩展性、高吞吐量和容错性。
? Spark Streaming支持多种数据输入和输出:

import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FileWordCount {
def main(args: Array[String]): Unit = {
//创建一个sparkconf对象,其中local[2]表示任务运行在本地且需要两个CUP
val sparkconf = new SparkConf().setMaster("local[2]").setAppName("FileWordCount")
//创建StreamingContext对象,rdd批次处理间隔设为1秒
val ssc = new StreamingContext(sparkconf,Seconds(5))
//从hdfs中读取文件,生成DStream
val lines = ssc.textFileStream("file:///usr/local/data/test")
//用空格分割单词并计数
val res = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res.print()
//启动spark streaming
ssc.start()
//等待直到任务停止
ssc.awaitTermination()
}
}
上面的WordCount和spark-core中的WordCount在关键代码上几乎一致,从中不难想象出spark streaming其实是用rdd来处理的。事实上也是如此:
? 对于流式输入的数据流(spark streaming中叫做DSteam),spark streaming接收实时输入数据流并将数据划分为一个个小的批次供 Spark Engine 处理,最终生成多个批次的结果流。
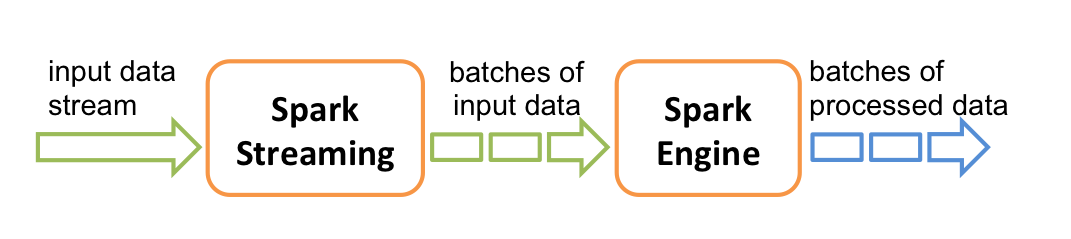
(1)StreamingContext
StreamingContext是spark streaming程序的入口,每一个spark streaming程序都要使用这个对象进行初始化。
StreamingContext有2种构造函数,分别为
其中batch interval表示sparkstreaming接受的每一批DStream之间的时间间隔,一般用Seconds类表示
(2)DStream
离散数据流(DStream)是 Spark Streaming 最基本的抽象。它代表了一种连续的数据流,要么从某种数据源提取数据,要么从其他数据流映射转换而来。DStream 内部是由一系列连续的RDD组成。
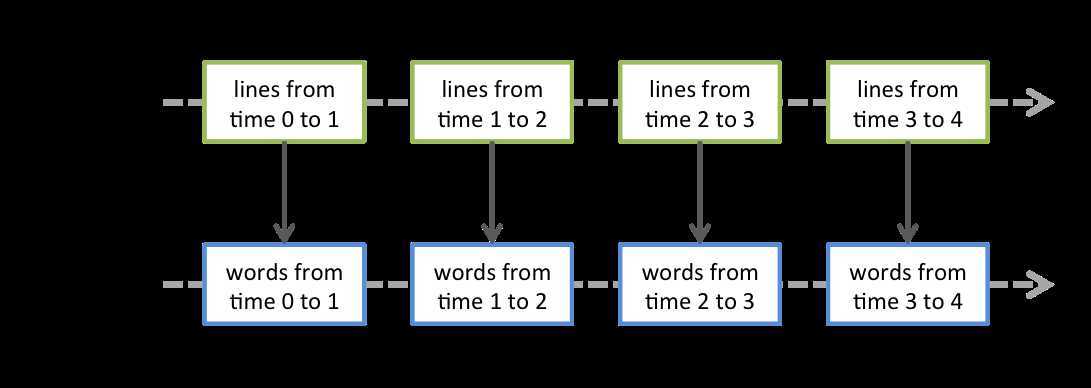
在上面的WordCount程序中,读取hdfs上的文件生成DStream ,将 lines 这个 DStream 转成 words DStream 对象,其实作用于 lines 上的 flatMap 算子,会施加于 lines 中的每个 RDD 上,并生成新的对应的 RDD,而这些新生成的 RDD 对象就组成了 words 这个 DStream 对象。其过程如下图所示:
原文:https://www.cnblogs.com/xyzlovehadoop/p/12612436.html