哈希冲突最常用的解决办法有开放定址法和链地址
1、开放定址法
就是当产生冲突时,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。

2、链地址法
上面所说的开发定址法的原理是遇到冲突的时候查找顺着原来哈希地址查找下一个空闲地址然后插入,但是也有一个问题就是如果空间不足,那他无法
处理冲突也无法插入数据,
因此需要装填因子(插入数据/空间)<=1。
那有没有一种方法可以解决这种问题呢?链地址法可以,链地址法的原理时如果遇到冲突,他就会在原地址新建一个空间,然后以链表结点的形式插入
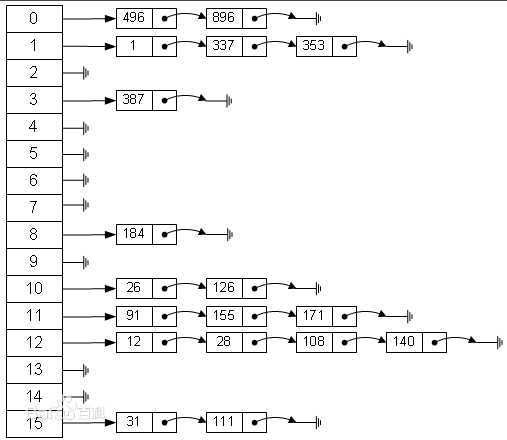
到该空间。我感觉业界上用的最多的就是链地址法。下面从百度上截取来一张图片,可以很清晰明了反应下面的结构。比如说我有一堆数据
{1,12,26,337,353...},而我的哈希算法是H(key)=key mod 16,第一个数据1的哈希值f(1)=1,插入到1结点的后面,第二个数据12的哈希值f(12)=12,插
入到12结点,第三个数据26的哈希值f(26)=10,插入到10结点后面,第4个数据337,计算得到哈希值是1,遇到冲突,但是依然只需要找到该1结点的最
后链结点插入即可,同理353。
C语言实现代码
#include<iostream> #include<stdlib.h> #include<string.h> #define HashSize 10 //哈希表结点个数 using namespace std; struct node//定义一个节点 { char *key; char *val; node* next; }; struct HashTable//定义一个哈希表 { node* head; }Table[HashSize]; //初始化哈希表 void HashTable_Init()//哈希表初始化 { for(size_t i=0;i<HashSize;i++) Table[i].head=NULL; } //哈希函数(开放寻址) size_t Hash(char* key) { size_t ans=0; for(;*key;key++) ans=ans*33+*key; return ans%HashSize; } //查找键是否已经存在 node* find(char* key) { node* New; size_t index; index=Hash(key); New=Table[index].head; while(New!=NULL) { if(!strcmp(key,New->key)) return New; New=New->next; } return NULL; } //插入结点建立映射关系 void insert(char* key,char* val) { node* New=find(key); //不存在就插入节点 if(New==NULL) { size_t index=Hash(key); New=(node*)malloc(sizeof(node)); New->key=key; //链表的头插法,Table[index]是头指针 New->next=Table[index].head; //头指针前移 Table[index].head=New; } //如果键已经被映射过,直接改变对应的值即可 New->val=val; } void Print() { for(size_t i=0;i<HashSize;i++) { cout<<"index="<<i<<" "; if(Table[i].head==NULL) cout<<"[][]"<<endl; else { node* now=Table[i].head; while(now!=NULL) { cout<<"["<<now->key<<"]"<<"["<<now->val<<"]"<<" "; now=now->next; } cout<<endl; } } } int main() { HashTable_Init(); char key[5][100], val[5][100]; for (size_t i = 0; i < 5; i++) { cin >> key[i]; cin >> val[i]; insert(key[i], val[i]); } Print(); return 0; }
原文:https://www.cnblogs.com/-citywall123/p/12616848.html