# 主机列表
10.2.2.137 master1
10.2.2.166 master2
10.2.2.96 master3
10.2.3.27 node0
# 软件版本
docker version:18.09.9
k8s version:v1.16.4
本文采用kubeadm方式搭建集群,通过keepalived的vip策略实现高可用,架构图如下:
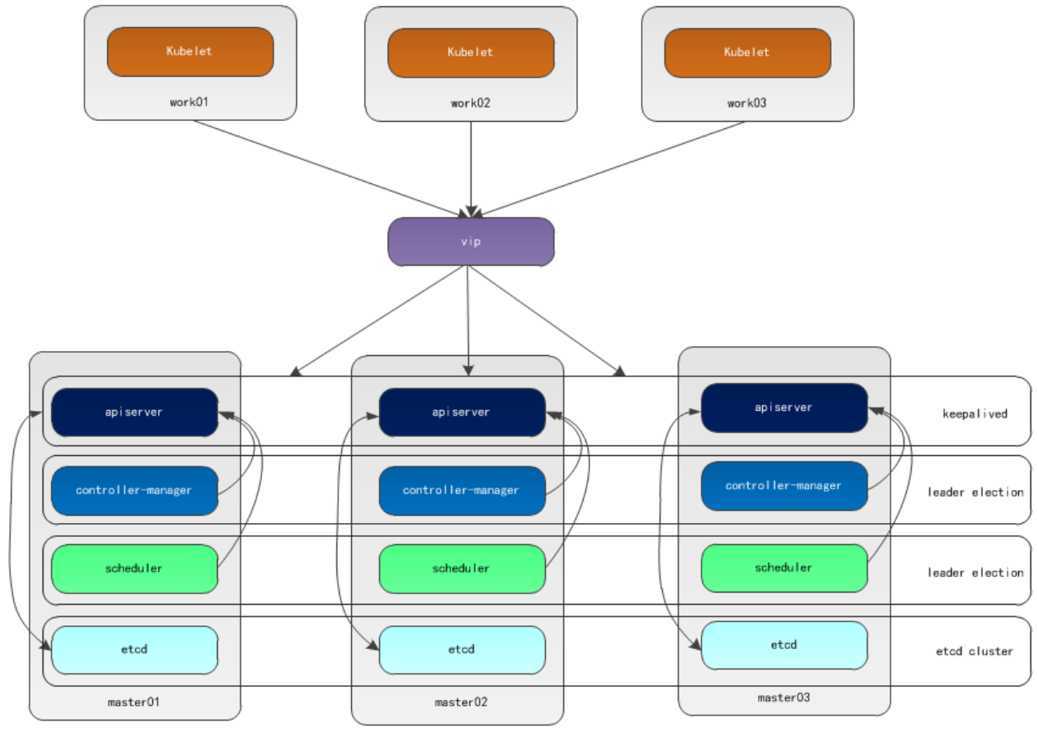
# 主备模式高可用架构说明

a)apiserver通过keepalived实现高可用,当某个节点故障时触发vip转移;
b)controller-manager和scheduler在k8s内容通过选举方式产生领导者(由leader-elect选型控制,默认为true),同一时刻集群内只有一个scheduler组件运行;
c)etcd在kubeadm方式实现集群时,其在master节点会自动创建etcd集群,来实现高可用,部署的节点为奇数,3节点方式最多容忍一台机器宕机。
一般情况下,k8s集群中只有一台master和多台node,当master故障时,引发的事故后果可想而知。
故本文目的在于体现集群的高可用,即当集群中的一台master宕机后,k8s集群通过vip的转移,又会有新的节点被选举为集群的master,并保持集群的正常运作。
因本文体现的是master节点的高可用,为了实现效果,同时因资源条件限制,故总共采用4台服务器完成本次实验,3台master,1台node。
看到这也需有人有疑惑,总共有4台机器的资源,为啥不能2台master呢?这是因为通过kubeadm部署的集群,当中的etcd集群默认部署在master节点上,3节点方式最多能容忍1台服务器宕机。如果是2台master,当中1台宕机了,直接导致etcd集群故障,以至于k8s集群异常,这些基础环境都over了,vip漂移等高可用也就在白瞎。
1、大多数文章都是一步步写命令写步骤,而对于有部署经验的人来说觉得繁琐化了,故本文大部分服务器shell命令操作都将集成到脚本;
2、本文相关shell脚本地址: https://gitee.com/kazihuo/k8s-install-shell
3、所有要加入到k8s集群的机器都执行本部分操作。
a)将所有服务器修改成对应的主机名,master1示例如下;
# hostnamectl set-hostname master1 #重新登录后显示新设置的主机名
b)配置master1到master2、master3免密登录,本步骤只在master1上执行;
[root@master1 ~]# ssh-keygen -t rsa # 一路回车
[root@master1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.2.2.166
[root@master1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.2.2.96
c)脚本实现环境需求配置;
# sh set-prenv.sh
# cat set-prenv.sh
 set-prenv.sh
set-prenv.sh说明:所有节点都执行本部分操作!
# sh install-docker.sh
Centos7部署k8s[v1.16]高可用[keepalived]集群
原文:https://www.cnblogs.com/kazihuo/p/12619719.html