模型评估包括评估方法(evaluation)和评价指标(metrics)。评估方法包括留出法,交叉验证,包外估计等。本文只介绍评价指标。
评价指标的两个作用:一是了解模型的泛化能力,可以通过同一个指标来对比不同模型,从而知道哪个模型相对好,那个模型相对差;二是可以通过这个指标来逐步优化我们的模型。
对于分类和回归两类监督学习,分别有各自的评判标准。本篇主要讨论与分类相关的一些指标,包括混淆矩阵、准确率、(宏/微)查准率、查全率、F1指数、PR曲线、ROC曲线/AUC。其中4个单一指标比较简单,重点说下混淆矩阵、PR曲线和ROC曲线。
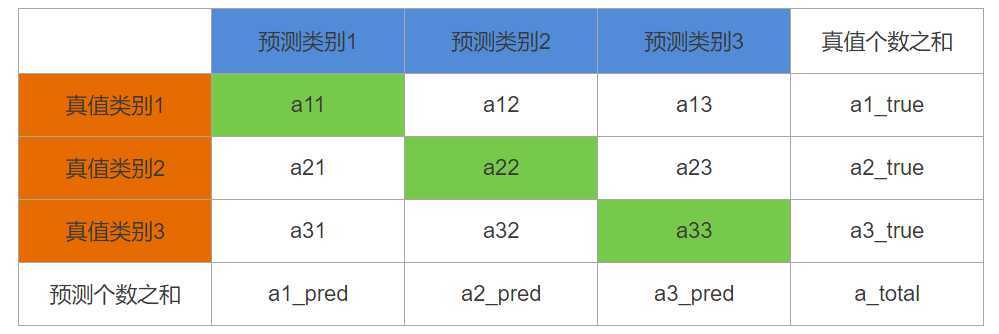
混淆矩阵:假设有三个类别需要分类,现在训练了一个分类模型,对验证集的预测结果列成表格,每一行是真正的类别,每一列是预测的类别,这个列表矩阵即为混淆矩阵。如下所示,混淆矩阵中土黄色表示真实类别,蓝色表示预测类别,那么对角线上绿色值就表示预测正确的个数,某个绿色值除以当前行之和就是该类别的查全率(recall),除以当前列之和就是该类别的查准率(precision),对角线之和除以总和就是全局准确率(accuracy)。比如现在的分类器,它的accuracy为(a11+a22+a33)/a_total,它对类别1的查全率为a11/a1_true,查准率为a11/a1_pred。混淆矩阵的优势在于囊括了下面几种单一指标,各种类别的信息一目了然。
准确率(accuracy):最原始的评价指标,将正负样本统一看待,只要预测正确就算数,\(\frac{TP+TN}{P+N}\)。虽然准确率可以判断总的正确率,但是在样本不平衡的情况下,导致了得到的高准确率结果含有很大的水分。因此衍生出了其它两种指标:查准率和查全率。
查准率(precision):预测为正的样本里面,真的正样本所占比例,\(\frac{TP}{TP+FP}\)。
查全率(recall,也称召回率):所有正样本里面检测出来的比例,\(\frac{TP}{TP+FN}\)。
查准率和查全率都依赖于阈值的选取。以逻辑回归为例,预测概率值大于某个阈值则判定为正样本,小于该阈值则判定为负样本。但问题是:这个阈值是我们随便定义的,我们并不知道这个阈值是否符合我们的要求。因此,为了更进一步了解模型的性能,我们希望遍历 0 到 1 之间所有的阈值,看看在各个阈值下的查准率和查全率。
PR曲线的绘制:首先拿到分类器对于每个样本预测为正例的概率,根据概率对所有样本进行逆序排列,然后将分类阈值设为最大,即把所有样本均预测为反例,然后依次放出一个样本作为正例,分别画出precision和recall。以precision作为纵轴,recall作为横轴,将所有点连起来即得到PR曲线。
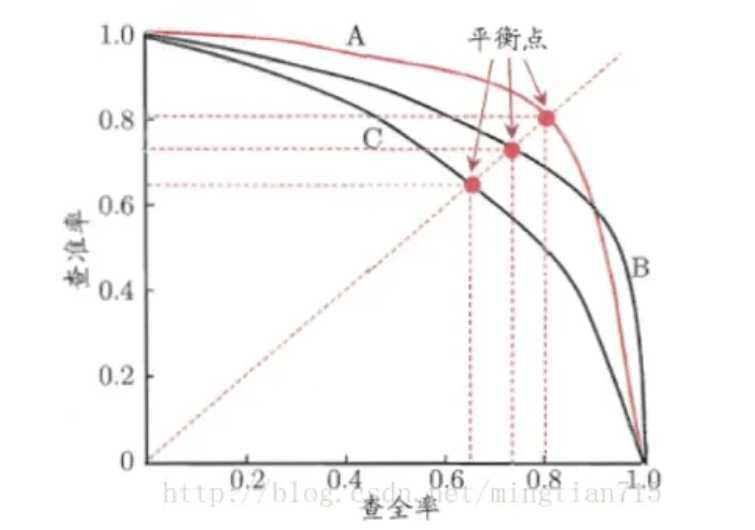
PR曲线的含义:
查准率和查全率是一对矛盾体,一个指标增加时,另一个往往就减少。当比较两个模型的优劣时,PR曲线往往会相交,因此为了直观看出哪个模型更好,就需要一个综合考虑两者的数值,这个值就是F1值。
F1指数:查准率和查全率的几何平均值的2倍,即\(\frac{2}{\frac{1}{P}+\frac{1}{R}}\)。如果希望F1值高,则需要两者都比较高且均衡。
ROC曲线的横轴是假正例率\(\frac{FP}{所有负样本}\),纵轴是真正例率\(\frac{TP}{所有正样本}\)(即召回率)。
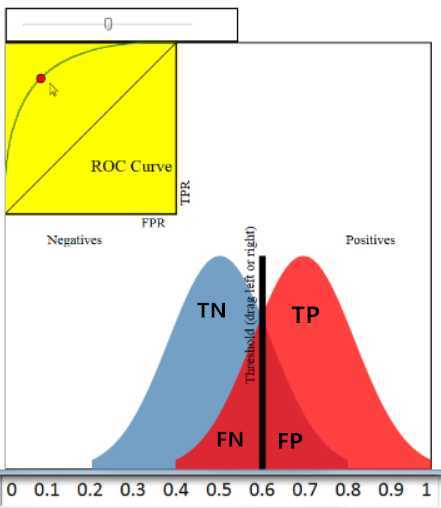
ROC曲线的绘制:和PR曲线的绘制过程类似,只不过是每次放出一个样本作为正例时,分别画出真正例率和假正例率。以真正例率作为纵轴,假正例率作为横轴,将所有点连起来即得到ROC曲线。曲线越靠近左上角,意味着越多的正例优先于负例,模型的整体表现也就越好。
那么问题来了:为啥有了混淆矩阵和PR曲线,还要ROC?这里解释ROC的两大厉害之处。
厉害之处1:AUC(Area Under Curve)。这里的AUC是指ROC曲线下面积,根据这个值,可以大致判断模型的分类能力。我们知道,对于一个好的逻辑回归模型,它能把负样本的预测值压得很低(尽可能接近0),把正样本的预测值拉的很高(接近1),这样一来,我们只需要找到一个比较合适的阈值,就能很好的把正负样本分开。那对于现在已经训练好的逻辑回归模型,该如何知道它把样本分开的能力呢?就可以用ROC的AUC。
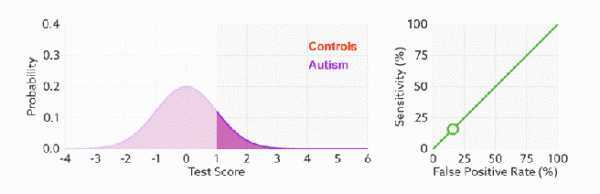
图中的两个正态分布表示两个类别的概率密度,模型越好,就能把两个类别分的越开。可以看出,模型把两个类别分的越开,对应的ROC曲线就越接近左上角,AUC就越大。最理想的情况是AUC等于1,最差的情况是AUC等于0.5(两个类别概率密度重合在一块了,即模型没能把两个类别分开)。所以一般 AUC 的值是介于 0.5 到 1 之间的。AUC 的一般判断标准:
注:资料中说,曲线下面积可以看作是模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。其实表达的就是,曲线下面积可以代表模型将正负样本分开的能力。
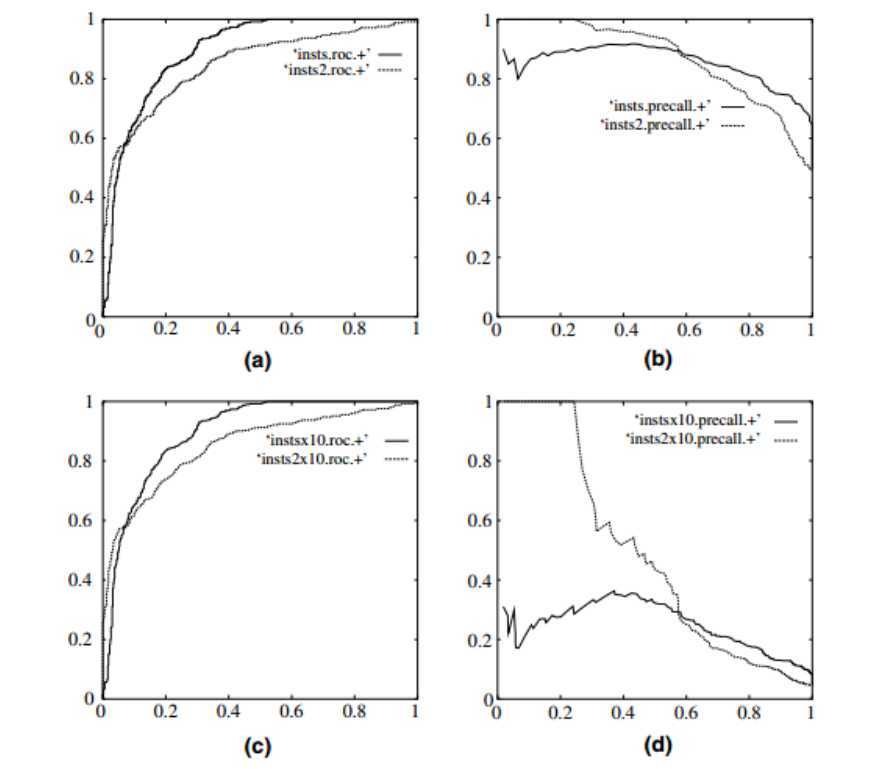
厉害之处2:对样本类别不平衡的问题不敏感。ROC曲线兼顾正例和负例的权衡。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。两个指标都不依赖于具体的类别分布。而PR曲线的两个指标查准率和查全率都聚焦于正例。当负样本数量突然增大时,ROC基本不变,但PR曲线变化很大。比如下图,参考文献中举了个例子,负例增加了10倍,ROC曲线没有改变,而PR曲线则变了很多。
precision和recall的应用场景:
PR曲线和ROC曲线应用场景:
Reference:
原文:https://www.cnblogs.com/inchbyinch/p/12622667.html