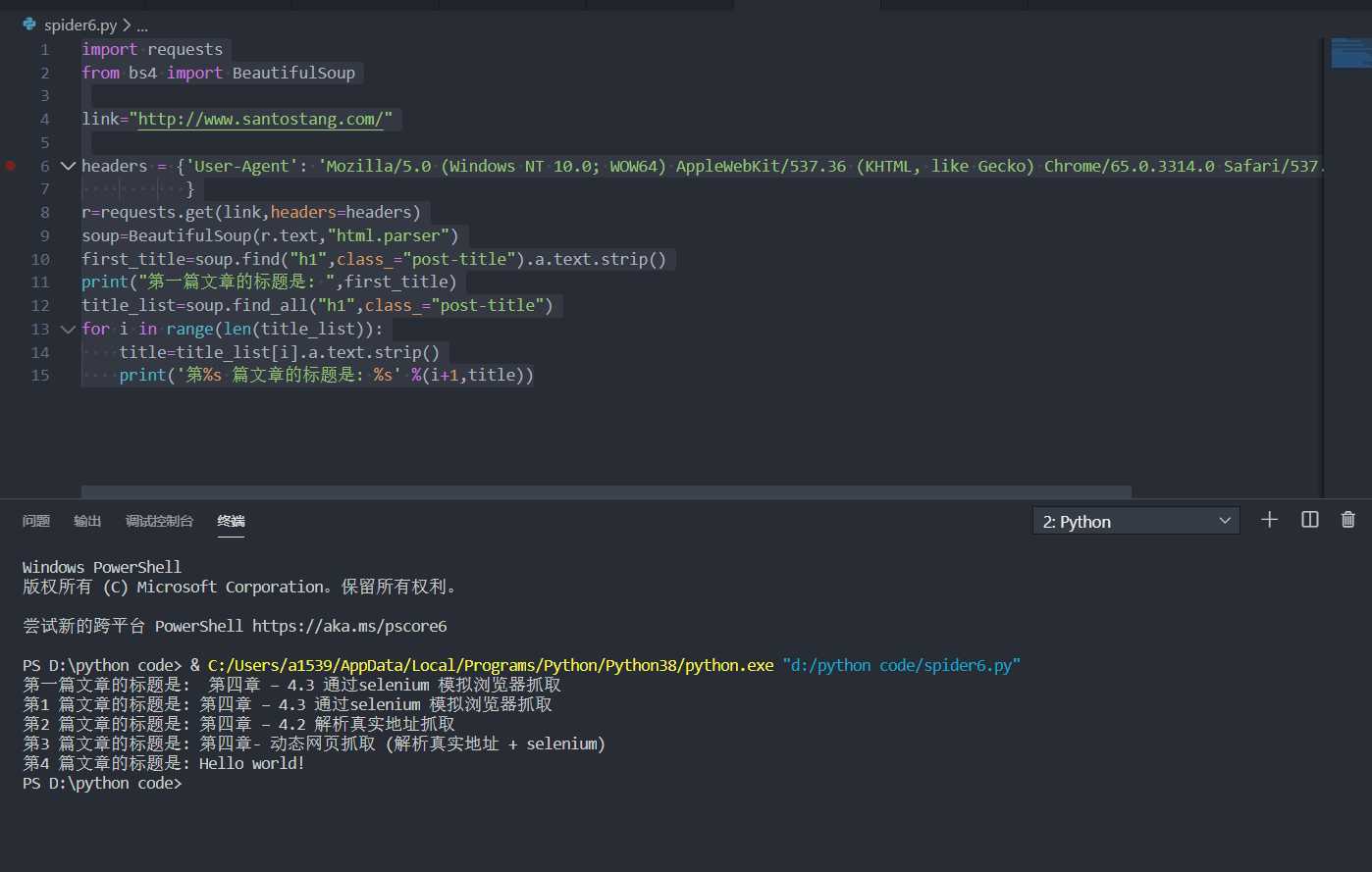
import requests
from bs4 import BeautifulSoup
link="http://www.santostang.com/"
headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0‘
}
r=requests.get(link,headers=headers)
soup=BeautifulSoup(r.text,"html.parser")
first_title=soup.find("h1",class_="post-title").a.text.strip()
print("第一篇文章的标题是: ",first_title)
title_list=soup.find_all("h1",class_="post-title")
for i in range(len(title_list)):
title=title_list[i].a.text.strip()
print(‘第%s 篇文章的标题是: %s‘ %(i+1,title))
原文:https://www.cnblogs.com/ahacker15/p/12622630.html