question:如何计算AUC?
answer:首先,AUC是指ROC曲线下的面积大小,该值能够量化地反映基于ROC曲线衡量出的模型性能。计算AUC值只需要沿着ROC横轴做积分就可以了。 由于ROC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的 概率反转成1−p就可以得到一个更好的分类器),所以AUC的取值一般在0.5~1之 间。AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
question:ROC曲线相比P-R(https://wordpress.aberttsy.cn/index.php/2020/04/01/machine-learning-3/)曲线有什么特点?
answer:相比 P-R曲线,ROC曲线有一个特点,当正负样本的分布发生变化时,ROC曲线的形状 能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。
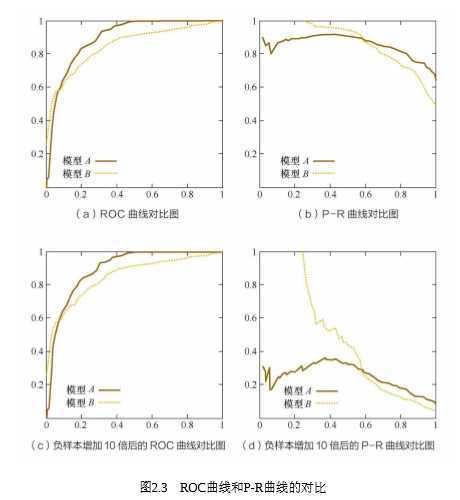
可以看出,P-R曲线发生了明显的变化,而ROC曲线形状基本不变。这个特点 让ROC曲线能够尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性 能。这有什么实际意义呢?在很多实际问题中,正负样本数量往往很不均衡。比 如,计算广告领域经常涉及转化率模型,正样本的数量往往是负样本数量的1/1000 甚至1/10000。若选择不同的测试集,P-R曲线的变化就会非常大,而ROC曲线则 能够更加稳定地反映模型本身的好坏。所以,ROC曲线的适用场景更多,被广泛 用于排序、推荐、广告等领域。但需要注意的是,选择P-R曲线还是ROC曲线是因 实际问题而异的,如果研究者希望更多地看到模型在特定数据集上的表现,P-R曲 线则能够更直观地反映其性能。
question:为什么一些场景中要使用余弦相似度而不是欧式距离?
answer:对于两个向量A和B,其余弦相似度定义为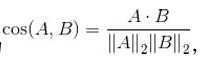 即两个向量 夹角的余弦,关注的是向量之间的角度关系,并不关心它们的绝对大小,其取值 范围是[−1,1]。当一对文本相似度的长度差距很大、但内容相近时,如果使用词频或词向量作为特征,它们在特征空间中的欧氏距离通常很大;而如果使用余弦相似度的话,它们之间的夹角可能很小,因而相似度高。此外,在文本、图像 、视频等领域,研究的对象的特征维度往往很高,余弦相似度在高维情况下依然保持“相同时为1,正交时为0,相反时为−1”的性质,而欧氏距离的数值则受维度的影响,范围不固定,并且含义也比较模糊。
即两个向量 夹角的余弦,关注的是向量之间的角度关系,并不关心它们的绝对大小,其取值 范围是[−1,1]。当一对文本相似度的长度差距很大、但内容相近时,如果使用词频或词向量作为特征,它们在特征空间中的欧氏距离通常很大;而如果使用余弦相似度的话,它们之间的夹角可能很小,因而相似度高。此外,在文本、图像 、视频等领域,研究的对象的特征维度往往很高,余弦相似度在高维情况下依然保持“相同时为1,正交时为0,相反时为−1”的性质,而欧氏距离的数值则受维度的影响,范围不固定,并且含义也比较模糊。
在一些场景,例如Word2Vec中,其向量的模长是经过归一化的,此时欧氏距 离与余弦距离有着单调的关系,即
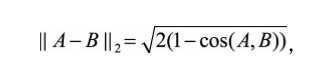
其中|| A−B ||2表示欧氏距离,cos(A,B)表示余弦相似度,(1−cos(A,B))表示余弦距 离。在此场景下,如果选择距离最小(相似度最大)的近邻,那么使用余弦相似 度和欧氏距离的结果是相同的。
总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对 差异。例如,统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为 (1,0);此时二者的余弦距离很大,而欧氏距离很小;我们分析两个用户对于不同 视频的偏好,更关注相对差异,显然应当使用余弦距离。而当我们分析用户活跃 度,以登陆次数(单位:次)和平均观看时长(单位:分钟)作为特征时,余弦距离会 认为(1,10)、(10,100)两个用户距离很近;但显然这两个用户活跃度是有着极大差异 的,此时我们更关注数值绝对差异,应当使用欧氏距离。
question:余弦距离是否是一个严格定义的距离?
answer:首先看距离的定义:在一个集合中,如果每一对元素均可唯一确定一个实数,使得三条 距离公理(正定性,对称性,三角不等式)成立,则该实数可称为这对元素之间 的距离。余弦距离满足正定性和对称性,但是不满足三角不等式,因此它并不是严格定义的距离。
question:在对模型进行过充分的离线评估之后,为什么还要进行在线A/B测试?
answer:
(1)离线评估无法完全消除模型过拟合的影响,因此,得出的离线评估结果 无法完全替代线上评估结果。
(2)离线评估无法完全还原线上的工程环境。一般来讲,离线评估往往不会 考虑线上环境的延迟、数据丢失、标签数据缺失等情况。因此,离线评估的结果 是理想工程环境下的结果。
(3)线上系统的某些商业指标在离线评估中无法计算。离线评估一般是针对 模型本身进行评估,而与模型相关的其他指标,特别是商业指标,往往无法直接 获得。比如,上线了新的推荐算法,离线评估往往关注的是ROC曲线、P-R曲线等 的改进,而线上评估可以全面了解该推荐算法带来的用户点击率、留存时长、PV 访问量等的变化。这些都要由A/B测试来进行全面的评估。
question:如何进行线上A/B测试?
answer:进行A/B测试的主要手段是进行用户分桶,即将用户分成实验组和对照组,对 实验组的用户施以新模型,对对照组的用户施以旧模型。在分桶的过程中,要注 意样本的独立性和采样方式的无偏性,确保同一个用户每次只能分到同一个桶 中,在分桶过程中所选取的user_id需要是一个随机数,这样才能保证桶中的样本 是无偏的。
question:如何划分实验组和对照组? (新开发了模型A,但是现有用户使用的是模型B,问怎么划分,能验证模型A)
answer:根据User_id划分为试验组和对照组,分别使用模型A,模型B,才能验证模型A的效果.
模型评估的方法
question:在模型评估过程中,有哪些主要的验证方法,说出优缺点。
answer:
(1) Holdout 检验是最简单也是最直接的验证方法,它将原始的样本集合随机划分 成训练集和验证集两部分。比方说,对于一个点击率预测模型,我们把样本按照 70%~30% 的比例分成两部分,70% 的样本用于模型训练;30% 的样本用于模型 验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能。 Holdout 检验的缺点很明显,即在验证集上计算出来的最后评估指标与原始分 组有很大关系。为了消除随机性,研究者们引入了“交叉检验”的思想。
(2) k-fold交叉验证:首先将全部样本划分成k个大小相等的样本子集;依次遍历 这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的 训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在实际实验 中,k经常取10。 留一验证:每次留下1个样本作为验证集,其余所有样本作为测试集。样本总数为n,依次对n个样本进行遍历,进行n次验证,再将评估指标求平均值得到最终 的评估指标。在样本总数较多的情况下,留一验证法的时间开销极大。事实上, 留一验证是留p验证的特例。留p验证是每次留下p个样本作为验证集,而从n个元 素中选择p个元素有 种可能,因此它的时间开销更是远远高于留一验证,故而很 少在实际工程中被应用。
补充:不管是Holdout检验还是交叉检验,都是基于划分训练集和测试集的方法进行 模型评估的。然而,当样本规模比较小时,将样本集进行划分会让训练集进一步 减小,这可能会影响模型训练效果。
(3) 自助法是基于自助采样法的检验方法。对于总数为n的样本集合,进行n次有 放回的随机抽样,得到大小为n的训练集。n次采样过程中,有的样本会被重复采 样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行模型验 证,这就是自助法的验证过程。
question: 在自助法的采样过程中,对n个样本进行n次自助抽样,当n趋于无穷大时, 最终有多少数据从未被选择过?
answer:

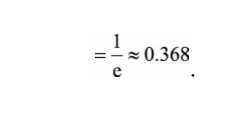
因此,当样本数很大时,大约有36.8%的样本从未被选择过,可作为验证集。
原文:https://www.cnblogs.com/tsy-0209/p/12629699.html